
Laboration 4: Rita diagram med matplotlib och strukturera kod
I laboration 4 kommer ni att få se hur Python kan användas för att rita diagram och skapa ett textäventyr.
I Del 1 läser ni in data från CSV-filer och ritar ut diagram med denna data. I Del 2 är er uppgift att öva på strukturera och dela upp kod.
Redovisning, inlämning och kompletteringar
- Information om den muntliga redovisningen, samt eventuella kompletteringar kan ni läsa om sidan Redovisning.
Checklista för redovisning
Innan ni påbörjar själva demonstration av er kod behöver ni se till att ni kan:
Förklara vad en virtuell miljö är, hur man importerar moduler, scope med avseende på variabler och utbrutna funktioner, samt skillnaden mellan föränderliga (mutable) och oföränderliga (immutable) värden.
- Del 1
- Demonstrera att Del 1, Uppgift 1 fungerar som den ska och går att köra som skript.
- Demonstrera att Del 1, Uppgift 2 fungerar som den ska och går att köra som skript.
- Peka ut i er kod hur kod från en annan fil importeras som modul och var en funktion från den importerade modulen körs
- Demonstrera att Del 1, Uppgift 3 fungerar som den ska och går att köra som skript.
- Del 2
- Demonstrera att Del 2, Uppgift 1 fungerar som den ska, visa något av de tillägg som ni gjort både vid demonstrationen och i koden.
- Visa att alla funktioner ni skapat har dokumentationssträngar (docstrings) som beskriver vad de gör.
Krav för godkänd kod
För både Del 1 och Del 2 ska koden följa koddispositionen nedan.
Del 1
- Uppgift 1: Körbart skript som tar en sökväg till en CSV-fil som argument och skapar en bild med ett diagram som visar innehållet i filen.
- Uppgift 2: Körbart skript som tar en sökväg till en CSV-fil som argument och skapar en bild med ett diagram som visar innehållet i filen. Samma data som i uppgift 1, men annat diagram produceras.
- Uppgift 3: Körbart skript som tar ett godtyckligt antal sökvägar till en CSV-filer som argument och exakt en bild med ett diagram som visar innehållet i alla filer. Välj mellan diagramtyperna från uppgift 1.
Del 2
- Uppgift 1: Det omstrukturerade skriptet genererar samma typ av äventyr som det ursprungliga skriptet. Koden har strukturerats om enligt stegen i uppgiften.
OBS! Uppgift 2-3 i del 2 är frivilliga.
Krav på koddisposition
För att göra det lättare att hitta i koden är det bör den följa en genomtänkt koddisposition. Er kod ska ha följande struktur (innehåll uppifrån och ner):
- import-satser
- eventuella globala konstanter
- funktionsdefinitioner
- övrig kod t.ex. anrop till en
main-funktion.
Se till att både funktionsnamn och variabelnamn är döpta på ett bra sätt, dvs:
- att de är beskrivande och reflekterar innehåll/funktion
- låt funktionsnamn vara verb och variabelnamn vara substantiv
- använd engelska namn
Alla funktioner ni skapat skall ha dokumentationssträngar (docstrings) som beskriver vad funktionen gör.
Skriv gärna kommentarer - det hjälper er både när ni skriver kod och när ni ska redovisa! Dessa bör helst vara på engelska men ni får inte underkänt för kommentarer på svenska.
Skript som körs i en virtuell miljö
När ni aktiverat den virtuella miljön (se
lektion 4)
kommer kommandot python3 att referera till python3 i den virtuella
miljön istället för python3 som systemet tillhandahåller.
Ni kan se sökvägen till ett kommando med hjälp av which. Så här ser det ut när
den virtuella miljön inte är aktiverad:
$ which python3
/usr/bin/python3
och så här ser det ut med den virtuella miljön aktiverad.
$ which python3
/courses/TDDE44/venv_lab4/bin/python3
För att rätt kommandotolk ska användas när man skapar ett körbart pythonskript är det för viktigt att man använder
1#!/usr/bin/env python3
som första rad i sina körbara pythonskript. Denna rad kommer att använda den python3 som är definierad av miljön, som t.ex. den i en virtuell miljö om en sådan är aktiverad.
Om man hårdkodar sökvägen till pythontolken som nedan
1#!/usr/bin/python3
så refererar man till den pythontolk som finns på exakt den sökvägen (och som kanske inte känner till en viss modul som vi vill använda oss), dvs skriptet struntar i om man t.ex. aktiverat en virtuell miljö.
Del 1
Läsa in data och rita ut eget diagram.
OBS! Om ni kör på LiUs Linux-miljö är det viktigt att ni använder den virtuella miljön för laboration 4, eller en egen virtuell miljö där ni installerat matplotlib
. Standardversionen i systemet är en äldre version (3.1.2) där till exempel ordningen på axlarna för ett diagram kan skilja sig från vad vi kan förvänta oss från nyare versioner (virtuella miljön kör 3.8.2).
Förberedelser
- Se till att ni aktiverat den virtuella miljön alternativt att ni har installerat
matplotlibom ni jobbar på egen dator (se lektionsmaterialet) - Gå igenom lektionsmaterialet
- Kopiera filerna från
/courses/TDDE44/kursmaterial/laboration4/del1till lämplig katalog - Om ni jobbar på egen dator kan ni ladda ner filer här.
Allmänna tips
Försök att dela upp uppgiften i delproblem och lös varje delproblem i en egen funktion. Exempel på delproblem:
- ladda in en fil
- räkna ut antalet koppar i snitt för ett klockslag
- plocka ut alla datapunkter för en dag
Egen modul med funktion för inläsning
För både Uppgift 1 och Uppgift 2 ska samma funktion användas för att läsa csv-data. För att slippa skriva om funktionen lägger vi den i en egen fil som importeras som en modul i Uppgift 1 och Uppgift 2.
Skriv load_csv
i filen common.py
Skapa en ny fil, common.py. I den skriver ni funktionen load_csv(filename)
som tar in ett filnamn och returnerar en lista med inläst data enligt nedan. Denna fil kommer ni kunna använda som en modul de följande uppgifterna.
CSV-filer
I /courses/TDDE44/kursmaterial/laboration4/del1 finns ett antal .csv-filer med påhittad data om kaffevanor hos ett antal kända forskare. Nedan ser ni innehållet i filen AdaLovelace.csv:
;Måndag;Tisdag;Onsdag;Torsdag;Fredag;Lördag;Söndag
8;1;1;0;1;1;0;0
9;0;0;1;0;0;1;0
10;0;0;1;0;0;1;0
11;0;0;0;0;0;0;0
12;0;0;0;0;0;0;0
13;0;0;0;0;0;0;0
14;0;0;0;0;0;0;0
15;0;0;0;0;0;0;0
16;0;0;0;1;0;2;3
17;1;1;2;0;1;1;0
18;1;0;0;2;1;1;2
Den första raden består av kolumnrubriker för efterföljande rader. Resterande rader innehåller först ett klockslag och sedan hur många koppar kaffe som (i det här fallet) Ada Lovelace dricker under den nästföljande timmen en viss dag. T.ex. så ser vi att hon drack tre koppar kaffe mellan kl. 16:00 och 17:00 på söndagar.
OBS! ; används som skiljetecken mellan de olika värdena i dessa filer.
Inläsning av data
Ett sätt att representera datat i python är att låta varje rad i
textfilen motsvara en lista. Den första raden i textfilen (";Måndag;Tisdag;Onsdag;Torsdag;Fredag;Lördag;Söndag") bör då således bli följande lista: ["", "Måndag", "Tisdag", "Onsdag", "Torsdag", "Fredag", "Lördag", "Söndag"]. Textfilen som helhet blir då en lista av listor.
Tänk också på att vid inläsning av data från en textfil så läses raderna in som just text, dvs som strängar. Om man vill räkna på datat bör värden som egentligen är heltal, även konverteras till heltal. Nedan ser ni hur datat från AdaLovelace.csv ser ut som en lista av listor med korrekt datatyp för alla
värden (radbrytningar tillagda för läsbarhet).
1[['', 'Måndag', 'Tisdag', 'Onsdag', 'Torsdag', 'Fredag', 'Lördag', 'Söndag'],
2 [8, 1, 1, 0, 1, 1, 0, 0],
3 [9, 0, 0, 1, 0, 0, 1, 0],
4 [10, 0, 0, 1, 0, 0, 1, 0],
5 [11, 0, 0, 0, 0, 0, 0, 0],
6 [12, 0, 0, 0, 0, 0, 0, 0],
7 [13, 0, 0, 0, 0, 0, 0, 0],
8 [14, 0, 0, 0, 0, 0, 0, 0],
9 [15, 0, 0, 0, 0, 0, 0, 0],
10 [16, 0, 0, 0, 1, 0, 2, 3],
11 [17, 1, 1, 2, 0, 1, 1, 0],
12 [18, 1, 0, 0, 2, 1, 1, 2]]
Fler funktioner i modulen (filen common.py)
Skulle ni upptäcka att det finns fler funktioner som skulle kunna användas i både Uppgift 1 och Uppgift 2, kan ni även lägga dem i common.py.
Uppgift 1: Diagram 1
Skriv ett skript som gör följande:
- importerar modulen
commonsom ni skrev tidigare (se föreläsning ang. import av egna moduler) - tar emot sökvägen till en
.csv-fil som argument - läser in data från
.csv-filen med hjälp av funktionenload_csvi modulencommon - använder funktionen
prepare_data1(data)för att bearbeta inläst data så att det kan ritas ut meddraw_diagram1(values)(punkt 4 nedan) - ritar ut ett diagram med data från
.csv-filen som sparas som enpng-fil med hjälp av funktionendraw_diagram1(values)
Exempelkörning
Nedan körs skriptet ni ska skapa i Uppgift 1 från terminalen. När det kört klart ska ett diagram för den anvisade CSV-filen ha skapats. Namnet på diagramfilen kan med fördel bygga på filnamnet som data lästes in ifrån, t.ex. AdaLovelace1.png för exemplet nedan.
$ ./skapa_kaffediagram1.py csv/AdaLovelace.csv
Om ni använder Windows och shebang-raden/annat krånglar, kan ni anropa skriptet med följande istället:
$ python3 skapa_kaffediagram1.py csv\AdaLovelace.csv
I ovanstående anrop antas alla .csv-filer ligga i en katalog som heter csv.
Skriv funktionen prepare_data1
Funktionen prepare_data1(data)
ska ta in csv-data som lästs in med funktionen load_csv
från er modul common
och returnera en nästlad lista som innehåller x-värden och y-värden för diagrammet som ska ritas i Uppgift 1. Ex: [ [ x1, x2, ... ], [ y1, y2, ... ] ]
Skriv funktionen draw_diagram1
Funktionen draw_diagram1(values)
ska ta in en nästlad lista på det format som prepare_data1(data)
returnerar. Funktionen ska rita diagrammet för Uppgift 1 (se nedan) och spara det som en fil.
Diagram för Uppgift 1
Datat i den inlästa filen behöver bearbetas lite innan det kan visas med ett linjediagram. I Uppgift 1 ska nedanstående diagram skapas:
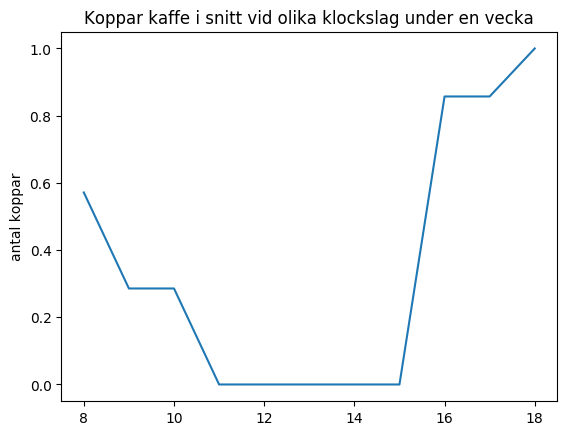
I diagrammet har de olika klockslagen samlats ihop i listan x_values
och snittet för de olika klockslagen under veckan har samlats ihop i listan y_values
. Diagrammet har sedan skapats med plt.plot(x_values, y_values)
.
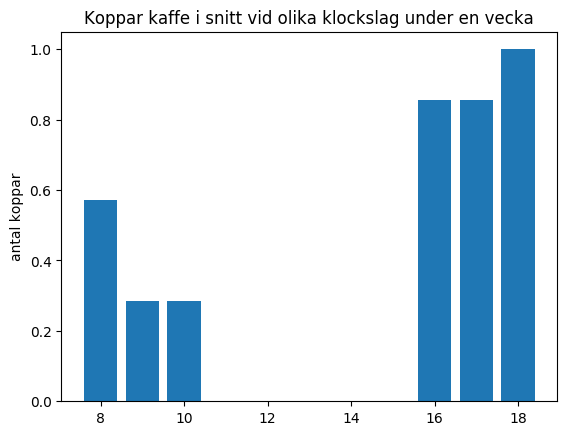
Variation
Det är tillåtet att presentera data i ett stapeldiagram istället. Använd då plt.bar(x_values, y_values)
istället:
Uppgift 2: Diagram 2
Skriv ett nytt skript (ny fil, inte samma som i Uppgift 1) som gör följande:
- importerar modulen
commonsom ni skrev tidigare (se föreläsning ang. import av egna moduler) - tar emot sökvägen till en
.csv-fil som argument - läser in data från
.csv-filen med hjälp av funktionenload_csvi modulencommon - använder funktionen
prepare_data2(data)för att bearbeta inläst data så att det kan ritas ut meddraw_diagram2(values)(se nedan) - ritar ut ett diagram med data från
.csv-filen som sparas som enpng-fil med hjälp av funktionendraw_diagram2(values)
Exempelkörning
Nedan körs skriptet ni ska skapa i Uppgift 2 från terminalen. När det kört klart ska ett diagram för den anvisade CSV-filen ha skapats. Namnet på diagramfilen kan med fördel bygga på filnamnet som data lästes in ifrån, t.ex. AdaLovelace2.png för exemplet nedan.
$ ./skapa_kaffediagram2.py csv/AdaLovelace.csv
I ovanstående anrop antas alla .csv-filer ligga i en katalog som heter csv.
Skriv funktionen prepare_data2
Funktionen prepare_data2(data)
ska ta in csv-data som lästs in med funktionen load_csv
från er modul common
och returnera en nästlad lista som innehåller x-värden och y-värden för diagrammet som ska ritas i Uppgift 2. Ex: [ [ x1, x2, ... ], [ y1, y2, ... ] ]
Skriv funktionen draw_diagram2
Funktionen draw_diagram2(values)
ska ta in en nästlad lista på det format som prepare_data2(data)
returnerar. Funktionen ska rita diagrammet för Uppgift 2 (se nedan) och spara det som en fil.
Diagram för Uppgift 2
Datat i den inlästa filen behöver bearbetas lite innan det kan visas med ett linjediagram. I uppgift 2 ska nedanstående diagram skapas:
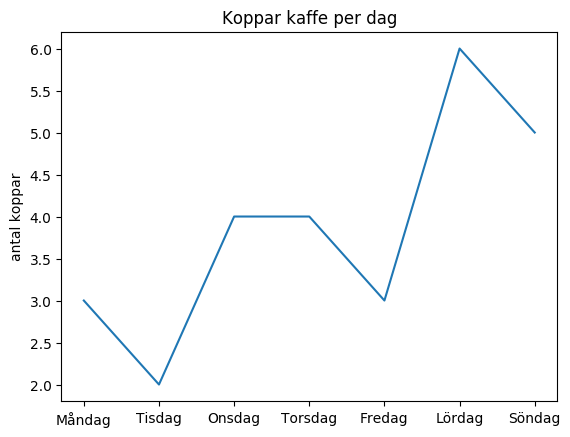
I diagrammet har dagarna samlats ihop i listan x_values
och det totala antalet koppar under varje dag har samlats ihop i listan y_values
. Diagrammet har sedan skapats med plt.plot(x_values, y_values)
.
Föränderliga datatyper
Värden av datatypen list
är föränderliga. Fler än en variabel kan referera till samma föränderliga värde. Inför redovisningen, se till att ni förstår vad detta innebär. Testa t.ex. nedanstående kod:
1data = common.load_csv('csv/AdaLovelace.csv')
2values1 = prepare_data2(data)
3print("Urpsrungligt värde på values1:", values1)
4
5values2 = values1
6values2[0][0] = "Monday"
7print("Ändrat värde på values2:", values2)
8print("Värde på values1 efter ändring av values2:", values1)
Uppgift 3: Skript som ritar ut diagram för flera filer
Uppgift 3 är i stort sätt samma som Uppgift 1 och 2 fast här ska alltså ett godtyckligt antal csv-filen kunna anges som argument och allas data ska visas i samma diagram.
Ni ska skriva ett nytt skript som gör följande:
- tar emot ett sökvägen till flera
.csv-filer som argument - läser in data från
.csv-filerna - ritar ut ett diagram med data från alla
.csv-filer.
Välj själva om diagrammet ska ha antal koppar eller dagar på x-axeln.
Återanvända funktioner från Uppgift 1/Uppgift 2
Återanvänd funktioner från skapa_kaffediagram1.py och skapa_kaffediagram2.py genom att importera dessa som moduler. Ni får inte kopiera kod från dessa till skapa_kaffediagram3.py.
När ni gör det är det viktigt att se till att ingen oönskad kod från tidigare uppgifter körs. Gör detta genom att ha koden som ska köras när dessa skript körs direkt från terminalen i en villkorssats som kontrollerar den aktuella namnrymden. Se bilder från föreläsning 4 för mer om detta.
1if __name__ == "__main__":
2 # kod som ska köras vid anrop som skript
Exempelkörning
I anropet kan wildcards användas. * står för noll eller flera av vilka tecken som helst. Om alla csv-filer ligger i katalogen csv skulle csv/* kunna användas för att få alla filer i den katalogen. Skulle det ligga filer i csv-katalogen som inte är csv-filer kan vi begränsa till enbart filer med filändelsen .csv i csv-katalogen genom att skriva csv/*.csv. Vill vi ha alla csv-filer som börjar på A i den katalogen vi står i blir det istället ./A*.csv. Observera att Python inte får själva stjärnan, utan det är skalet som expanderar argument som innehåller wildcards.
$ ./skapa_kaffediagram3.py csv/A* csv/C* csv/G*
I exemplet ovan kommer python att få alla filer som börjar på A, C eller G i csv-katalogen.
Windows - skriv ut sökvägarna till filerna istället
Tyvärr expanderar varken cmd.exe eller Powershell användning av wildcards som skalen till Unix-liknande system som Linux/macOS gör. Om ni ska skicka flera filer till ert skript i Windows får ni skriva ut sökvägarna till filerna istället:
$ skapa_kaffediagram3.py csv\AdaLovelace.csv csv\CeciliaPayneGaposchkin.csv csv\GraceHopper.csv
Diagram och svårighetsgrad
Här följer ett exempel där antal data från tre filer visas i samma diagram.
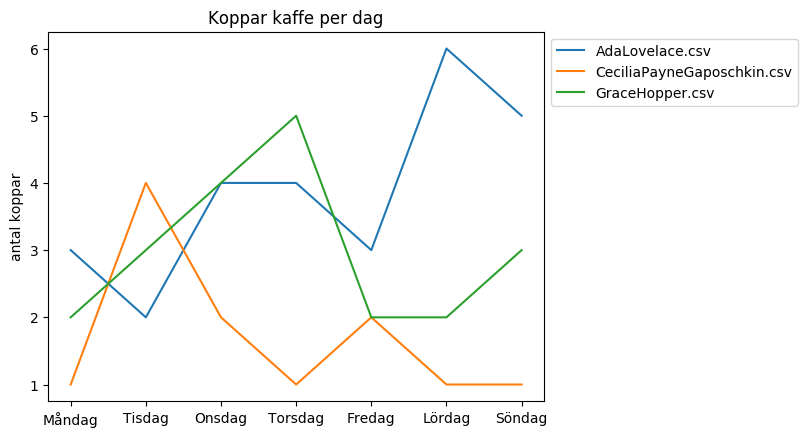
I exemplet ovan finns en teckenförklaring med. Detta blir svårare (eftersom ni måste ha koll på namnet på filen datat kommer ifrån) och det är frivilligt att ha med den.
Om ni skulle vilja ha med en teckenförklaring ritar ni linjerna med:
1plt.plot(x_values, y_values, label="namn på linje")
För att sedan visa teckenförklaringen använder ni:
1plt.legend(loc='upper left', bbox_to_anchor=(1, 0, 1, 1))
Ni kan läsa mer om teckenförklaringar här.
Om ni har med en teckenförklaring, men inte hela syns, lägg till bbox_inches="tight"
till ert anrop till plt.savefig
. Ni kan läsa mer om vad detta betyder
här.
Del 2
Uppgifterna i Del 2 är övningar i att bryta ut data och funktioner och att strukturera kod. Ni ska omstrukturera koden för ett textbaserat äventyrsspel så att det enkelt går att utöka/göra om det.
Förberedelser
Filen till uppgiften finns i katalogen /courses/TDDE44/kursmaterial/laboration4/del2. Kopiera adventure.py från katalogen till en egen katalog.
Läs igenom och testkör filen del2/adventure.py så att ni förstår vad som händer i filen. För att utföra uppgifterna behöver ni framförallt förstå koden i termer av
- Hur används de globala konstanterna
DESCRIPTIONSochOPTIONS - Hur sker flödet av output och input som styr spelet
Uppgift 1
I uppgift 1 ska ni strukturera den existerande koden i del2/adventure.py enligt stegen längre ner. Globala variabler får endast användas för konstanter.
Steg 1: Utöka/Ändra spelet
Utöka koden med fler if
-satser så att användaren får ett val då hen försöker smita förbi vakten ("Sneak"
) att antingen gå till höger eller vänster om vakten. I ett av fallen lyckas man och i ett av fallen misslyckas man.
Tänk på att ändra på alla ställen i if
-satsen där "Sneak"
förekommer.
Testa adventure.py för att försäkra er om att det fungerar.
Steg 2: Använd en main-funktion
Strukturera om adventure.py så att så gott som all kod efter funktionerna för utskrift av figurer ligger i en ny funktion med namnet main
. Glöm inte bort att anropa main
i slutet av filen.
Testa adventure.py för att försäkra er om att det fungerar.
Steg 3: Bryta ut data och funktioner i moduler
Lägg alla funktioner som skriver ut bilder i en egen fil pictures.py och importera den sedan som en modul. Tänk på att ev uppdatera anrop av dessa funktioner i adventure.py med rätt namnrymd/namespace (beroende på hur ni gör importen).
Lägg all data, dvs DESCRIPTIONS
och OPTIONS
, i en egen fil gamedata.py och importera den sedan som en modul. Tänk på att ev uppdatera referenser till dessa datastrukturer i adventure.py med rätt namnrymd/namespace (beroende på hur ni gör importen).
Testa adventure.py för att försäkra er om att det fungerar.
Steg 4: Skapa ny datastruktur för strukturen på äventyret, ADVENTURE_TREE
För att frigöra själva spelflödet från data vill vi skapa en ny datastruktur som beskriver äventyret i som en graf av tillstånd. Denna ska koppla samman ett tillstånd i DESCRIPTIONS
, t ex "Start"
, med de två valmöjligheterna i OPTIONS
, t ex "Red"
och "Blue"
.
De tillstånd som leder till att äventyret tar slut låter vi leda till tillståndet "End"
som får representera att spelet är slut (Game over) oavsett om slutet var bra eller dåligt.
Vi representerar detta i ett dictionary som
1{state_1: [option1, option2],
2 ...,
3 state_n : []}
t.ex.
1{"Start": ["Blue", "Red"],
2 ...,
3 "Attack": ["End"]}
Gå igenom if
-satsen och skapa en global variabel ADVENTURE_TREE
som ett dictionary i filen gamedata.py som innehåller tillstånden enligt strukturen ovan.
Här är en bild på en del av grafen för äventyret:

Ni bör inte ha ändrat något i koden under denna uppgift men testa för säkerhets skull adventure.py för att försäkra er om att det fungerar.
Att modellera ett problem genom att se det som att det är ett system som kan befinna sig i ett antal tillstånd och växla mellan dessa tillstånd är vanligt inom datavetenskap och visualiseras ofta med tillståndsdiagram. Ni kan läsa mer på t.ex. Wikipedia.
Steg 5: Använd ny datastruktur ADVENTURE_TREE
Nu är det dags att använda ADVENTURE_TREE
i adventure.py. Vår nya datastruktur ADVENTURE_TREE
beskriver vilka tillstånd som finns och hur dessa kan nås. Tanken med Steg 5 är lägga till kod som explicit håller koll på vilket tillstånd vi befinner oss i. I Steg 6 kommer vi sedan försöka korta ner koden vi får efter Steg 5.
I main
under den första print-satsen lägg till:
1# Vi börjar äventyret i tillståndet "Start"
2current_state = "Start"
3
4# Ta fram list över möjliga nästa tillstånd givet nuvarande tillstånd från
5# ADVENTURE_TREE
6succ_states = ADVENTURE_TREE[current_state]
Uppdatera koden så att den i varje villkorsgren ändrar på current_state
och succ_states
. Samt använder succ_states
för att ta fram alternativen som presenteras för användaren. Ändra också tilldelnigen av text_box
så att den använder current_state
och options
istället för text-strängar i .format
-anropet. Första villkoret bör blir något i stil med:
1if inp == "1":
2 # nästa tillstånd är det första tillståndet i succ_states
3 current_state = succ_states[int(inp)-1]
4 # uppdatera succ_states baserat på det nya current_state
5 succ_states = ADVENTURE_TREE[current_state]
6 text_box = "{}\n{} {}\n{} {}".format(DESCRIPTIONS[current_state],
7 "1", OPTIONS[succ_states[0]],
8 "2", OPTIONS[succ_states[1]])
9 print(text_box)
10 inp = input(">> ")
Gör dessa ändringar genomgående i alla if
-satser, där current_state
uppdateras utifrån inp
.
Testa adventure.py för att försäkra er om att det fungerar.
Steg 6: Funktion för att byta tillstånd
Med hjälp av en tillståndsmodell för äventyret, framträder ett tydligt mönster för hur programmet egentligen bara transporterar mellan olika tillstånd, och att det som utförs i ett tillstånd i stort sätt är samma sak varje gång.
get_next_state
Vi ska i Steg 6 skriva koden för detta mönster som funktionen get_next_state(state)
som får in ett tillstånd som sträng och ska returnera nästa tillstånd. Om det finns flera alternativ för vilket som ska bli nästa tillstånd ska användaren tillfrågas.
Om ni tittar på ADVENTURE_TREE
så ser ni att vi måste hantera två fall:
- om det endast finns ett möjligt nästa tillstånd (t.ex.
"Attack"->"End"), returnera det enda möjliga tillståndet direkt - om det finns flera alternativ, presentera dessa för användaren och returnera det alternativ som användaren valt. Använd
gamedata.OPTIONSför att beskriva alternativen för användaren.
Strukturen för get_next_state(state)
kan se ut så här:
- Hämta möjliga nästa tillstånd för
statefrånADVENTURE_TREE - Om det bara finns ett möjligt nästa tillstånd, returnera detta.
- Om det finns fler, presentera dessa för användaren, fråga efter ett val och returnera det tillstånd som användaren valt.
Vi har inte integrerat denna funktion i själva skriptet så att den anropas från main
, men ni kan testa (och ev. felsöka funktionen) genom att testa den i det interaktiva läget.
Kommentera ut anropet till main
så att det inte körs när ni bara vill testa. Om ni lagt anropet till main
“bakom” en if __name__ == "__main__"
kan ni alternativt starta python-tolken utan att ange fil och sedan importera adventure
(se nedan)
$ python3
>>> from adventure import *
>>> get_next_state("Start")
1 Blue
2 Red
>> 1
'Blue'
>>>
Ovan svarar vi 1 när funktionen ber oss välja mellan de två alternativen och så ser vi att funktionen returnerar 'Blue'
. Detta kan upplevas ytterligare lite tydligare om man använder ipython3 istället:
$ ipython3
In [1]: from adventure import *
In [2]: get_next_state("Start")
1 Blue
2 Red
>> 1
Out[2]: 'Blue'
In [3]:
Notera att den här situationen, när vi vill testa en enskild funktion i det interaktiva läget, är ett av undantagsfallen där det är rimligt att användafrom modulename import *
, något vi annars oftast bör undvika. (Här ser vi också en av fördelarna med att använda if __name__ == "__main__"
-konstruktionen. Vi vill ju kunna importera adventure
-modulen utan att main
-funktionen körs.)
Koppla ihop tillstånd med bild
Vi behöver också koppla bilderna till de olika tillstånden. Gör detta genom att skriva funktionen print_pic(state)
som får in ett tillstånd och sedan anropar rätt utskriftsfunktion. T.ex. om state
är "Start"
ska print_doors
anropas. Lägg print_pic
i pictures.py. Se också till att om state
är "End"
så ska print_game_over
anropas.
Vi kommer använda print_pic
i Steg 7 när vi kopplar ihop allt.
Vi kan även testa print_pic
på samma sätt som vi testade get_next_state
.
$ ipython3
In [1]: from adventure import *
In [2]: print_pic("End")
_____ __ __ ______ ______ ________ _____
/ ____| /\ | \/ | ____| / __ \ \ / / ____| __ \
| | __ / \ | \ / | |__ | | | \ \ / /| |__ | |__) |
| | |_ | / /\ \ | |\/| | __| | | | |\ \/ / | __| | _ /
| |__| |/ ____ \| | | | |____ | |__| | \ / | |____| | \ \
\_____/_/ \_\_| |_|______| \____/ \/ |______|_| \_\
In [3]: print_pic("Red")
| |
\ / \ /
-= .'> =- -= <'. =-
'.'. .'.'
'.'. .'.'
'.'.----^----.'.'
/'==========='\
. / .-. .-. \ .
:'.\ '.O.') ('.O.' /.':
'. | | .'
'| / \ |'
\ (o'o) /
|\ /|
\('._________.')/
'. \/|_|_|\/ .'
/'._______.'\ lc
In [4]:
Steg 7: En ny main-funktion
Döp om er main
-funktion till main_old
. Vi behåller den för tillfället så att vi kan titta på den, eller köra den för komma ihåg vad det var som hände i spelet.
Vi ska nu skriva en ny main
-funktion som använder get_next_state
. Vi låter den börja med att fråga efter användarens namn och sätta nuvarande tillstånd till "Start"
:
1def main():
2 name = input("What's your name?\n>> ")
3 print("Welcome {} to the adventure of your life. Try to survive and find \
4the treasure!".format(name.upper()))
5
6 current_state = "Start"
Lägg sedan till en loop som fortsätter så länge som current_state
inte är "End"
. I loopen behöver ni lägga till kod som tar hand om visning av bild och beskrivning baserat på nuvarande tillstånd och till sist anropar get_next_state
för att uppdatera current_state
.
Se till att “gameover”-bilden visas när spelet är slut.
Testa adventure.py för att försäkra er om att det fungerar.
Steg 8 Städa ev upp kod
Se till att koden i skriptet är prydligt disponerad, dvs att ordningen importer, funktioner, övrig kod följs.
Steg 9 Utöka/Ändra spelet
Ändra/Utöka koden så att användaren får flera alternativ då hen pratar med vakten (“Talk”), ett med positivt utfall och ett med negativt utfall.
Tänk på att ni behöver lägga till/ändra information i alla datastrukturer: ADVENTURE_TREE
, DESCRIPTIONS
och OPTIONS
Jämför hur lätt/svårt det är att göra denna ändring jämfört med det första steget i denna uppgift.
Uppgift 2 (frivillig)
Nu bör koden i adventure.py vara frikopplad från själva dialogen och figurer som skrivs ut.
Bygg ett nytt spel genom att skapa ny(a) fil(er). Ni kan t.ex. döpa dem till gamedata2.py och pictures2.py). Dela gärna med er av dessa filer med andra som läser kursen och provkör andra kursdeltagares spel.
Uppgift 3: Ytterligare möjliga förbättringar (frivilliga)
- Förbättra
get_next_stateså att den kan hantera godtyckligt många alternativ, dvs så att man iADVENTURE_TREEkan ha tillstånd med t.ex. tre eller fyra alternativ. - Lägg till ett tillstånd
"Win"(och byt ev. ut"End"mot"Lose") så att det går att skilja på slut där man vinner på något sätt och slut där man förlorar på något sätt. - Förbättra datastrukturen för äventyret så att allt ryms i ett dictionary.
- Spara data för äventyret i en JSON-fil och gör så man kan anropa spelet med namn på äventyrsfil som ska läsas in och köras.
- Spara textgrafiken till filer och lägg till information i speldatastrukturen om vilka bilder som ska visas när.
Sidansvarig: Johan Falkenjack
Senast uppdaterad: 2024-01-09