
Compilation of Modelica for parallel computers
Modern state-of-the-art equation based object oriented modeling languages such as Modelica have enabled easy modeling of large and complex physical systems. When such complex models are to be simulated, simulation tools typically perform a number of optimizations on the underlying set of equations in the modeled system, with the goal of gaining better simulation performance by decreasing the equation system size and complexity. The tools then typically generate efficient code to obtain fast execution of the simulations. However, with increasing complexity of modeled systems the number of equations and variables are increasing. Therefore, to be able to simulate these large complex systems in an efficient way parallel computing can be exploited.This project goal is building an automatic parallelization tool that produces an efficient parallel version of the simulation code by building a data dependency graph (task graph) from the simulation code and applying efficient scheduling and clustering algorithms on the task graph.
| r2_q = drel+dr_phi;r2_qq = r2_q-0.017*r2_q0;r2_cosq = cos(r2_qq);r2_sinq = sin(r2_qq); r2_Sx_0rel_3_1 = r2_nn_3*r2_nn_1-r2_cosq*r2_nn_3*r2_nn_1+r2_sinq*r2_nn_2; r1_q = drel+dr_phi;r1_qq = r1_q-0.017*r1_q0;r1_cosq = cos(r1_qq);r1_sinq = sin(r1_qq); r1_Sx_0rel_2_1 = r1_nn_2*r1_nn_1-r1_cosq*r1_nn_2*r1_nn_1-r1_sinq*r1_nn_3; r1_wx_0rela_1 = r1_qd*r1_nn_1; r1_Sx_0rel_2_2 = r1_nn_2*r1_nn_2+r1_cosq*(1-r1_nn_2*r1_nn_2); r1_wx_0rela_2 = r1_qd*r1_nn_2; r1_Sx_0rel_2_3 = r1_nn_2*r1_nn_3-r1_cosq*r1_nn_2*r1_nn_3+r1_sinq*r1_nn_1; r1_wx_0rela_3 = r1_qd*r1_nn_3; body1_body_wa_2 = r1_Sx_0rel_2_1*r1_wx_0rela_1+r1_Sx_0rel_2_2*r1_wx_0rela_2 +r1_Sx_0rel_2_3*r1_wx_0rela_3; |
|
|
Various scheduling and clustering algorithms, adapted for the requirements from this type of simulation code, have been implemented and evaluated. The scheduling and clustering algorithms presented and evaluated can also be used for functional dataflow languages in general, since the algorithms work on a task graph with dataflow edges between nodes.
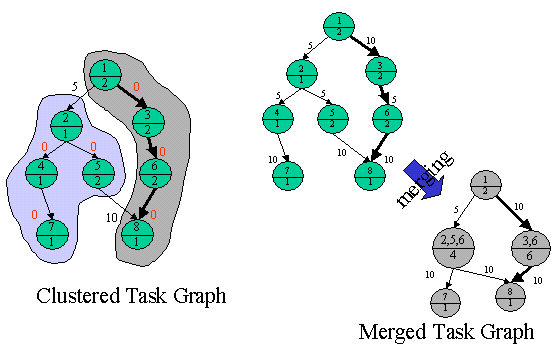
|
Results are produced in form of speedup measurements and task graph statistics produced by the tool. Some of the algorithms investigated and adapted in this work give reasonable measured speedup results for some specific Modelica models, e.g. a model of a thermofluid pipe gave a speedup of about 2.5 on 8 processors in a PC-cluster. However, future work lies in finding a good algorithm that works well in general.
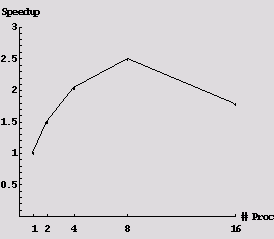
|

|
This work has been supported by NUTEK (Swedish National Board for Industrial and Technical Development), the EU-IST projects Joses and RealSim, and MathCore AB.
- Paper: Peter Aronsson and Peter Fritzson, Multiprocessor Scheduling of Simulation Code From Modelica Models, (PDF) 2nd Modelica conference.
- Papers are available from the author's home page.
- Supported by RealSim (EC)
project
- Contact: Peter Aronsson,
petar@ida.liu.se
Page responsible: Webmaster
Last updated: 2012-05-07
