
TDDE19 Advanced Project Course - AI and Machine Learning
Projects
Projects
Students will be divided into a group of around 5-6 students. Each group is assigned to a project (according to the preference and skills of each groups).
At the end of the project, the students are expected to provide:
- Source code of library/program in a gitlab repository
- Documentation of how to use and install the software (API, command line...)
- A group report describing the work that has been accomplished (which algorithms are used, what kind of results were obtained...)
- An individual list of contributions to the project.
Important: the deadline for the selection of projects is Wednesday 3th of September 2025 at 13:00, you need to send me an email (mattias.tiger at liu.se) with the following information:
- The group number from webreg.
- A ranked list of all projects (details on the projects below)
Project list
1) Semantic Mapping
Customer/Supervisor: Piotr Rudol

(Image from WARA-PS)
Context: the goal of this project is to explore the use of machine learning to build semantic map of the environment using ground robotic system such as Boston Dynamics Spot robot operating in an indoor environment. Such map would include locations of detected objects, for example TV, chair, desk, vehicle, etc. The task could be achieved using vision-based CNN models in combination with sensor fusion algorithms such as Extended Kalman Filter. Semantic information would be stored in the robot’s knowledge database using Resource Description Framework (RDF) Graphs. Initially, the work would be performed on pre-recorded log files, with the possibility of running and test.
Goal: Develop and evaluate a semantic mapping pipeline that combines object detection, sensor fusion, and knowledge representation, first on recorded data and then on a real robotic platform. The system should robustly detect and track objects in indoor environments, and store semantic information in a structured format suitable for reasoning and future robot tasks.
Task suggestions:
- Study literature.
- Review and evaluation of available ML models for extraction of semantic information.
- Use of sensor fusion techniques for estimation and tracking of object locations.
- Deployment and evaluation of the project results on real robotic system.
References:
- YOLOv10
- Toward General-Purpose Robots via Foundation Models
- Hastily formed knowledge networks and distributed situation awareness for collaborative robotics
- Previous related student project
2) Raising an LLM
Language Model Pre-Training with Scalable Transformers
Customer/Supervisor: Kevin Glocker
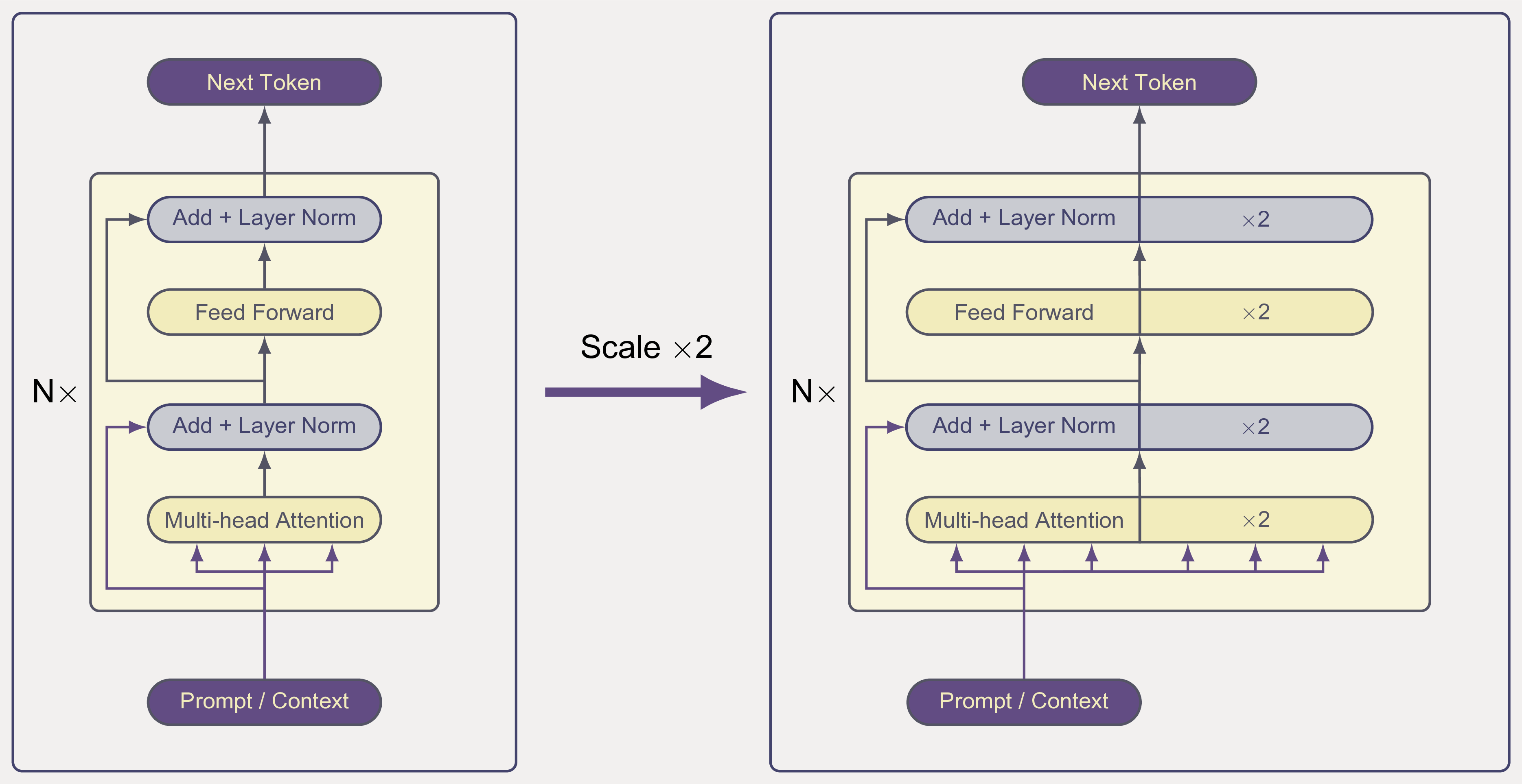
Context:
Large Language Models (LLMs) have become central to modern AI due to their fluent language generation, reasoning capabilities, and versatility across tasks. However, training such models typically requires massive datasets and billions of parameters, resulting in high computational costs and environmental impact. Recent research on scalable transformers (e.g., HyperCloning, Tokenformer) shows that models can gradually grow in size during training, achieving faster convergence and reduced resource requirements. At the same time, the BabyLM challenge highlights the importance of data efficiency by constraining training to developmentally plausible corpora. This project explores combining scalable architectures with data-efficient training strategies to create resource-conscious yet high-performing language models.
Goals:
Investigate scalable transformer architectures and data-efficient pre-training strategies to develop LLMs that gradually increase in capacity while remaining competitive in benchmark performance.
Task suggestions:
- Study literature on transformer scaling methods and data-efficient pre-training (e.g., HyperCloning, Tokenformer, BabyLM).
- Implement heuristics or ML-based methods for estimating data complexity in English or Swedish corpora.
- Train scalable language models using the Nanotron pretraining library.
- Experiment with gradually increasing the number of model parameters alongside data complexity.
- Evaluate models on established benchmarks and compare training efficiency against baseline LLM setups.
- (Optional) Implement and test the Tokenformer architecture in Nanotron.
- (Optional) Extend experiments to code or formal-language datasets to study cross-domain effects.
References:
- M. Samragh, I. Mirzadeh, K. A. Vahid, et al., “Scaling smart: Accelerating large language model pre-training with small model initialization,” ENLSP, 2024.
- H. Wang, Y. Fan, M. F. Naeem, et al., “Tokenformer: Rethinking transformer scaling with tokenized model parameters,” ICLR 2025.
- M. Y. Hu, A. Mueller, C. Ross, et al., “Findings of the second BabyLM challenge: Sample-efficient pretraining on developmentally plausible corpora,” CoNLL, 2024.
- Nanotron pretraining library
Attachments: Detailed description
3) Mastering the Unpredictable: AI Control with Gaussian Processes
Uncertainty-Aware Model Predictive Control with Gaussian Process Dynamics
Customer/Supervisor: Emil Wiman

Context: Traditional model predictive control (MPC) relies on accurate mathematical models of system dynamics, which are often incomplete or inaccurate in real-world scenarios. This project focuses on learning physical system dynamics using uncertainty-quantifying Gaussian Processes (GPs) and integrating these learned models with advanced MPC frameworks like ACADO/ACADOS. The system will generate optimal control trajectories that account for both model accuracy and uncertainty, enabling safer and more robust autonomous behavior. The learned uncertainty models will be integrated with lattice-based motion planners to create a complete autonomous system that can handle model uncertainties gracefully. Optional extensions include safe exploration techniques and reinforcement learning for continuous model improvement. Bayesian optimization (BO), hyperopt/optuna/BoTorch, can be used for hyperparamter tuning as well as for safe and sample-efficient exploration of the dynamical model.
Goals:
The goal of this project is to design and evaluate an uncertainty-aware model predictive control framework that leverages Gaussian Processes for learning system dynamics. By combining the data-efficient learning properties of GPs with the robust optimization capabilities of MPC, the project aims to demonstrate safer and more reliable autonomous control compared to traditional MPC approaches that rely on fixed or inaccurate models.
Task suggestions:
- Study literature on Gaussian Process regression for dynamics learning and uncertainty quantification
- Implement GP-based dynamics learning framework with automatic hyperparameter optimization
- Integrate learned GP models with ACADO/ACADOS optimization frameworks for uncertainty-aware MPC
- Develop uncertainty propagation methods through MPC prediction horizons
- Integrate with lattice-based motion planner that incorporates uncertainty information from GP models
- Design exploration strategies for continuous model improvement (optional BO or RL component)
- Create simulation environment for testing on various dynamical systems (pendulum, quadrotor, ground vehicles)
- Evaluate system performance comparing uncertainty-aware vs traditional MPC approaches
- Implement safety constraints and robust control strategies based on uncertainty estimates
References:
- Gaussian Processes for Machine Learning
- Model Predictive Control
- Safe Model-based Reinforcement Learning with Stability Guarantees
- ACADO Toolkit for Automatic Control and Dynamic Optimization
- ACADOS - Fast and Embedded Solvers for Nonlinear Optimal Control
- GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference
- Gaussian Process library GPyTorch
- Approximate GPs for heteroschedastic noise
- Bayesian Optimization for sample-efficient and safe exploration
- Safe Learning in Robotics: From Learning-based Control to Safe Reinforcement Learning
- Learning-based Model Predictive Control: Toward Safe Learning in Control
- Receding-Horizon Lattice-Based Motion Planning with Dynamic Obstacle Avoidance
- Enhancing lattice-based motion planning with introspective learning and reasoning
4) Personalized natural interface
Streamlined Personalization of Speech Interfaces (STT + TTS) for English & Swedish
Customer/Supervisor: Mattias Tiger

Context:
Natural-language interfaces become much more effective when adapted to individual users: accent, speaking style, vocabulary, and preferred voice. This project aims to make that personalization easy and repeatable for non-experts. Students will build an end-to-end pipeline that (1) collects small amounts of user speech, (2) fine-tunes ASR models (Whisper v3 for multilingual and KB-Whisper for Swedish) and TTS models (Orpheus-TTS for English and Piper-tts-nst-swedish for Swedish), and (3) iterates with human-in-the-loop corrections to steadily improve fidelity and usability. The project will emphasize efficient fine-tuning pipelines using Unsloth and similar frameworks, while also designing a process that is streamlined enough for non-technical users.
Goals:
Design and evaluate a low-friction personalization workflow that a non-technical user can complete in under ~30 minutes per iteration, yielding measurable improvements in STT accuracy and TTS naturalness/likeness for both English and Swedish.
Task suggestions:
- Data & UX: Implement a minimal, non-technical onboarding flow: consent → mic check → short fidelity/accuracy test (read-aloud prompts) → automatic quality checks (SNR, clipping, silence) → upload/segmentation.
- STT fine-tuning: Prepare iterative fine-tunes for Whisper v3 and KB-Whisper. Support LoRA/QLoRA adapters, mixed precision, and optional data augmentation (noise/room impulse responses).
- TTS fine-tuning: Personalize Orpheus-TTS (EN) and Piper-TTS (SV). Explore small prompt sets to capture timbre/prosody; experiment with speaker embeddings vs adapter layers.
- Time-stamping & segmentation: Integrate word-level timestamping methods to automatically highlight problematic sections and generate fine-tuning samples.
- Active learning loop: After each deployment, log low-confidence or user-corrected utterances; propose the next batch of data to collect. Consider Bayesian optimization to identify words, phrases, or utterance structures that need more annotation or training data.
- LLM-assisted review: Use an LLM (e.g., Qwen3) to flag potentially incorrect transcriptions, especially when a single word appears inconsistent with surrounding context.
- Human-in-the-loop UI: Build a correction/review screen: highlight STT errors, allow quick substitutions and approvals; enable live or post-hoc annotation.
- Domain lexicons: Add custom words (names, places, jargon) with phonetic lexicon updates and evaluate gains.
- Evaluation: Compare with recent research papers and how performance is measured at major Git repos. E.g. track STT WER/CER by domain and language, and for TTS, run MOS-lite and AB preference tests plus objective proxies (MCD, F0 RMSE). Include latency and resource usage.
- Automation & reproducibility: One-click “personalize” job with clear logs, artifacts, and rollbacks. Export model adapters and a small “profile bundle” (audio + metadata + adapters).
- Safety & privacy: Provide on-device/edge options, data retention choices, explicit consent, and an easy “delete everything” button.
- Deployment: Package as a web app. Provide demo mode showing before/after personalization on dictation or command tasks.
References:
- Whisper v3: Robust multilingual speech recognition
- KB-Whisper: Swedish fine-tuned Whisper
- Orpheus-TTS: Neural TTS with LoRA support
- KBLab/piper-tts-nst-swedish: Swedish TTS voice
- Unsloth: Efficient fine-tuning for LLMs and TTS
- whisperX, whisper-timestamped: Word-level timestamps for Whisper
- BoTorch: Bayesian optimization framework
- Qwen3: Advanced open LLM for contextual reasoning
- Mozilla Common Voice, Multilingual LibriSpeech (for bootstrapping/augmentation)
5) Who says?
Enhancing Multi-talker STT Systems with Diarization and Speaker-Aware Recognition
Customer/Supervisor: Mattias Tiger

Context:
In many real-world speech systems—like smart home assistants, meeting transcribers, or secure voice interfaces—it’s crucial not only to transcribe multi-person conversations accurately but also to distinguish who spoke when and to recognize specific users for access control or personalization. This project will build a pipeline that integrates voice activity detection (VAD), speaker diarization, and speaker recognition, enabling systems to selectively trust and process commands from authorized individuals.
To lower the barrier to entry, the project begins with an easy baseline using WhisperX (multi-speaker transcription with diarization and word-level alignment). This baseline can be used as-is, or as a comparative reference, when exploring more advanced or fine-tuned diarization and speaker-recognition methods.
Goals:
Develop an end-to-end, easy-to-use personalization workflow that:
- Segments multi-speaker audio into speech vs non-speech,
- Identifies and tracks individual speaker turns (diarization),
- Learns to recognize a small set of authorized voices quickly,
- Applies the above to filter or prioritize specific speakers’ commands securely.
Task suggestions:
- Baseline setup: Deploy WhisperX for multi-speaker transcription with diarization; record diarization error rate (DER) and word error rate (WER) as a day-1 benchmark.
- Voice activity detection: Start with Silero VAD as a lightweight baseline. Fine-tune pyannote.audio’s VAD/SAD models on your project’s noisy or overlapping speech data to improve recall/precision.
- Speaker diarization: Use WhisperX+pyannote diarization as the baseline. Fine-tune pyannote segmentation/embedding models or explore NeMo diarizers (e.g., MSDD/Sortformer) for better accuracy and overlap handling.
- Speaker recognition: Use SpeechBrain’s ECAPA-TDNN or 3D-Speaker as baselines for speaker verification. Fine-tune embeddings with enrolled user data to improve recognition of authorized voices.
- ASR adaptation: Use Whisper (baseline) to generate transcripts. Fine-tune Whisper with Unsloth adapters (LoRA/QLoRA) to reduce WER on domain-specific terms or to adapt to individual speakers’ accents.
- Secure command filtering: Combine diarization + recognition to only accept commands from enrolled speakers.
- Iterative personalization: Allow users to correct diarization/recognition mistakes and re-train in small steps, comparing results against the WhisperX baseline.
- Evaluation: Measure DER/JER for diarization, EER/minDCF for speaker recognition, precision/recall for VAD, and per-speaker WER for ASR. Always compare back to the WhisperX baseline.
- Deployment: Package as a web app. Provide demo mode showing before/after personalization on dictation or command tasks.
- (Optional Phase 2) Multi-microphone localization fusion: Estimate speaker position using microphone array and fuse with neural diarization estimation for improved diarization. Visualize location in web app and connect location with what is being said (e.g. chat bubble on map).
- (Optional Phase 3) Use-case: Build a web app for hearing-impaird persons so that they can see different conversations (clustered using an LLM) and read the conversation as a chat history per conversation.
References:
- WhisperX: word-level alignment + diarization baseline
- pyannote.audio: trainable VAD/diarization/embeddings
- SpeechBrain: VAD, diarization, and speaker recognition recipes (e.g., ECAPA-TDNN)
- Silero VAD: lightweight VAD baseline (not trainable)
- NVIDIA NeMo: diarization pipelines (e.g., MSDD/Sortformer) and ASR stack
- 3D-Speaker: toolkit for speaker verification & diarization
- OpenAI Whisper: ASR to pair with diarization
- Unsloth: efficient adapter-style ASR/TTS fine-tuning
6) FastTalk: Real-Time STT -> LLM -> TTS
Building a Robust, Configurable, and Low-Latency Voice Assistant (Server + Optional Web UI)
Customer/Supervisor: Mattias Tiger

Context:
Real-time voice systems juggle tough trade-offs: accuracy vs latency, smooth turn-taking vs barge-in, and “no-pause” speech synthesis that starts speaking on the first tokens while the rest streams in. This project builds a production-like pipeline—server-based, optionally with a web front-end—that lets users see and tune those trade-offs, run benchmarks automatically, and preview consequences in simulated conversations (text-only or full audio-to-audio).
Goals:
Design and evaluate a configurable, real-time STT→LLM→TTS stack that:
- Achieves low end-to-end latency with no audible pause before speech starts.
- Supports barge-in (interrupt TTS when the user speaks).
- Is intuitively tunable (dashboard with sliders/toggles) and benchmarkable (automatic tests for latency/accuracy).
- Runs as a server deployment; the web dashboard is optional.
Task suggestions:
- Baseline architecture (server first): Stand up a Python/FastAPI + WebSocket backend modeled on RealtimeVoiceChat. Provide REST/WS endpoints for audio-in, token-stream, audio-out; package with Docker Compose (GPU aware).
- STT path: Start with faster-whisper via RealtimeSTT or WhisperLive as the low-latency baseline. Expose chunk size, VAD aggressiveness, and post-speech silence in config. Compare at least two backends (e.g., RealtimeSTT vs WhisperLive with faster-whisper/TensorRT/OpenVINO).
- LLM path: Use a streaming LLM (Ollama or another streaming-capable backend). Implement first-token latency capture and streaming partials. Add presets for response style (“brief”, “friendly”, “structured JSON”) to show quality–latency trade-offs. It is recommended to use LLama 3.1 or Qwen3 3.
- TTS path: Drive streaming synthesis with RealtimeTTS using Orpheus as the primary engine; also include a low-latency baseline (Piper). Implement sentence/phrase chunking, buffer cross-fades, and instant start (speak on first stable chunk, or as many that is allowed according to configuration - tuned on quality requirement).
- Turn-taking & barge-in: Integrate VAD on the input while TTS is playing; auto-pause/cancel TTS when user speech begins (based on how it is configured). Provide a policy knob: strict half-duplex vs conversational. Also, optionally, allow the LLM to barge in (controlled by a setting).
- Dashboard & simulator: A web dashboard to tweak parameters (chunk size, VAD thresholds, LLM temperature/top-p/max tokens, TTS engine/speed/pitch, overlap handling). Include a playground that replays canned scenarios (wav + scripted LLM reply) to preview settings as text-only or full audio-to-audio, where e.g. LLM and/or TTS can be toggled on or to use scripted version.
- Benchmarking & auto-sweeps: Implement tests that:
- measure E2E latency (user speech end → first TTS audio), LLM first-token latency, TTS first-audio latency, overall response time;
- compute STT WER on streamed audio;
- run parameter sweeps (e.g., chunk length vs VAD threshold vs LLM max tokens) and plot quality–latency curves;
- record GPU/CPU utilization and RTF (real-time factor).
- Resilience & ops: Timeouts, graceful degradation (fallback to lighter STT/TTS), and structured logs/metrics.
- (Optional) Personalization hooks: Per-user lexicons for STT; selectable TTS voice; store/load profiles.
- (Optional) Deployment variants: Edge-first (single GPU) vs multi-service split (separate STT/LLM/TTS pods). Add A/B testing mode.
References:
- RealtimeVoiceChat (server + web UI blueprint): https://github.com/KoljaB/RealtimeVoiceChat
- RealtimeSTT (faster-whisper, WebRTC-VAD, Silero VAD, wake-word): https://github.com/KoljaB/RealtimeSTT
- RealtimeTTS (streaming multi-engine TTS): https://github.com/KoljaB/RealtimeTTS
- WhisperLive (real-time Whisper server; faster-whisper/TensorRT/OpenVINO backends): https://github.com/collabora/WhisperLive
- whisper_real_time (minimal streaming demo): https://github.com/davabase/whisper_real_time
- WhisperFusion (speech↔LLM↔speech exemplar): https://github.com/collabora/WhisperFusion
- faster-whisper (CTranslate2 Whisper): https://github.com/SYSTRAN/faster-whisper
- WebRTC VAD: https://github.com/wiseman/py-webrtcvad
- Silero VAD: https://github.com/snakers4/silero-vad
- Piper TTS: https://github.com/rhasspy/piper
- Orpheus-TTS: https://github.com/ylacombe/orpheus-tts
- Kokoro-TTS: https://github.com/hexgrad/kokoro
- Ollama (streaming LLM server): https://github.com/ollama/ollama
7) Small-but-Mighty Tech Support LLM
Customer/Supervisor: Andreas Bueff

Context: Large LLMs are strong generalists but expensive to run. This project builds a compact domain-specialized student LLM (≈1–3B parameters) for consumer-electronics troubleshooting (headphones, speakers, smart devices) that retains language quality. Students will (1) distill knowledge from a larger teacher model, then (2) fine-tune the student with Group Reward Policy Optimization (GRPO) using multi-objective rewards that balance technical accuracy and language quality (grammar, clarity, helpfulness). Finally, they will (3) deliver a voice interface (STT → LLM → UI) and (4) an evaluation suite covering domain expertise and general language retention.
Goal: Distill & Compress: Implement a KD pipeline from a 7B-class teacher → 1–3B student, focused on device troubleshooting. Align with GRPO: Design multi-objective rewards (domain correctness + language quality) and train the student with GRPO. Demonstrate: Ship a voice-enabled demo app where users ask device questions and get step-by-step solutions. Evaluate & Report: Provide a rigorous evaluation of domain specialization vs. general language retention, with ablations.
Task suggestions:
- Study KD for LLMs (response/logit distillation, temperature, domain-aware sampling) and RL for LLMs (RLHF, GRPO). Select a teacher model (e.g., LLaMA-7B/Qwen-7B-Instruct) and a student (1.5–3B). Curate a domain corpus from manuals, troubleshooting guides, vendor FAQs, and forums.
- Implement KD: Response-based KD (teacher-generated answers, supervised fine-tuning). Optionally add logit KD (KL loss with temperature). Domain-aware sampling. Track KD metrics (loss, ROUGE, domain QA accuracy).
- GRPO + Multi-Objective Rewards: Design reward functions combining domain correctness (step-by-step accuracy, completeness) and language quality (grammar, clarity, helpful structure). Implement GRPO training with group-relative rewards.
- Evaluation: Benchmark domain expertise (task success, completeness, actionability), compare teacher vs. KD vs. KD+GRPO models, test language retention (fluency, QA, perplexity). Analyze trade-offs and efficiency.
- Voice Demo: Implement an STT → LLM → UI pipeline. Use Whisper/faster-whisper for STT, FastAPI + websockets for backend, and a simple web UI with mic input and streaming responses. Optionally integrate TTS for read-back.
References:
- Distilling the Knowledge in a Neural Network
- Training Language Models to Follow Instructions with Human Feedback (InstructGPT)
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs (GRPO-based RL)
- KDRL: Post-Training Reasoning LLMs via Unified Knowledge Distillation and Reinforcement Learning
- LLMR: Knowledge Distillation with a Large Language Model-Induced Reward | arXiv
- DDK: Distilling Domain Knowledge for Efficient Large Language Models
- Alpaca: A Strong, Replicable Instruction-Following Model | GitHub
- TRL: Transformer Reinforcement Learning | GitHub
- TRLX: Distributed RLHF training for LLMs
- Why GRPO is Important and How it Works
- LoRA: Low-Rank Adaptation of Large Language Models | OpenReview
- PEFT: Parameter-Efficient Fine-Tuning | Docs | GitHub
- vLLM: Efficient Memory Management for LLM Serving with PagedAttention | ACM Digital Library
- Whisper: Robust Speech Recognition via Large-Scale Weak Supervision | GitHub
- faster-whisper
- LanguageTool | Developer Docs
- Sentence-BERT | Docs
- Alpaca dataset (52K instruction-following samples)
Attachments: Detailed description
Previous years projects:
- 2024
- 2023
- 2022 (with source code and reports)
- 2021 (with source code and reports)
- 2020 (with source code and reports)
- 2019 (with source code and reports)
- 2018
- 2017
Page responsible: infomaster
Last updated: 2025-09-30
