
Grunderna till interpretator och kompilator
Interpretatorer och kompilatorer i allmänhet
För att förklara skillnaden mellan interpretatorer och kompilatorer kan vi börja med att beskriva ett mycket enkelt språk som vi kan kalla HelloGoodbye. Detta påhittade språk har bara två olika "kommandon": hello, som skriver ut en hälsning, och goodbye, som avslutar programmet (så att resten av programmet inte körs).
Vi kan representera programmet som en lista av strängar: Om vi kör programmet ['hello', 'hello', 'goodbye', 'hello'] vill vi att två hälsningar skrivs ut och att programmet sedan avslutas. Den sista hello kommer inte att göras, eftersom programmet redan har stoppats.
Hur får vi då detta att ske?
Kompilatorer
Enkelt uttryckt kan vi säga att kompilatorer är översättare. De tar ett program skrivet i ett programmeringsspråk så som Python, Java eller HelloGoodbye, och översätter det till kod som datorn sedan kan utföra på ett effektivare sätt, till exempel maskinkod som processorn förstår direkt men som är betydligt jobbigare för oss människor att skriva. Ofta tar kompilatorn då alla källkodsfiler i ett helt program och översätter dessa till en enda körbar fil.
En kompilator för HelloGoodbye skulle alltså ta vårt exempelprogram ['hello', 'hello', 'goodbye', 'hello'] och översätta detta till något annat språk. Det skulle till exempel kunna skapa ett nytt program i maskinkod, men för att förenkla lite för oss väljer vi nu att översätta till Python istället:
def the_program():
print("Hej på dej")
print("Hej på dej")
exit()
print("Hej på dej")
if __name__ == "main":
the_program()Här har vi inte sagt något om hur programmet översätts. Kompilatorer kan vara mer eller mindre komplicerade, beroende på hur komplext ursprungsspråket är, beroende på strukturen hos språket man vill översätta till, och beroende på hur noga det är att översättningen blir effektiv (kan exekveras snabbt). Detta är något ni kan få se mera om i framtida kurser.
Interpretatorer
En interpretator (tolk) fungerar istället mer som en "utförare" som läser en instruktion i taget och utför den. En interpretator för språket HelloGoodbye skulle kunna se ut så här, skriven i Python:
def interpret_hg(the_program):
for statement in the_program:
if statement == 'hello':
interpret_hello()
elif statement == 'goodbye':
interpret_exit()
else:
print("Syntax error: I don't understand " + statement)
def interpret_hello():
print("Hej på dej")
def interpret_exit():
exit()
if __name__ == "main":
interpret_hg(...)En interpretator har alltså inget separat översättningssteg, som en kompilator har. Interpretatorn tar programmet som input och "kör" det direkt. (Detta kommer vi att utforska i laboration 6.)
Å andra sidan behöver interpretatorn titta på varje sats varje gång den ska köras, för att avgöra vilken sorts sats det är och hur den ska genomföras. Om programmet t.ex. innehöll en loop som skulle utföras 10000 gånger, skulle interpretatorn gå genom alla satser i loopkroppen en gång för varje iteration. Detta tar mer tid.
För att delvis motverka tidsförlusten när man behöver tolka satser många gånger, finns ofta ett mellansteg där ett program skrivet i ett programmeringsspråk översätts till en intern representation som är lättare och snabbare att hantera än ren text. Så fungerar till exempel Pythontolken. Den interna representationen är dock fortfarande inte något som datorn förstår direkt, utan interpretatorn läser programmets "instruktioner", tolkar dem steg för steg, och utför dem.
Jämförelser
Båda metoderna har sina fördelar och nackdelar. En interpretator kan ofta vara enklare att skriva, medan en kompilator ofta kan ge ett program som kan köras effektivare. Kompilatorer ger ibland bättre hjälp med att hitta problem i programkoden då de behöver gå genom hela programmet innan det kan köras, men detta skulle i princip även en interpretator kunna göra. Eftersom en interpretator opererar direkt på programkoden kan den ibland göra felsökning enklare, då det är enkelt för interpretatorn att visa var i källkoden ett fel uppstod -- även när programmet faktiskt körs.
Det är ganska få som jobbar med att utveckla interpretatorer till stora språk, men i många olika sammanhang behöver man skriva verktyg för att tolka små domänspecifika språk, för program eller för information (konfigurationsfiler med mera). Dessutom kan interpretatorn tjäna som en modell för att lösa närliggande problem.
Källkodens struktur
För att skriva en interpretator eller kompilator behöver vi förstå språket som ska tolkas eller kompileras.
Varje programmeringsspråk har en syntax, en uppsättning regler som beskriver hur språket ser ut. Syntaxen spelar en viktig roll i att avgöra om en följd av tecken är ett korrekt program eller inte, och vad programmet egentligen "betyder".
Den konkreta syntaxen talar om hur ett program kan skrivas som en sekvens av tecken, t.ex. att symbolen + används för addition eller att ordet if används för att markera starten på villkorssatser. Här följer ett kort program som använder Pythons konkreta syntax:
n = 1
while n < 1000:
n *= 2
Den abstrakta syntaxen bortser från en del av dessa detaljer och beskriver istället hur språket är uppbyggt generellt, t.ex.:
-
Att ett program består av ett antal satser, utan att tala om hur satserna separeras när programmet skrivs som en sekvens av tecken.
-
Att en while-loop har ett villkor och en kropp som består av en eller flera satser, utan att tala om hur man vet vilka satser som ingår när programmet skrivs som en sekvens av tecken. Python använder ju indentering, medan t.ex. Java använder { } och Pascal använder begin / end. Ändå har man samma struktur på en högre nivå: För alla språken gäller att "en while-loop har ett villkor och en kropp som består av en eller flera satser".
-
Att ett uttryck kan vara en variabel, en konstant eller ett sammansatt binäruttryck (utan att tala om exakt hur "mindre än" skrivs).
Ibland vill vi också representera ett program på ett sätt som är närmare den abstrakta syntaxen och bortser från de mindre väsentliga detaljerna. Då använder vi normalt inte en sekvens av tecken utan ett abstrakt syntaxträd (AST). Trädstrukturen kommer då från den naturliga hierarkin i den abstrakta syntaxen (en while-loop innehåller ett villkor och en kropp, och while-noden i trädet får då sådana noder som barn).
Det korta Python-programmet ovan kan, något förenklat, leda till följande abstrakta syntaxträd.
................program..............
/ \
tilldelning .....loop.....
/ \ / \
n 1 mindre än? multiplicera
/ \ / \
n 1000 n 2
Analys av källkod
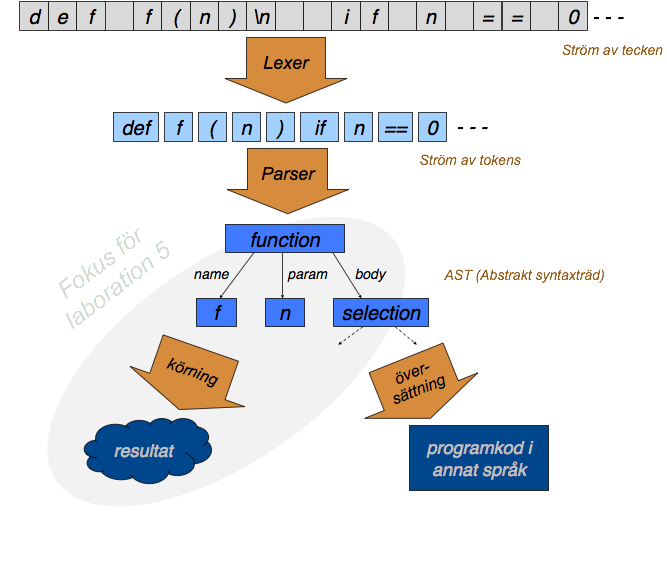
En kompilator/interpretator består av ett antal steg (se även figuren nedan):
-
Lexikalisk analys (lexing, tokenization): Bildar så kallade tokens utifrån källkodens text. Här kan man t.ex. se att bokstäverna d-e-f i ett Pythonprogram bildar det reserverade nyckelordet
defsom då är ett token i programmet. Vi sätter alltså ihop vissa teckensekvenser till mer meningsfulla enheter. Man ser också att"def"(inom citattecken) inte är nyckelordetdefutan en sträng, att==är en enda operator, och attMyPrograminte bara är en sekvens av tecken utan en identifierare. Efter den lexikaliska analysen har vi alltså gått från en sekvens av enskilda tecken till en sekvens av tokens. Att göra detta i ett separat steg bryter ut en del komplexitet som sedan inte behöver hanteras i nästa steg: Divide and conquer! -
Syntaktisk analys (parsning): Kontrollerar att koden är syntaktiskt korrekt. Efter ett "def"-token måste det till exempel komma en identifierare (med mera); vi tillåter inte "def" följt av "==". Parsern bygger samtidigt upp en datastruktur som representerar programmet på en högre nivå, ofta ett abstrakt syntaxträd enligt exemplet ovan. Efter parsningen har vi alltså inte längre en sekvens (av tecken eller tokens) utan en strukturerad representation av programmets beståndsdelar.
-
Semantisk analys: Kontrollerar till exempel typfel, i de språk som har statisk definition av typer. Man kan även kontrollera att variabler som används faktiskt har deklarerats, i språk som kräver detta.
-
Det finns ytterligare steg beroende på vilken typ av verktyg vi vill bygga (interpretator, kompilator etc). Här kan till exempel ett abstrakt syntaxträd tolkas av en interpretator, som vet hur man utför instruktionerna, eller översättas till ett annat språk av en kompilator.
Att definiera syntaxen för ett språk
I laboration 4B har vi redan definierat ett alldeles eget språk, bestående av logiska uttryck. Där har vi sagt att ett logiskt uttryck kan vara ett av följande (och inget annat):
- En av de logiska konstanterna "true" eller "false" (som alltså ska vara dessa strängar, inte True och False)
- En propositionssymbol inom citattecken, t ex "p", "q", "cat_gone"
- Ett uttryck på formen ["NOT", <logiskt uttryck>]
- Ett uttryck på formen [<logiskt uttryck 1>, "OR", <logiskt uttryck 2>]
- Ett uttryck på formen [<logiskt uttryck 1>, "AND", <logiskt uttryck 2>]
Detta lät oss skriva uttryck som ["NOT", ["NOT", ["NOT", ["cat_asleep", "OR", ["NOT", "cat_asleep"]]]]] som kunde tolkas av funktionen interpret.
Men den här beskrivningen är ganska luddig. Det vore trevligt om man kunde beskriva det på något mer formellt sätt! Det kan vi göra på många olika sätt, men ett som är ganska vanligt är Extended Backus-Naur Form (EBNF). För att förklara hur EBNF fungerar kan vi använda det för att beskriva logikspråket.
Vi börjar med några enkla definitioner.
alphabetic_character = "a" | "b" | "c" | "d" | "e" | "f" | "g"
| "h" | "i" | "j" | "k" | "l" | "m" | "n"
| "o" | "p" | "q" | "r" | "s" | "t" | "u"
| "v" | "w" | "x" | "y" | "z"
| "A" | "B" | "C" | "D" | "E" | "F" | "G"
| "H" | "I" | "J" | "K" | "L" | "M" | "N"
| "O" | "P" | "Q" | "R" | "S" | "T" | "U"
| "V" | "W" | "X" | "Y" | "Z" ;
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
underscore = "_" ;
Här börjar vi med att definera alfabetiska tecken. Text inom citat, som ", representerar tecken eller strängar som förekommer i språket. Med | anger man att det finns olika alternativ. En alphabetic_character är alltså vilket tecken som helst från A till Z. Motsvarande gäller för definitionen av digit, medan underscore bara kan vara just ett sådant tecken.
Terminologi: "a" är en terminal medan alphabetic_character är en icke-terminal. Detta har ingenting med flygplatser att göra, utan terminaler kan tänkas på som alla faktiska symboler som kan finnas i ett språk, dvs tokens. Icke-terminaler är uttryck som behöver utvärderas/expanderas i (minst) ett steg till för att kunna tokeniseras och tolkas.
Man kan också se icke-terminaler som en sorts "funktionsanrop": Om det står att vi ska ha en alphabetic_character på en viss plats, måste vi "anropa" alphabetic_character för att se hur en sådan egentligen är definierad. Om det står att vi ska ha "a" på en viss plats, vet vi redan vad det är -- det är en sorts "konstant".
identifier = alphabetic_character, { alphabetic_character | digit | underscore } ;
En identifier börjar med en alphabetic_character. Med hjälp av komma (,) skapar vi en sekvens: Det alfabetiska tecknet ska följas av något. Med {...} anger vi upprepning: Noll eller flera av det som står inom klamrarna. Efter en alphabetic_character ska vi alltså ha noll eller fler alfabetiska tecken, siffror och/eller understreck. Därmed är ab_12_6b en godkänd identifier.
Här har vi alltså integrerat en del av den lexikaliska analysen i vår EBNF-specifikation: Det är här vi kombinerar ihop olika tecken till tokens som är identifierare. Man kan också göra på ett annat sätt -- man kan utgå från att en separat lexer hanterar detta, och att icke-terminalen identifier därmed redan existerar som en bas för vår EBNF-grammatik att utgå från.
expression = const | prop | negation | disjunction | conjunction ;
const = "true" | "false" ;
prop = identifier ;
negation = "NOT", expression ;
disjunction = "[", expression, "OR", expression, "]" ;
conjunction = "[", expression, "AND", expression, "]" ;
Här använder vi de EBNF-konstruktioner vi har sett tidigare för att definiera resten av språket. En expression är alltså något av de fem angivna fallen, en const är alltid någon av true eller false (utan citattecken -- de används ju bara för att få EBNF att förstå att vi menar en faktisk teckensekvens och inte )
Viktigt: En expression kan vara en negation, som i sin tur innehåller en expression. Vårt språk är alltså av naturen rekursivt: Uttryck innehåller andra uttryck. Därför är det antagligen bra att också hantera det med en rekursiv implementation.
Sidansvarig: Peter Dalenius
Senast uppdaterad: 2021-12-03
