
TDDE10 Objektorienterad programmering i Java
Snabbguide OOP
- Att lära sig objektorientering
- Primitiva datatyper och referenser
- Vad är en instansvariabel?
- Hur kan en klass "använda sig själv"?
- Public, private eller protected?
- Static eller ej?
- Varför har hela mitt program blivit static?
- Parameteröverföring och returvärden i Java
- Parameter eller instansvariabel?
- Var är en "lämplig" konstruktor?
- Arv, det är väl bara larv, eller?
- Överskuggning
- Polymorfi, är det magi?
- Abstrakta klasser, varför?
- Vad är final?
- Vad innebär "lätt" i "lätt att ändra i koden"?
- Vad är ett interface?
- Checklista för en välgjord klass
- Måste jag skriva ett helt program bara för att testa något litet?
- Hur gör jag en generisk klass?
- Vad är ett "bra" testprogram?
Att lära sig objektorientering
I kursen utgår vi från att du som student är bekant med ett imperativt programmeringsspråk och har lärt dig grunderna för hur man löser ett problem. Man måste alltså kunna tillämpa de verktyg som ett imperativt programmeringsspråk tillhandahåller, d.v.s. typer, variabler, deklarationer, uttryck, styrsatser, underprogram, arrayer, poster, pekare, rekursion m.m.
Dessa kunskaper kommer man ha stor användning för i denna kurs, men det är inte det som är det nya stoffet i kursen. Kursen handlar om att lära sig ett nytt tänk för programmering, objektorientering.
I objektorientering är man i första hand intresserad av hur koden är organiserad och strukturerad så att man uppnår en "bra" miljö att jobba i. Det handlar om att få sitt program (eller mjukvara/system) att ha goda egenskaper, så som att vara lätt felsökningsbart, utökbart, lätt att underhålla m.m.
Detta kan vara mycket frustrerande om man har perspektivet "Vad är problemet?" och "hur löser vi det?", eftersom detta inte är i fokus. Ibland kanske inte ens finns något problem att lösa. Uppgiften kanske snarare är att modellera något, så att man i framtiden kan lägga till kod som uppnår något specifikt ändamål.
Det första man därför måste göra är att acceptera att man håller på att lära sig något nytt, och att man kan behöva tänka om. Det betyder inte att man helt skall radera allt man tidigare vetat om programmering! Men man måste vara beredd på att få sin världsbild ruckad något.
Därefter är det viktigt att man mycket tidigt bekantar sig med språket som man skall lära sig OOP i. I vårt fall java. Detta är inte svårt. Det är i princip bara att översätta de gamla kunskaperna till hur det ser ut i det nya språket. Om du tycker att det är jobbigt kan du ju göra en liten lathund med t.ex. hur if-satser, loopar m.m. ser ut, och ha den brevid dig när du jobbar i början.
Det som sedan följer är att man måste lära sig den teori som behandlar grundpelarna i OOP. Vi pratar då om klasser, objekt, konstruktorer, arv, polymorfi, inkapsling, och ansvar. Dessa begrepp måste man tampas med, och detta kanske inte är helt enkelt, men det släpper ju mer man övar på det. Ibland kanske det känns onödigt och dumt, man tänker kanske "varför spelar det så stor roll var jag lägger denna lilla kodsnutt? Det viktiga är väl att den funkar?". Men det är precis placering (d.v.s. vem som ansvarar) som är relevant i denna kurs, inte kanske vad just den kodsnutten utför för funktionalitet för användaren.
Slutligen finns det bara ett sätt som man kan bli bra på OOP. Att öva. Det är många saker som man bara lär sig efter att ha suttit på kammaren i många timmar och det kan ibland ta veckor (eller t.o.m. månader) innan man greppar något till fullo. Så är det dock med all kunskap som är värd att försöka tillskansa sig. Ett starkt tips är att lägga de timmar som krävs tidigt, och under kursens gång, där vi (kursens personal) kan vara med och stödja dig på din väg.
Primitiva datatyper och referenser
När man deklarerar en variabel i java så är det alltid av intresse huruvida typen är en primitiv eller om det är en klasstyp (referenstyp).Det är oftast inte svårt att avgöra eftersom primitiva datatyper har korta namn som börjar med liten bokstav. Vi har t.ex: int, double, float, char, boolean, long och några till. Det är datatyper för att representera de mest grundläggande data som vi har i våra program.
int x;Om man istället deklarerar en variabel av en klasstyp, vilket man lätt kan se på typnamnet om den har stor begynnande bokstav, så är detta istället inte som en vanlig variabel, det är bara en referens.
Animal a;En referens i java är ungefär som en pekare, vi kan tänka på dessa som samma sak. Vår a i exemplet ovan är alltså inte i sig ett objekt av typen animal utan bara en liten snutt minne som innehåller en minnesadress. Den adressen kan vara null, d.v.s. inte referera till något, och så är det också i början innan referenser sätts, eller referera till ett faktiskt objekt. För att a faktiskt skall vara kopplad till ett objekt så måste vi instansiera klassen Animal:
Animal a;
a = new Animal();
Animal a = new Animal();
En skillnad mellan pekare och referenser är att man automatiskt avrefererar referenser när man använder punkt-operatorn. Man kan t.ex. skriva:
a.introduceYourself();
Eftersom man ganska snabbt hamnar i ett läge där man jobbar mycket med klasser och objekt så måste man alltså hela tiden ha i åtanke att det är referenser man jobbar med, inte "riktiga" värden. Ett vanligt fel är t.ex. att jämföra strängar på följande sätt:
String word1 = "gurka";
String word2 = "gurka";
if (word1 == word2) {
System.out.println("Orden " + word1 + " och " + word2 + " är lika.");
} else {
System.out.println("Orden " + word1 + " och " + word2 + " är INTE lika.");
}
Det som händer här är att java säger att orden inte är lika, eftersom det är referenserna som jämförs. Om man vill jämföra strängarnas innehåll så får man använda en metod istället:
String word1 = "gurka";
String word2 = "gurka";
if (word1.equals(word2)) {
En annan sak som man måste komma ihåg är att man inte skapar något nytt data (kopierar) bara för att man tilldelar:
Animal kurre = new Animal("Kurre");
Animal vilma = kurre;
vilma.setName("Vilma");
System.out.println(kurre.getName());
I koden ovan finns bara ett djurobjekt, som båda variablerna refererar till. När vi gör print:en så kommer alltså "Vilma" ut, trots att det var vilma vi ändrade på och inte kurre. Om man vill skapa nytt data så måste man instansiera klassen, d.v.s. anropa konstruktorn.
Slutligen bör det nämnas att det dyker upp tillfällen då språket självt kräver att en klasstyp skall användas (t.ex. när man använder generiska parametrar). Då duger inte de primitiva datatyperna längre och vi behöver klasser för dem. Därför finns så kallade wrapper-klasser som motsvarar de primitiva datatyperna, dessa heter Integer, Double, Boolean, o.s.v. Rekommendationen är dock att inte använda dessa om det inte är absolut nödvändigt då det oftast är mer besvär än vad det är lönt.
Vad är en instansvariabel?
Från imperativ programmering känner vi igen begrepp så som lokala variabler, globala variabler, parametrar och konstanter. Dessa är lite olika varianter på samma sak, en bit av datorns minne som man har reserverat för att lagra något data i. Hur och var man deklarerar en variabel påverkar hur den kan användas. I OOP inför vi nu ett nytt begrepp som vi kallar för instansvariabel, detta kallas även för datamedlem. En instansvariabel är en variabel som deklareras i en klass, utanför en metod. Från ett imperativt perspektiv kan man ju känna att denna variabel då blir global, d.v.s. kan ses från flera under-/huvudprogram och det stämmer på sätt och vis här också. Med ett OOP-synsät ser vi det lite annorlunda, vi ser det som en variabel som varje objekt av den klassen får. D.v.s. varje objekt som skapas kommer ha en helt egen version av denna variabel. Ett exempel är klassen Animal, där varje djur behöver ett eget namn. Då skall variabeln "name" (av typen String) deklareras utanför metoderna (men fortfarande i klassen). public class Animal {
String name;
public static void main(String[] args) {
// ...
}
}
Hur var det nu med detta "globala" då? Hur löser vi det? Som vi tidigare nämnt så kan alla metoder i klassen Animal komma åt "name". Det anser vi dock är okej i detta läge. Det som inte är bra är om hela programmet kommer åt variabeln (då skulle vi verkligen kalla den för global). Detta går lätt att begränsa med olika typer av synlighet (se kapitlet nedan om public, private och protected). Men, ja, vi skall vara medvetna om att alla metoder i klassen kan komma åt variabeln. Om detta inte är nödvändigt, säg t.ex. att vi i något underprogram behöver ha en temporär heltalsvariabel i så är det inte lämpligt att deklararera den som en instansvariabel, utan skall då deklareras lokalt i den metoden.
Ytterligare ett nytt koncept kring detta med variabler är klassvariabler. Det är det man får om man sätter nyckelordet static framför variabeldeklarationen (fortfarande utanför metoder dock). Mer om klassvariabler i stycket "Static eller ej?" nedan.
Hur som helst är begreppen instansvariabel och klassvariabel två nya typer av variabler som är högst relevanta för den aspirerande OOP-programmeraren.Hur kan en klass "använda sig själv"?
Något man ganska snabbt stöter på i java är att en klass referar till sig själv. T.ex.
public class Animal {
private Animal buddy;
... // Fler instansvariabler och metoder
}
Detta betyder väl att varje djur har en kompis, buddy. Men hur kan detta gå till?
Två saker känns fel här:
A) Får man verkligen använda typen Animal innan man har definierat klart klassen?
Svaret på denna är enkel: Ja.
Java har en
s.k. multi-pass-kompilator som innebär att kompilatorn läser
igenom koden flera gånger för att "få ihop det". (A) är egentligen
bara ett problem om kompilatorn bara läser igenom kod en gång
(s.k. single-pass-kompilator).
B) Om ett djur har en kompis, som har en kompis, som har en kompis... Är inte detta rekursion?
Svaret på denna är också ganska enkel: Nej. Eftersom alla variabler (av klasstyp) är referenser i java så betyder detta att ett djur inte nödvändigt måste ha en kompis, variabeln buddy kan ju vara null, och då har just det djuret inte en kompis. Det kan ju också vara så att ett djur A har en kompis B, och att B är kompis med A, vilket är helt naturligt och vanligt förekommande.
På grund av dessa två saker så är koden ovan inte bara korrekt, men också snygg och stilren. Det kan kännas lite förvirrande i början men när man väl börjar bli bekväm med att allt är referenser (förutom primitiva datatyper, t.ex. int, double, char, boolean) så börjar det bli ganska naturligt att formulera sig på detta sätt.
Public, private eller protected?
I java har vi tre synlighetsnivåer public, private och protected. Det är nyckelord som man sätter för en klass-/metod-/variabeldeklaration för att tala om vem som kan komma åt den. Egentligen finns det en fjärde, "package private" som inte har ett eget nyckelord, utan det är det man får om man utelämnar synlighet. Problemet med denna fjärde är att man aldrig kan veta huruvida programmeraren hade tänkt använda den eller helt enkelt glömde att skriva dit t.ex. private. Alltså bör man i regel undvika den. När skall man då använda de övriga tre? Här kommer ett par tumregler:- public - Syns från andra klasser
Används i regel alltid på klasser och konstruktorer. Vill man ha globala konstanter så får man använda public. De metoder som skall vara synlig för omvärlden skall vara public. - private - Syns endast i denna klass
Används i regel alltid på instans- och klassvariabler. Hjälpmetoder i klasser skall vara private. Observera att synligheten gäller samma klass inte (endast) samma objekt. D,v,s om vi har klassen Human så får alltså en Human tillgång till en annan Humans privata delar. - protected - Syns endast i denna klass, i subklasser och i
samma paket.
Denna är inte riktigt lika användbar. Ofta ser man (tyvärr) superklasser som deklarerar instansvariabler som protected och låter subklasser leka fritt med dessa. Det skapar dock otrevliga beroenden mellan super- och subklass och är inte en god idé egentligen.
En annan, mindre skadlig, variant är att superklassen definierar metoder protected som subklasserna kan anropa. Vill man uppnå något sådant är det dock oftast bättre att vända på beroendet och låta superklassen anropa subklassen genom att anropa en abstrakt metod som subklassen tvingas implementera. En sådan metod görs då med fördel protected.
Sammanfattningsvis är det därför inte ofta protected är lönt att använda, men det händer.
Static eller ej?
En av de kluriga aspekterna av objektorientering är att luska ut vad som bör vara statiskt och vad som inte skall vara det. Definitionsmässigt gäller följande:
static sätts framför de delar av klassen (t.ex. variabler och metoder) som man vill skall tillhöra klassen snarare än varje (eller en specifik) instans.
För att förstå detta måste man kunna skilja på instans (objekt) och klass. Klassen är en abstrakt beskrivning över något. Klassen är som en mall, eller en ritning för hur något skall skapas, men innehåller inte själv något konkret data. Det är objekten, som skapas från klassen (instansieras) som är de konkreta versionerna av klassen. Ett naturligt exempel är bilmodeller och bilar. Om vi t.ex. har bilmodellen Volvo V70 så motsvarar det en klass. Modellen kan vi inte köra, tanka, krocka eller bli rostig, eftersom den bara är en idé, ett koncept. Om vi däremot skapar faktiska objekt av denna modell, t.ex. min sprillans nya Volvo V70 som jag kallar för bettan, så kan jag köra den, putsa den och betala skatt för den.
Alltså, alla attribut som härrör faktiska bilar är sådant som har med de objekten att göra, och kan inte vara static. Exempel på detta är bilars färg, miltal, registreringsnummer, o.s.v. I vår kod blir sådana instansvariabler.
Operationer som kan göras med faktiska bilar, så som att köra dem, tvätta dem, o.s.v. är operationer som kräver att man har ett objekt, d.v.s. kan inte heller vara static. I vår kod blir sådana instansmetoder.
Så vad skall vara static egentligen? Det känns som allt här i världen har ju med riktiga objekt att göra, eller? Ja, mycket är på det viset. Det brukar faktiskt bli ganska lite som blir static i våra objektorienterade system av just denna anledning. Men det går att tänka sig saker som har med själva modellen, och inte något specifikt objekt att göra, eller som gäller för alla objekt. T.ex. namnet på den person som designade modellen Volvo V70. Det skulle kunna vara en strängvariabel i vårt program. Det är ju något som vi skulle kunna spara i varje objekt, men det blir ju onödigt och dessutom faktiskt inte rätt! Detta eftersom designern kan ju ha designat modellen, men vad hade hänt om det aldrig hade skapats ett sådant objekt? Nej, detta är typiskt något som har med klassen att göra, inte objektet. Alltså skall motsvarande variabel vara static (en klassvariabel).
Men finns det några operationer (läs metoder) som skulle kunna vara static? Allting som sker sker väl ändå med faktiska objekt? Nej, inte nödvändigtvis allt. Antag t.ex. det finns statiska variabler som skall hämtas eller sättas? Då behöver vi metoder till dem. Eftersom man skall kunna anropa dessa metoder utan att ha ett objekt så måste de deklareras som static, och vips så har vi klassmetoder.
Men det kanske finns andra situationer där vi behöver statiska metoder. Säg t.ex. att det finns data om Volvo V70 lagrade på en fil som. Vi skulle gärna vilja ha ett underprogram som läser detta data, men det hör egentligen inte hemma i någon annan klass än just vår VolvoV70-klass. Det vore då konstigt om vi krävde att själva läsningen av filen var en operation på en faktisk instans, eftersom det inte är det. Den metoden bör alltså bli static. Det finns självklart andra lösningar på detta. Vi hade kunnat skapa en klass just för detta ändamål (t.ex. VolvoV70FileReader), instansierat den och anropat en instansmetod.
För att summera kan vi alltså konstatera att för det mesta så kommer vi köra kod som ligger i instansmetoder (ej static). Det kan man tänka sig är det normala, att vi just nu befinner oss i ett objekt, som utför något. Men lite då och då så kanske det passar bättre att vi inte är det (static). T.ex. är ju main-metoden statisk eftersom vi inte har några objekt när vi startar programmet.
Varför har hela mitt program blivit static?
Även fast man håller sig som tusan ifrån att använda static är det lätt att falla in i en ond (static-)cirkel om man inte tänker sig för! Något som ibland händer är detta: Vi står i en instansmetod meth i klassen A och vill ha tillgång till någon instansvariabel eller instansmetod x i ett objekt av klassen B. Vi skriver då:
public class A {
public void meth() {
B.x; // Eller B.x()
}
}
Hur som helst får vi nu ett kompileringsfel från java-kompilatorn. Om att vi inte kan komma åt x på detta statiska vis, eftersom x inte är deklarerad static. Om vi använder eclipse kommer därför förslaget att göra x till något statiskt så att vi här kan komma åt den.
Om man låter sig luras på detta sätt kommer x bli static. Om x är en variabel så kan galenskaperna ta slut där, med endast en måttlig mängd buggar. Eftersom instansvariabler sällan kan kommas åt utifrån är det troligare att x är en metod, då blir det värre. Då har vi nu:
public class B {
public static void x() {
... // Här gör vi massa saker med instansvariabler
// och instansmetoder i B.
}
}
Eftersom x nu är static så har vi inte tillgång till någon instans och på alla ställen där vi försöker göra något med instansen blir det kompileringsfel. Felen handlar om att man inte kan komma åt this (d.v.s. instansen) från en statisk kontext. Vid varje sådant kompileringsfel får vi också förslaget från eclipse att åtgärda detta genom att förvandla det som vi försöker göra/komma åt till static.
Efter ett par iterationer av detta har alla metoder och variabler blivit static och all form av objektorientering är borta. Trist.
Var gick det fel? Självklart redan från början. Om vi i meth (i klassen a) vill komma åt något x från ett B-objekt måste vi ju ha tillgång till ett sådant objekt. Vi kan inte bara skriva B.x, eftersom B inte är ett objekt, det är en klass. Rimligtvis behöver meth ta en parameter av typen B:
public class A {
public void meth(B anObjectOfTypeB) {
anObjectOfTypeB.x;
}
}
Eller så har möjligtvis klassen A en instansvariabel av typen B som tidigare har satts (helst i en konstruktor).
public class A {
private B anObjectOfTypeB;
// A behöver nu en vettig konstruktor där
// variabeln ovan sätts.
public void meth() {
anObjectOfTypeB.x;
}
}
Summan av kardemumman är att det är mycket viktigt att hålla reda på vad som är en klass, och vad som är ett objekt av den klassen. Tänker man på det som samma sak så blir det garanterat fel förr eller senare.
Parameteröverföring och returvärden i Java
När man anropar en metod i java så skickas de aktuella parametrarna (de som står vid anropet) över, i ordning till de formella parametrarna som är deklarerade i metodhuvudet. Nedan är ett litet exempel:
private void myMethod(int age, String name) {
age = 25;
}
public static void main(String[] args) {
String name = "Erik";
myMethod(30, name);
}
Vi överför värdet 30 till parametern age och värdet i variabeln name till motsvarande parameter name i myMethod. Observera att för name är det alltså referensen till objektet som överförs.
För den som är bekant med parameteröverföringen från Ada så kan man likna detta med moden "in", fast "in" i ada medförde också att parametrarna var konstanta, vilket inte gäller här (vi får alltså tilldela age 25 inne i myMethod).
Den som nu tänker till om detta inser ju att det finns två variabler name här. En i myMethod och en i main. Men, eftersom referensen skickades så refererar dessa variabler till samma objekt! Detta innebär att ändringar som vi gör på objektet som name refererar till kommer slå igenom även i huvudprogrammet. (Detta är precis som referensparametrar i C++).
Men, om jag ändrar på själva variabeln name (eller age) så kommer det inte påverka huvudprogrammet. T.ex:
private void myMethod(int age, String name) {
name = "Nathalie";
}
public static void main(String[] args) {
String name = "Erik";
myMethod(30, name);
System.out.println("Jag heter " + name);
}
Ibland efterfrågar studenter, ja men kan man inte få ut något då (ungefär som Ada:s parametermod out). Men i java så finns inte denna parametermod. Vill man skicka ut ett värde ur metoden så är det return som gäller.
Det uttryck som kommer efter return kommer att bli ett värde. Detta värde returneras. Är uttrycket av klasstyp så kommer en referens returneras, om det är en primitiv datatyp så returneras själva värdet. Här kommer ett par exempel:
private ArrayList<String> makeListWithOneThing(String name) {
ArrayList<String> list = new ArrayList<String>();
list.add(name);
return list;
}
private int addOne(int x) {
return x + 1;
}
public static void main(String[] args) {
ArrayList<String> l = makeListWithOneThing("Erik");
int y = addOne(1);
}
Om man tycker att detta är knöligt (vilket det kan vara) så får man rita upp det för sig själv. Rita huvudprogram, underprogram och variabler/parametrar. Kom ihåg att variabler av klasstyp bara är referenser som kan hålla i ett objekt. Rita alltså sådana variabler som pekare, som refererar till ett objekt med en pil.
Parameter eller instansvariabel?
I många lägen, t.ex. som i situationen i stycket "Varför har hela mitt program blivit static?", behöver man komma åt något från ett annat objekt. Det är inte onaturligt. Det kan t.ex. vara svärdet som behöver veta om krigaren är tillräckligt stark för att bära det:
public class Sword {
public boolean canBeCarried() {
if (warrior.getStrength() > 15) {
...
}
}
Det finns i princip bara två (rimliga) lösningar på detta.
A) skicka som parameter
Den som anropar canBeCarried() får helt enkelt skicka med krigaren som parameter:
public class Sword {
public boolean canBeCarried(Warrior warrior) {
if (warrior.getStrength() > 15) {
...
}
}
if (heavySword.canBeCarried(this)) { B) använd instansvariabel
Med denna variant så har redan svärdet tillgång till krigaren, eftersom den har en instansvariabel av typen Warrior. Det är då mycket viktigt att denna instansvariabler initieras på rätt sätt, d.v.s. i konstruktorn.
public class Sword {
private Warrior warrior;
public Sword(Warrior w) {
this.warrior = w;
}
public boolean canBeCarried() {
if (warrior.getStrength() > 15) {
...
}
}
Nackdelen är att man då måste ha en krigare när man instansierar klassen Sword (d.v.s skapar objektet). Och det kan bli lite konstigt om krigaren inte existerar ännu, eller om svärdet kanske skall kunna hanteras av olika krigare.
Det finns även ytterligare en nackdel med denna variant, och det är att svärdet nu har tillgång till krigaren även när andra metoder i Sword anropas. D.v.s. krigaren skulle kunna påverkas av misstag trots att detta kanske inte alls var meningen. Vi har helt enkelt skapat en tätare relation mellan objekten än som kanske var tanken.
Frågan man måste ställa sig är: Vad är relationen mellan krigare och svärd? Är det så att ett svärd alltid har en krigare (som i variant B ovan)? Om svaret är nej, så är B antagligen fel lösning. Det kanske snarare så att en krigare alltid har ett svärd. I sådana fall får svärdet vara en instansvariabel i krigarklassen.
Eller är det kanske så att krigare och svärd bara känner till varandra och behöver interagera ibland. Då kanske det räcker med att skicka parametrar fram och tillbaka. Här kan man alltså vinna mycket på att bara sätta sig ner och resonera över klassernas natur, och deras relation till varandra. Gör man detta så kommer man oftast fram till en logisk, naturlig och snygg lösning.
Vad är en "lämplig" konstruktor?
Något som ofta kommer i skymundan i OOP är hur man gör en bra konstruktor. Många fel och buggar i koden uppstår just på grund av att ett objekt inte har byggts upp på rätt sätt. Det är konstruktorn som skall se till att instansieringen blir bra.
Egentligen har konstruktorn två viktiga egenskaper. Den ena är den vi just nämnde, att på rätt sätt initiera objektet så att det säkert kan användas senare. Det andra är att ställa krav på den som vill skapa objekt av den klassen. Om programmeraren inte skapar en konstruktor fyller språket i en defaultkonstruktor (utan parametrar och med tom kropp). Det är oftast inte alls bra eftersom det tillåter att man skapar objekt av den klassen utan att någon initiering sker alls. Bara i undantagsfall är detta något som man faktiskt vill (och det är därför java gör så). När programmeraren istället har skrivit en konstruktor så är det genom den, och endast genom den, som all instansiering sker. Vilket sätter krav på den som gör anropet.
Det man bör tänka på i konstruktorn är att alla datamedlemmar (instansvariabler) bör på något sätt få ett värde. Detta kan ske på olika sätt, antingen genom att de får värden från inkommande parametrar (som den som anropade konstruktorn har skickat med), eller att konstruktorn helt enkelt sätter dessa till något själv.
Om klassen ärver från en annan klass (annan än Objekt, vilket alla java-klasser gör) så måste man först anropa super-konstruktorn. Man kan ju se super-objektet som en del av objektet som skall skapas, och det måste skapas före resten. Anropet till super-konstruktorn sker med nyckelordet super och en parameterlista. I parameterlistan kanske man bollar vidare parametrar som konstruktorn själv fick in, eller skickar vidare konstanter. Här är ett exempel:
public class Coffee extends WarmBeverage {
private String beanType;
private boolean withCream;
private ArrayList<Condiment> condiments;
public Coffee(String bean, boolean cream, int centiliters) {
super("Coffee", centiliters); // superkonstruktorn kräver namn och hur många cl drycken är.
beanType = bean;
withCream = cream;
condiments = new ArrayList<Condiment>();
}
}
Observera att huvudprogrammet (den som skapar Coffee-objektet) inte behöver skicka in strängen "Coffee", det klarar Coffee-konstruktorn själv av att skicka vidare till WarmBeverages konstruktor. På samma sätt behöver inte huvudprogrammet skicka in ett nytt ArrayList-objekt, detta kan Coffe-konstruktorn också klara av. Att göra tvärt om, och tvinga huvudprogrammet att skicka in dessa som parametrar, är inte lämpligt och kommer leda till problem senare. (Eftersom man då tillåter kaffe-objekt att inte heta "Coffee" och man kan skicka in icke-tomma listor till condiments, eller listor som delas mellan olika objekt).
Ibland ser man att t.ex. condiments initieras direkt ovanför konstruktorn:
private ArrayList<Condiment> condiments = new ArrayList<Condiment>();
Detta är okej, men det kanske blir lite otydligt eftersom det då ser ut som att detta sker innan super-konstruktorn körs, vilket inte är fallet.
Nu kanske det är så att man vill ha flera konstruktorer. Detta bör man tänka till om, flera konstruktorer kommer ju tillåta flera sätt att skapa objektet på. Antag att vi i exemplet ovan vill tillåta att huvudprogrammet inte anger hur många centiliter som kaffekoppen är, och i sådana fall skall det vara exakt 25 cl. Eftersom java inte tillåter defaultparametrar (som t.ex. Ada och C++) så måste man överlagra konstruktorn, d.v.s. skapa en till.
Det man då inte bör göra är att kopiera hela konstruktorn och ändra lite. Detta är typisk kodkopiering och kommer leda till problem senare (t.ex. när superkonstruktorn ändras eller om vi lägger till instansvariabler i Coffee och glömmer ändra i båda konstruktorerna). Det man istället bör göra är att låta den ena konstruktorn anropa den andra, så här:
public class Coffee extends WarmBeverage {
... // Samma instansvariabler och konstruktor som tidigare
public Coffee(String bean, boolean cream) {
this(bean, cream, 25);
}
}
Denna konstruktor anropar nu den som vi tidigare skrev, fast skickar in 25 till parametern centiliters. Om vi i framtiden behöver ändra Coffees instansvariabler eller konstruktor så ändrar vi "den gamla" och ändringarna "hänger med". I de fall som den nya konstruktorn behöver uppdateras så får vi kompileringsfel så att vi direkt ser var vi måste fixa.
Arv, det är väl bara larv, eller?
Under årens lopp har vi haft många studenter som gjort fina
program. T.ex. häftiga spel som fungerar hur bra som helst. Det är då
väldigt tråkigt för oss att behöva säga:
Ja, det här var ju fint, men du har inte använt någon objektorientering.
Det som allra oftast lyser med sin frånvaro är användning av klasshirarkier, (d.v.s. arv) och polymorfi. Det blir då en komplettering och studenten blir mycket besviken. Det blir då också en konstig situation där studenten försöker forcera in en klasshirarki i projektet, och den slutliga produkten kanske faktiskt fungerar sämre än vad den gjorde från början.
För studenten kan det då kännas (och kanske för assistenten också) som att detta med arv och klasshirarkier är helt onödigt och bara dumt. Dessutom rimmar arv på larv, så det känns ju någon stans också estetiskt rättfärdigat att tänka så.
Dilemmat är här följande: i denna läromiljö som vi befinner oss i är det sällan rättfärdigat att faktiskt använda objektorienteringens fulla arsenal. Vi försöker skala upp saker så att det skall kännas som att det behövs, men förr eller senare så tar kursen slut och de projekt och laborationen som studenten arbetat på hamnar mer eller mindre till slut i skräpkorgen, ett minne blott. Men i verkligheten fungerar det aldrig så. Om någon har investerat i detta projekt så kommer det till slut bli en produkt som skall levereras. Då är det plötsligt mycket intressant vilket skick koden är i. Det är så klart också viktigt att produkten fungerar, men om koden inte går att arbeta med så är det i stort sett bortkastade pengar. Problemet är bara, hur kan man som student ta något sådant på allvar när man vet att det inte är "skarpt läge".
För att få ett system som faktiskt får något gagn av att vara objektorienterat så måste man tänka på ett objektorienterat sätt redan från början. Man behöver inte få allt rätt, det är faktiskt troligt att det blir stora luckor i systemet som behöver fyllas i eller byggas ut senare. Men man måste ha gjort en ansats till en objektorienterad analys och design. Gör man detta så får man en god grund att stå på inför framtida underhåll och expansioner i koden. Ute i industrin är det nästan alltid så att systemen förändras och utvecklas över lång tid och av många olika personer, så det måste man planera för redan från början.
Så med detta i bakhuvudet så kanske arv inte känns så larvigt längre. När man programmerar måste man bara i varje läge tänka, "vad skulle hända om man senare vill lägga till eller ändra?", istället för "exakt så här kommer det vara, för alltid."
Överskuggning
En klass som ärver från en annan får alla egenskaper från sin "förälder". Det är ju en otrolig fördel eftersom man slipper skriva koden flera gånger och dessutom får det samlat på ett ställe. Då finns det bara ett ställe att rätta om det är fel, och bara ett stället att ändra om man vill bygga ut eller modifiera.Barn lever dock inte bara för att vara exakta kopior av sina föräldrar och en ärvande klass är nu helt fri att lägga till egna metoder och instansvariabler. Observera att man då inte kan komma åt dessa från en variabel av en typ av föräldern. Vi tar ett litet exempel:
Cat kurre = new Cat("Kurre");
Animal a = kurre;
// ...
a.meow();
Detta är inte korrekt. Rimligtvis finns metoden meow() inne i klassen Cat (som ärver från Animal), men vi kan ju inte anropa den på en variabel a av typen Animal. Hur skall kompilatorn kunna "se" att a leder till ett objekt av katt-typ? Det skulle ju lika gärna kunna vara en hund, och hundar jamar inte. Ibland pratar man om "statisk" och "dynamisk" typ, här är den statiska typen för a Animal (eftersom det är så a var deklarerad) men den dynamiska typen är Cat, om vi antar att det inte händer något med a på raden med "...".
Nej det enda vi kan göra med a är de saker som finns deklarerade i klassen Animal. Det kanske finns en metod makeSound() deklarerad, då kan vi anropa den istället.
Cat kurre = new Cat("Kurre");
Animal a = kurre;
a.makeSound();
Då anropas en metod som gör ett ljud för alla typer av djur, kanske "morr". Den metoden ärvs av katten och sålledes blir det även "morr" i fallet ovan.
Det lyxiga är nu att man i klassen Cat kan skapa en helt egen version av metoden makeSound(). Om metod-deklarationen (returtyp + namn + parameterlista) är exakt samma som i superklassen så kommer denna nya variant av makeSound() ersätta den gamla och anropas istället när mågon försöker göra makeSound() på katter. Klassen Cat överskuggar alltså makeSound(). Detta skall man inte förväxla med begreppet överlagring som innebär att två metoder kan heta samma sak men ändå vara olika om de har olika parameterlistor. Så här skulle den överskuggade varianten kunna se ut i Cat:
class Cat {
public void makeSound() {
System.out.println("meow!");
}
}
@Override
public void makeSound() {
System.out.println("meow!");
}
Att det nu kan ske olika saker när man anropar makeSound() på djur är det vi kallar för polymorfi och beskrivs mer i nästa kapitel.
Polymorfi, är det magi?
Polymorfi (eller polymorfism) är något som bara tycks dyka upp när man har skaffat sig en klasshirarki. Men vad är det egentligen, och hur funkar det?
En enorm fördel med just arv, bortsett att man faktiskt "ärver" egenskaper från superklassen, är att en subklass kan anses vara en instans av superklassen. Det är nytt för den programmerare som är kvar i tänket kring stenhård typning. Tidigare var det helt förbjudet att t.ex. göra en tilldelning mellan två variabler om de hade olika typer, men nu gäller inte det längre. Om vi gör tilldelningen a = b nedan:
A a = new A();
B b = new B();
// ...
a = b;
Alltså kan variabeln a bete sig på många olika sätt, eftersom exakt vilken instans som a håller i kan variera beroende på vad som har hänt tidigare under körning. Variabeln a är alltså "flerformig", vilket bara är svenska för polymorfi. Ett exempel är om vi anropar en metod på variabeln a:
a.fun();
Så kan vi inte riktigt veta vilken kod som kommer att köras. Det kan ju vara fun() i klassen B, eller i A, eller i någon annan klass som ärver från A (eller B). Detta är något helt unikt, eftersom vi tidigare (i imperativ programmering) alltid kunnat avgöra vilket underprogram som anropas i varje läge, men nu är vi inte längre säkra.
Detta kan kännas ostabilt och magiskt, men det är faktiskt mycket praktiskt, för det innebär att klasserna själva kan definera just vad som skall hända när man kör fun() just för dem. Då landar implementationen precis i den klass där den hör hemma, och inte på något konstigt gemensamt ställe för olika typer av fun()-beteenden.
Slutligen leder detta till något som är extremt modulärt. Man kan mycket enkelt skapa sin egen variant av A och "plugga" in sin egen fun() så att den används vid rätt tillfälle, utan att behöver göra ändringar på massa olika ställen och behöva ha koll på hela bygget.
Smidigt!
Abstrakta klasser, varför?
Ibland dyker följande situation upp:
public class GeneralThing {
public void meth() {
// Öh.... vad ska vi skriva här?
// tanken är ju att subklasserna till
// GeneralThing alltid överskuggar
// denna metod! Metoden behöver alltså
// inte ha någon kod här.
// Kan vi lämna den blank?
}
}
public void static void main(String[] args) {
GeneralThing g = new GeneralThing();
g.meth();
}
I detta läge (som uppstår ganska ofta ändå) kan vi faktiskt göra mer än att lämna metodkroppen blank i GeneralTings meth(), vi kan ta bort den helt och hållet. För att vi skall få göra det så måste vi deklarera metoden som abstract också, och så fort vi har en metod som är abstrakt så behöver klassen också deklareras som abstrakt:
public abstract class GeneralThing {
public abstract void meth();
}
public class MoreSpecificThing extends GeneralThing {
@Override
public void meth() {
// Här gör vi något specifikt
}
}
public void static void main(String[] args) {
GeneralThing g = new MoreSpecificThing();
g.meth();
}
Fördelen är dessutom nu att vi inte kan kompilera MoreSpecificThing föränn vi har implementerat (och överskuggat) metoden meth(). Vi får då ett tydligt krav på oss från superklassen vilken metod vi behöver skriva.
Vi har tidigare sätt att man med klasshirarkier kan samla gemensam funktionalitet i superklassen. Subklasser får överskugga metoder om de vill ändra beteenden. Men nu har vi även ett sätt att säga att en subklass måste implementera ett visst beteende.
T.ex. är både aluminiumburkar och PET-flaskor kapabla till att innehålla läsk (ärver från samma klass), men de måste tala om hur man öppnar dem, det kan inte superklassen göra eftersom detta skiljer sig helt åt i de två subklasserna.
Vad är final?
final är ett nyckelord som dyker upp lite här och var. Man kan använda det på tre sätt. Vi tar det mest vanliga först.i) Man kan deklarera att en variabel är final. Det betyder att den inte får ändra värde när den väl är satt. T.ex.:
private final long myPersonNumber = 198706063421;
private final Animal gus = new Animal("Gus");
public void aMethod() {
gus.setName("Gustavianus III");
}
Vanligast är kanske är att man vill deklarera en konstant, då brukar man deklarera den som både final och static.
I vissa lägen, t.ex. när man jobbar med nästlade klasser, där den inre klassen försöker komma åt en variabel utanför så måste den utanförliggande variabeln deklareras som final.
En tumregel är att använda final för variabel som man misstänker inte kommer ändras i framtiden. Skulle man senare komma på att så inte är fallet kan man i sådana fall plocka bort final.
ii) Man kan deklarera en metod som final. Då får man inte överskugga den metoden i eventuella subklasser. t.ex:
public class Animal {
public final void introduceYourself() {
System.out.println("Morr, jag är ett djur.");
}
}
iii) Man kan deklarera en hel klass som final. Då får man inte skapa subklasser till den klassen. T.ex:
public final class VerySpecificThing {
// ...
}
Vad innebär "lätt" i "lätt att ändra i koden"?
I denna kurs säger vi ofta (inte minst i laborationshandledningar), "det skall vara lätt att ändra i koden" och "man skall enkelt kunna lägga till nya ..." Men vad innebär det egentligen? Vad är "lätt" och vad är "svårt"? Är det hur många rader kod man måste skriva, eller är det hur många kompileringsfel man får, eller hur mäter man "lättheten" så att säga?
Detta går så klart att mäta på olika sätt, och vad som är lätt för någon kanske är svårt för någon annan o.s.v. Men man skulle kunna göra en slags tabell för vad som händer om man gör en mindre ändring/tillägg:
| Svårt | Medel | Lätt |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Nu måste man komma ihåg att vi pratar om rimliga ändringar. Som t.ex. att lägga till en ny användartyp i LADOK3, eller att skapa en ny kategori alkoholhaltiga drycker på systembolagets hemsida. Det kommer självklart att krävas en mycket större arbetsinsats om man vill göra om något på en ännu större skala. T.ex. att göra om ett lokalbokningssystem till en biografportal.
Hur uppnår man då detta? Ja, det enkla svaret är att använda objektorienterad programmering och i övrigt god programmeringssed.
Första raden i tabellen är ofta avhängig på hur projektet är designat. Om det finns tydliga klasshirarkier, snygga gränssnitt mellan klasserna och klasserna har tydliga (och små) ansvarsområden så brukar det inte vara särskilt svårt att hamna i den gröna kolumnen. Oftast behöver man ha gjort en rejäl objektorienterad analys av systemet innan man konstruerade det för att det skall bli bra. Självklart är det omöjligt att få det rätt från början men man bör ha gjort en ansats. Därefter behöver man säkert kontinuerligt utvärdera projektets struktur och möblera om medans det växer. Har man väl börjat jobba objektorienterat brukar det inte heller vara några större svårigheter att dela upp för stora klasser i mindre bitar.
Andra raden hänger mycket på inkapsling. Det kan tyckas vara en bra sak att det är få kompileringsfel som uppstår, men det är det alltså inte. Vi gör ju faktiskt en ändring i koden, vi förväntar oss att det blir kompileringsfel någonstans medan vi jobbar. Får man det inte så tyder det ofta på att man någonstans bryter mot inkapsling eller inte har implementerat allt klart, och konstiga buggar uppstår. Kompileringsfel är ju definitivt att föredra framför buggar eftersom de går mycket snabbare att lösa. Buggar tar längre tid och kanske inte ens upptäcks föränn programmet har varit i drift en god stund.
Om dina klasser istället skyddar sin implementation och det finns ett tydligt sätt att använda dem på så får man automatiskt kompileringsfel om man skulle göra några övergrepp. (T.ex. försöker instansiera en klass på fel sätt, eller komma åt implementationsdetaljer som är private). En annan sak som hjälper oerhört är om redan definierade klasser har abstrakta metoder med tillhörande javadoc. Då får den som "subklassar" kompileringsfel tills all implementation har fallit på plats istället för att detta skall upptäckas i ett senare läge då programmet kör.
Tredje radens innehåll är ofta en följd till den första och andra raden. Man kan också se det som "hur mycket måste jag sätta mig in i koden innan jag skall göra denna ändring?". I den röda kolumnen måste man ha koll på jättemycket, nästan hela projektet. En liten ändring går som en vibration genom hela projektet och mycket rasar. Projektet är som ett korthus. Det kanske tar veckor innan man ens har byggt upp tillräckligt med självförtroende innan man vågar göra en ändring. I den gula kolumnen är det inte lika farligt, men man drar sig fortfarande för att ändra, man vet inte riktigt vad mer man kommer behöva ändra. I den gröna kolumnen ändrar man gladeligen. Man behöver bara leta upp rätt del av projektet och göra sin ändring, skapa sin nya klass där. Man kanske inte ens behöver ha så stor koll på den klass man ärver ifrån - det är bra ansvarsfördelning!
Fjärde raden är självklart bara på ett ungefär och beror helt och hållet på omfattningen av ändringen. Det är dock förhållandet här som är intressant. Det skiljer alltså magnituder på tidsåtgången att göra ändringar i projektet. Det handlar alltså inte bara om att det kanske tar någon timme mer efter att man har suttit de första fyra.
Det finns självklart en massa andra saker (som inte är OOP) som man kan göra för att snabba upp arbetet. T.ex:
- Att göra bra underprogram och hitta generella lösningar.
- Att följa kodstandarden.
- Att vara välbekant med den IDE (utvecklingsverktyg) som man använder.
- Att använda javas inbyggda typer och algoritmer istället för att skriva egna.
- Att noga dokumentera den kod man skriver med javadoc.
- Att använda versionshantering för sin kod.
- Att diskutera sina problem med sin labpartner eller kollega.
- Att ta regelbundna pauser.
Vad är ett interface?
I java finns en annan typ referenstyp än klasser, nämligen interface. Att förstå vad ett interface är, är inte svårt:
Ett interface är en abstrakt klass, där alla metoder är abstrakta.
Det är alltså precis samma sak som att deklarera en klass abstract och sedan deklarera varje metod som abstract. Språkligt är skillnaden att man inte behöver skriva "abstract" någonstans, och man använder interface istället för class och när man "ärver" från ett interface säger vi dock inte extends utan implements (man implementerar ett interface).
Man kan då fråga sig om detta inte är lite onödigt, eftersom man kan uppnå samma sak med abstrakta klasser. Svaret på det är ja (av anledningen ovan) men också nej, eftersom interface har ytterligare en egenskap:
En klass kan bara ärva från enn annan klass, men den kan implementera flera interface.
Just denna skillnad är viktig eftersom den rättfärdigar interfacens existens i java. (I C++ får man ärva från flera klasser, så då behövs inte interface utan man klarar sig med abstrakta klasser).
Vad skall man då ha dem till? Tja, de är praktiska av många anledningar men framförallt har de en förmåga att låta oss se på olika saker, men fokusera på det som är gemensamt. Tänk t.ex. så här: Vi har två klasser i ett program Bullet och Bird, som representerar pistolkulor och fåglar. De är del av sina egna klasshirarkier. Bullet kanske t.ex. ärver från klassen Ammunition, medan Bird ärver från Mammal. De har inte mycket gemensamt alls och används i olika delar av projektet, men på ett ställe i koden så har vi en metod som heter measureAirSpeed() där det ända vi bryr oss om är om objektet som kommer in som parameter kan flyga, och det råkar båda två klasserna kunna! Båda två har methoden fly(), precis det som krävs i measureAirSpeed(). Det finns här två lösningar.
A) Vi gör två varianter av measureAirSpeed():
void measureAirSpeed(Bullet bul) {
// ...
bul.fly();
// ...
}
void measureAirSpeed(Bird pipi) {
// ...
pipi.fly();
// ...
}
Nackdelen här är ju att dessa två blir ju helt indentiska, det ända som skiljer är ju typen på parametern (och namnet, vilket skulle kunna vara samma ovan). Tråkigt med kodduplicering, och varje ny sak som flyger kommer behöva en ny metod - dåligt.
B) Vi gör en gemensam measureAirSpeed():
void measureAirSpeed(Flier flyingThing) {
// ...
flyingThing.fly();
// ...
}
public interface Flier {
void fly(); // vi behöver inte skriva abstract (eller public)
}
public class Bullet extends Ammunition implements Flier {
// ...
}
public class Bird extends Mammal implements Flier {
// ...
}
public static void main(String[] args) {
Bullet bul = new Bullet();
Bird pipi = new Bird();
measureAirSpeed(bul);
measureAirSpeed(pipi);
}
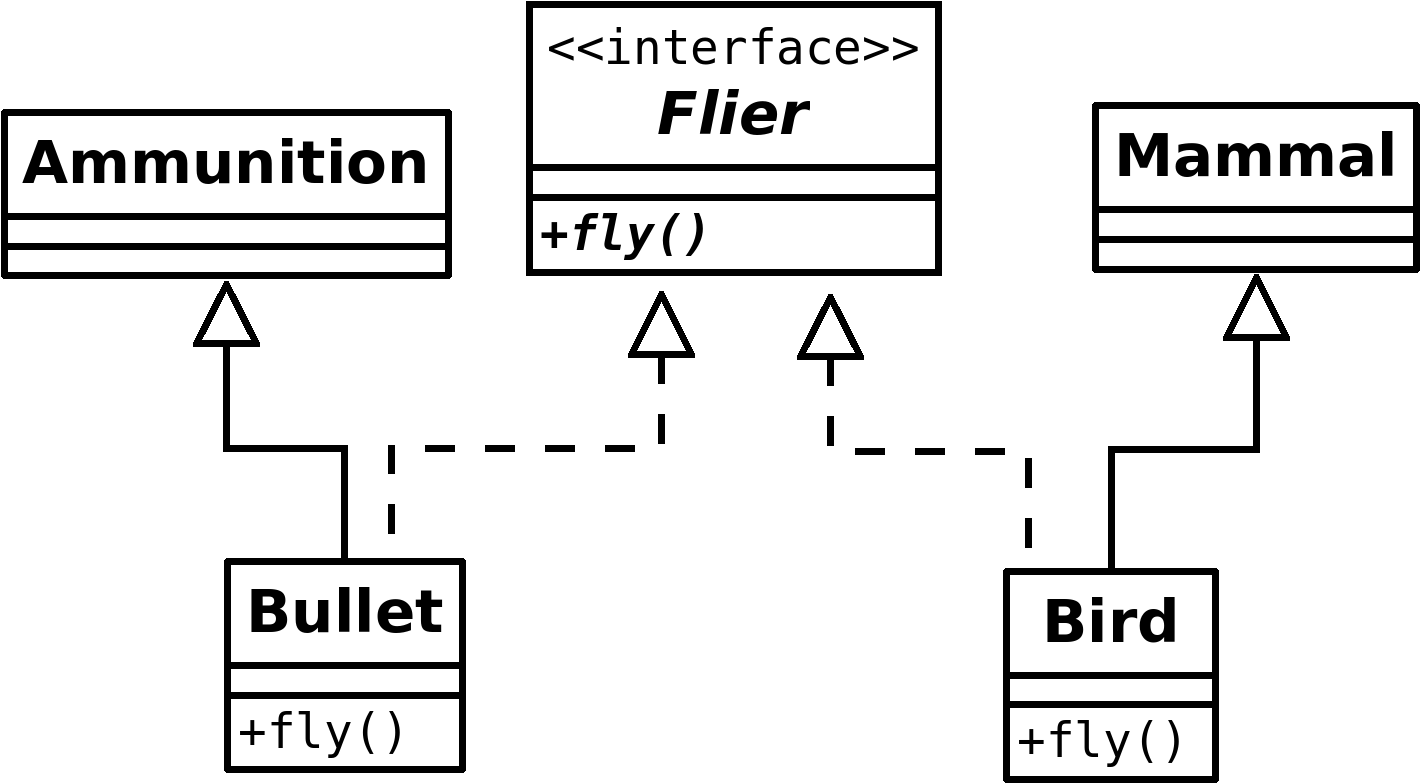
Observera att Flier inte kan vara en abstrakt klass eftersom Bullet och Bird redan ärver från lämpliga superklasser.
Checklista för en välgjord klass
När man tycker att man är klar med en klass (eller känner sig någorlunda färdig) så bör man tänka på följande saker:- Är klassen rätt namngiven (stor bokstav först, camel-case)?
- Ärver klassen från rätt superklass? Alla klasser kanske inte behöver ärva från en annan, men ofta är så fallet.
- Är instansvariablerna rätt namngivna (liten bokstav först, camel-case)? Beskriver namnen väl vad variabelerna skall användas till.
- Är alla instansvariabler nödvändiga? Om de kan flytta in som lokala variabler i metoderna, redan finns definierade i superklassen, eller inte används så bör de tas bort.
- Är alla instansvariabler private? Om inte, varför inte?
- Finns det klassvariabler (static)? Är du säker på att de skall vara static?
- Finns en lämplig konstruktor? Se kapitlet ovan för vad som är lämpligt.
- Är metoderna i klassen rätt namngivna (liten bokstav först, camel-case)? Beskriver namnen väl vad metoderna gör (inte hur de funkar).
- Har metoderna i klassen rätt synlighet (public/private/protected)?
- Följer koden kodstandarden i allmänhet?
- Har du skrivit javadoc? (Ej obligatoriskt på laborationer)
Måste jag skriva ett helt program bara för att testa något litet?
Från och med java 9 så kan man köra programmet jshell som är en interpretator som kör java direkt i din terminal. Se exemplet nedan: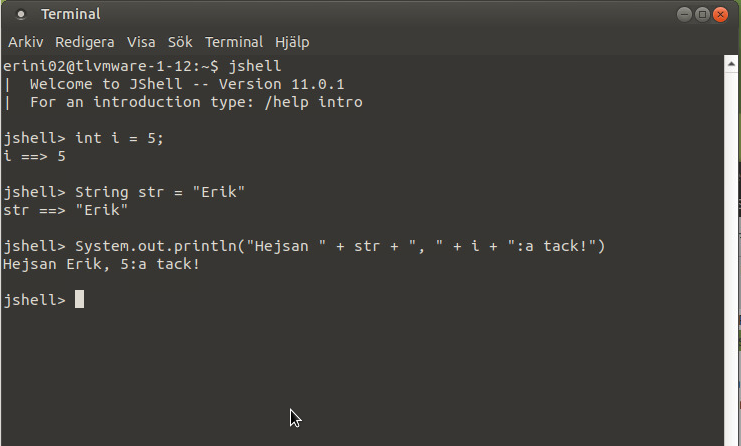 Detta kan vara praktiskt om man bara vill testa några korta kommandon,
utan att behöva dra igång eclipse och skapa ett nytt projekt bara för
det.
Detta kan vara praktiskt om man bara vill testa några korta kommandon,
utan att behöva dra igång eclipse och skapa ett nytt projekt bara för
det.
Hur gör jag en generisk klass?
Ibland vill man kunna åternyttja en hel klass, men byta ut någon intern del, t.ex. en datatyp. Säg t.ex. att man har skapat en bra klass för par av strängar och djur:
public class StringAnimalPair {
private String str;
private Animal ani;
public StringAnimalPair(String str, Animal ani) {
this.str = str;
this.ani = ani;
}
public String getString() {
return str;
}
public Animal getAnimal() {
return ani;
}
// Eventuellt setters också.
}
public class StringAnimalPair<X, Y> {
private X str;
private Y ani;
public StringAnimalPair(X str, Y ani) {
this.str = str;
this.ani = ani;
}
public X getString() {
return str;
}
public Y getAnimal() {
return ani;
}
// Eventuellt setters också.
}
public class Pair<X, Y> {
private X first;
private Y second;
public Pair(X first, Y second) {
this.first = first;
this.second = second;
}
public X getFirst() {
return first;
}
public Y getSecond() {
return second;
}
// Eventuellt setters också.
}
public static void main(String[] args) {
Animal isaac = new Animal("Isaac");
Pair<String, Animal> stringAnimalPair = new Pair<String, Animal>("Gullig", isaac);
Pair<Double, Integer> numberPair = new Pair<Double, Integer>(3.14, 1337);
}
Det är fortfarande tillåtet att använda typen Pair utan generiska parametrar (ger dock varningar), men detta är inte att rekommendera. Det som händer då är att både X och Y blir av typen Object, och vi är tillbaka i det tråkiga läge där vi behöver typomvandlingar överallt.
Ett smidigt trick är att låta java själv inferera (gissa) den generiska datatypen, då blir det lite mindre att skriva:
Pair<Double, Integer> numberPair = new Pair<>(3.14, 1337);
// ^ Här fyller kompilatorn i typerna åt oss
Det som kan vara bra att känna till är att denna information om vilken typ som är vilken bara finns just när java kompilerar koden till bytekod. När vi väl kör programmet så går det inte att använda typerna X och Y, den informationen finns inte då. Det är alltså inte möjligt att t.ex. göra så här:
// i klassen Pair
// i någon metod
if (variable instanceof X) {
//
}
Vad är ett "bra" testprogram?
Ett bra testprogram för en klass täcker 100% av klassens användning. Vi vill i almänhet ha små individuella tester av klassens förmågor (enhetstester). Att testa klassen i förhållande till andra klasser kallar vi för integrationstester. Vi fokuserar i detta stycke på det förstanämnda.
Det är i allmänhet ganska svårt att nå 100% av användningen, särskilt eftersom klasser ofta modifieras efter hand och det kan dyka upp fall som från början inte var uppenbara, men man måste göra sitt bästa för att försöka täcka upp.
Det finns hela bibliotek som fokuserar på att göra enhetstestning så enkel som möjligt (t.ex. JUnit) det är dock utanför kursens omfång och vi begränsar oss här till att göra ett "vanligt" program, men som endock har enhetstester i sig.
Antag att vi vill testa klassen från kapitlet ovan. Vi bör då fundera på hur klassen kommer att användas utifrån.
public static void main(String[] args) {
// Vi har två djur sedan tidigare, Isaac och Kurre
// Följande rad borde inte kompilera
// Pair<String, String> p = new Pair<>();
// Följande rad borde inte heller kompilera
// Pair<String, String> p = new Pair<>("Hejsan");
// Tillåtna instansieringar:
Pair<String, String> p1 = new Pair<>("Hejsan", "Svejsan");
Pair<Animal, Integer> p2 = new Pair<>(Isaac, 1337);
Pair<Animal, Animal> p3 = new Pair<>(Isaac, Kurre);
// ...
}
Vi kan ju inte testa vid körning att det faktiskt inte går att kompilera de två första satserna, men vi kan avkommentera dem och se att de ger rätt kompileringsfel.
Nu får vi anse att vi har testat klassens konstruktor. Vi kan ju iochförsig inte se att konstruktorn faktiskt gör helt rätt, men för en utomstående tycks det ju fungera så här långt. För att få någon klarhet i huruvida det funkar borde vi lägga till fler tester.
public static void main(String[] args) {
// ...
Pair<Animal, Integer> p2 = new Pair<>(Isaac, 1337);
if (p2.getFirst() != Isaac) {
System.err.println("Fick ett oväntat värde från getFirst()");
}
// ...
}
System.err är en utskriftsström precis som System.out och har liknande operationer. Den används specifikt för utskrifter av felmeddelanden, men den går ju självklart också till "skärmen". I många terminaler/consoler så skrivs dock sådan text ut med rött, så att man verkligen ser att det är fel.
Nu bör vi göra liknande tester för getSecond(), setFirst() och setSecond(). För att inte få konstiga följdeffekter (samma variabel används flera gånger utan att man vill o.s.v.) kan det vara en mycket god idé att använda separata underprogram för de individuella testerna. I slutändan kanske huvudprogrammet då ser ut på följande vis:
public static void main(String[] args) {
initTest(); // Testar konstruktor
getFirstTest();
getSecondTest();
setFirstTest();
setSecondTest();
}
Kör man detta program borde man alltså inte få några röda utskrifter från System.err, om allt är OK förstås!
Nu är klassen ovan mycket simpel och det finns egentligen inte så mycket att testa (testprogrammet blir ändå ganska långt, troligtvis 50-100 rader kod). Ofta kan våra testprogram bli ganska komplicerade. Ett exempel är när man har en metod som kan kasta ett undantag. Det är då viktigt att:
- Testa den eller de fall då metoden inte kastar undantaget. D.v.s. man skall kolla att inget undantag kastades.
- Testa den eller de fall då metoden kastar undantaget.
- Kolla att rätt undantag kastas. Om ett undantag kastas när det skall kastas ett undantag, men det är av fel typ så är det ändock fel.
Kort och gott: Man måste testa att allt som skall funka funkar OCH att allt som inte skall funka inte funkar.
Som sista kommentar kan man tillägga att vissa beteenden för klassen kanske faktiskt är odefinierade. Sådana fall behöver vi inte ta hänsyn till att testa eftersom vi faktiskt inte kan testa dem.
Testning är en central del i mjukvaruindustrin idag. Den som vill lära
sig mer om testning kan läsa sådana fortsättningskurser på avancerad
nivå på IDA,
t.ex. TDDD04
Sidansvarig: Magnus Nielsen
Senast uppdaterad: 2023-02-16
