
Lab Assignment 4: VLIW Processors
Table of Contents
- Objective
- Time allocation
- Theoretical background
- Assignments
- Preparation
- Details
- What to report
- Resources
Objective
The purpose of this assignment is to get partial insight on which are the typical problems when developing a VLIW compiler and which are the factors to consider when deciding on a VLIW architecture.
Time allocation
4 hours (2 lab sessions) are allocated for this lab.
Theoretical background
You should review the folowing resources before you start working on this lab:
- Notes from the lecture on VLIW processors
Assignments
A typical compiler takes a program written in some high-level
language, and translates it to a machine language. As the development
of such a compiler is a task beyond the scope of this course, you will
perform some tasks of a simpler compiler, that translates a program
written in a machine language of a non-VLIW processor to a program
written in the machine language of a VLIW processor. We denote the
program with P and the VLIW processor
with V.
The data path of V is characterised by the following units.
alu_noarithmetic-logic units (ALUs)mul_nomultipliers-dividers (MULs)fpu_nofloating point units (FPUs)bau_noBus Access Units (BAUs)
Consequently, one very long instruction word will consist of the following instructions of P (the non-VLIW processor).
alu_noarithmetic/logic instructions ofPmul_nomultiply/divide instructions ofPfpu_nofloating-point instructions ofPbau_noload/store instructions ofP
One of the tasks of our imagined VLIW compiler is to pack
the instructions of a program written for P
into VLIW instructions to be run on V.
The packing has to be done considering the data dependencies between the instructions and the
resource constrains
(e.g. we are not allowed to pack more than
alu_no arithmetic/logic instructions into one VLIW instruction).
Here are the assignments you should work on:
-
Select a benchmark program (e.g., go.ss). Let us denote your chosen program with
p. -
Select 1 basic block, denoted with
bb, fromp, such thatbbcontains at least 15 instructions.
A help on the delimitation of basic blocks can be found on here. -
Define the architecture of the VLIW processor
Vby choosing the following numbers of units.- the number of ALUs, denoted with
alu_no - the number of MULs, denoted with
mul_no - the number of FPUs, denoted with
fpu_no - the number of BAUs, denoted with
bau_no
- the number of ALUs, denoted with
-
Pack the instructions of
bbinto VLIW instructions, such that the data dependencies and resource constraints are satisfied. - Explore the trade-off between cost (the more units you add to the VLIW, the higher the cost) and performance (the more units you add, the higher the chance that the basic block will run faster).
Preparation
For this assignment, you will be using the vliwc program.
Please first copy this tool into your local simplescalar/cde-root directory using the following command:
cp /courses/TDTS08/simplescalar/cde-root/vliwc ~/simplescalar/cde-root/vliwc
simplescalar/cde-root directory using the following command:
cp /courses/TDTS08/benchmarks/*.ss ~/simplescalar/cde-root/
Details
In order to select a basic block of a benchmark program, issue the following command line from ~/simplescalar/cde-root/ .
./vliwc <chosen_benchmark>
<chosen_benchmark> is the full path of the chosen benchmark program.
A list will be produced, It will produce a list of information of basic blocks, including
- the index number of a basic block
- the start address of the basic block
- the end address of the basic block
- the number of instructions contained in the basic block
You can sort the list, for example, in decreasing order of the instruction indices, using the following command line.
./vliwc <chosen_benchmark> | sort -nr +3 -4 | less
<chosen_benchmark> is the name of the chosen benchmark program.
Then you can choose an arbitrary basic block from the list. Remember to write down its index, start address and end address.
For example, you should issue the following command line to get the list of basic blocks of the go program.
./vliwc go.ss
1029 contains 15 instructions,
The basic block starts from address 0x00409870 and ends at address 0x004098e8.
In order to see the contents of the basic block, you will have to disassemble the benchmark program.
This can be done by using the following command line. Note that you should issue the command from the
simplescalar directory - not from simplescalar/cde-root.
./sslittle-na-sstrix-objdump -d <chosen_benchmark> | less
less, if you type / (slash),
you will be prompted for a pattern to be searched in the listing of less.
While being prompted, you should type in the start address of the chosen basic block.
If you do not reach that address from the first match,
you can type n for the next match, until you reach the start address of the chosen basic block.
Here is the obtained information for a sample basic block belonging to ijpeg.ss.
460880: 4c 00 00 00 mflo $6 460884: 00 06 00 00 460888: 4a 00 00 00 mfhi $3 46088c: 00 03 00 00 460890: 4f 00 00 00 andi $7,$9,65535 460894: ff ff 07 09 460898: 46 00 00 00 mult $6,$7 46089c: 00 00 07 06 4608a0: 55 00 00 00 sll $2,$3,0x10 4608a4: 10 02 03 00 4608a8: 4c 00 00 00 mflo $5 4608ac: 00 05 00 00 4608b0: 57 00 00 00 srl $3,$11,0x10 4608b4: 10 03 0b 00 4608b8: 50 00 00 00 or $3,$2,$3 4608bc: 00 03 03 02 4608c0: 5d 00 00 00 sltu $2,$3,$5 4608c4: 00 02 05 03 4608c8: 05 00 00 00 beq $2,$0,460910 <__udivmoddi4+0x600> 4608cc: 10 00 00 02
In order to pack the instructions, you need to determine the data dependencies. We neglect artificial dependencies, namely write-after-read (WAR) and write-after-write (WAW) dependencies, as we assume that a preprocessing can eliminate them. Therefore, you should focus ONLY on the read-after-write (RAW) dependencies. You can find descriptions on data dependencies from this web page.
In the presented example, instruction
460898: mult $6,$7
depends on the instructions 460880: mflo $6
and 460890: andi $7,$9,65535.
This is because
the mult instruction reads from $6 and from $7,
while the mflo instruction writes to $6
and the andi instruction writes to $7.
You can find the instructions and their semantics in the following resources.
- Appendix A of The SimpleScalar Tool Set.
Note that some of those "instructions" listed in the appendix are just
macros which expand to a couple of instructions.
For example, div is such a macro,
which first checks if divided-by-zero occurs, and only if not, performs the division thereafter.
ATTENTION: If you find an instruction in the output of sslittle-na-sstrix-objdump
but it is not listed in the appendix,
please ignore that instruction and consider it as if it did not depend on any other instructions.
It is relatively easy to detect RAW dependencies
between instructions which do NOT access the memory.
It is slightly trickier to detect RAW dependencies
between load/store instructions which access the memory,
because, at compile time, we do not know the target address,
which is very often the value of a register.
Therefore, in order to ensure the program correctness,
you have to capture the following two types of RAW dependencies
between load/store instructions.
- A load instruction should be executed only after all the store instructions which precede it in the program order have been executed.
- A store instruction has to be executed only after all the load and store instructions which precede it in the program order have been executed.
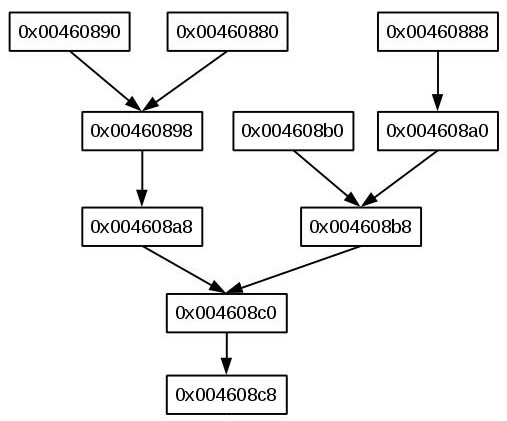
For the presented example, you can obtain the following dependency graph.
You can correct your assignment yourself, by using the vliwc program.
For that, you'll have to write two files,
the <graph_file> and the <vliw_file>,
described as follows.
- The
<graph_file>specifies the graph of data dependencies. - The
<vliw_file>specifies the way the instructions are packed into VLIW instructions.
Each line in the <graph_file> contains one or two instruction addresses
separated by blanks (space or tab).
If a line contains two addresses, this means that the instruction at the
second address depends on the instruction at the first address.
If an instruction does NOT depend on any other instructions,
then its address appears alone on a line.
NOTE: If you found blocks with very sequential executions from a benchmark three times in a row, then try to use another benchmark instead.
Moreover, if the majority of the block instructions are load/store try another benchmark (for example, ijpeg.ss has more ALU instructions).
The dependency graph depicted in the above figure can be described as lines of the <graph_file> as follows.
0x00460890 0x00460898 0x00460880 0x00460898 0x00460898 0x004608a8 0x004608a8 0x004608c0 0x004608c0 0x004608c8 0x00460888 0x004608a0 0x004608a0 0x004608b8 0x004608b0 0x004608b8 0x004608b8 0x004608c0
In order to pack the instructions such that they fulfill the resource constraints,
you should label each graph node with the type of resources it uses,
such as ALU, MUL, FPU, BAU, or none.
You can deduce the used types of resources from the following resources.
- Appendix A of The SimpleScalar Tool Set.
For the presented example, you can obtain the following labels:
mflo $6 none mfhi $3 none andi $7,$9,65535 ALU mult $6,$7 MUL sll $2,$3,0x10 ALU mflo $5 none srl $3,$11,0x10 ALU or $3,$2,$3 ALU sltu $2,$3,$5 ALU beq $2,$0,460710 ALU
You can specify your VLIW architecture and instruction packing
by means of the <vliw_file>.
The first line in the <vliw_file> consists of 4 integer numbers
separated by blanks (space or tab).
The 4 numbers represent the alu_no, mul_no,
fpu_no, and bau_no in this order.
Each of the subsequent lines consists of alu_no + mul_no + fpu_no +
bau_no atoms.
Each atom can be the address of an instruction or a nop.
The first alu_no atoms can be occupied
only by the addresses of the instructions labelled with ALU or none.
The next mul_no atoms can be occupied
only by the addresses of the instructions labelled with MUL or none,
and so on.
In the presented example, you may choose
2 ALUs, 1 MUL, 1 FPU, 1 BAU.
The <vliw_file> looks as follows.
2 1 1 1 0x00460890 0x004608b0 0x00460880 0x00460888 nop 0x004608a0 nop 0x00460898 nop nop 0x004608b8 0x004608a8 nop nop nop 0x004608c0 nop nop nop nop 0x004608c8 nop nop nop nop
Once you have created the <graph_file> and the
<vliw_file>,
you can check your solution by running the vliwc program using the following command line.
vliwc -b <chosen_basic_block_number>
-d <graph_file> -v <vliw_file>
<chosen_benchmark>
<chosen_basic_block_index> is the index number of the chosen basic block,
<graph_file> is the name of the graph file,
<vliw_file> is the name of the VLIW file,
and <chosen_benchmark> is the name of the chosen benchmark program.
The vliwc program will inform you
whether the dependency graph as well as the packing of instructions are correct.
It will also give the cost of your solution.
You need to explore different VLIW architectures
(choose different values for alu_no, mul_no,
fpu_no, and bau_no)
in order to optimise (minimise) the cost-performance indicator.
What to report
- Indicate the name of the benchmark program and the index number of the basic block you chose. The basic block has to contain AT LEAST 15 instructions.
-
The
<graph_file>and the<vliw_file>. - Some comments on the chosen architecture: which other architectures you have tried and what cost-performance ratios you have obtained.
-
If
vliwcsays that everything is fine, then believe it. If it says that something is wrong, but you still think that your solution is correct, then please add an explanation of your solution.
Resources
vliwcandsslittle-na-sstrix-objdumplocated in the directory/opt/simplescalar/simple-sim3.0.- D. Burger, and T. M. Austin, The SimpleScalar Tool Set, Version 2.0, 1997.
- T. M. Austin, A User's and Hacker's Guide to SimpleScalar Architectural Tool Set, 1997.
- William Stallings, Computer Organization and Architecture.
Page responsible: Zebo Peng
Last updated: 2024-08-26
