
Hands-On Sessions: RDF and Linked Data
Overview
The RDF and Linked Data related hands-on sessions are based on the Nobel Prize Laureates from 1901-2016 dataset (or, short, Nobel Prize dataset). You may take a look at the specification of this dataset or download an RDF dump of the dataset (14.8 MB).
Theme 1: SPARQL
In this hands-on, you will exercise the creation of SPARQL queries by writing queries over the Nobel Prize dataset to capture the following questions. To this end, we have set up a SPARQL editor that is connected to the dataset and, thus, allows you to test your queries.
- Question 1: List all Nobel Prize categories (hint: you are looking for everything of type
nobel:Category). - Question 2: List the names of all persons who won the Nobel Prize in Chemistry (hint: the full name of a Nobel Prize laureate can be accessed using the
foaf:nameproperty). - Question 3: Who won the Nobel Prize in Chemistry in 1911?
- Question 4: List the names of all persons who won the Nobel Prize in Chemistry, ordered by the year of the award.
- Question 5: List all female laureates (hint: the gender of a laureate can be accessed by using the
foaf:genderproperty). - Question 6: For all Nobel Prize laureates from 2000, list their name, date of birth, and date of death if the person has passed away (hint: use an
OPTIONALclause in your query). - Question 7: List all Nobel Prize laureates from Sweden or Finland (hint: use a
UNIONclause in your query). - Question 8: What is the birth year of persons who won the Nobel Prize in Chemistry? (hint: to obtain the birth year as a query variable you may use a
BINDclause with theyearfunction). - Question 9: What is the average age of persons who won the Nobel Prize in Chemistry? (note that this question is about the age the laureates had when they won)
- Question 10: For every Nobel Prize category, what is the average age of persons who won the Nobel Prize in the category?
Theme 2: RDF Triple Stores
In this hands-on, you will set up a triple store on your computer and load the Nobel Prize dataset. The triple store that we use is Blazegraph. To this end, please download Blazegraph (you need the file that is called blazegraph.jar).
Now, you can start up Blazegraph by executing the following command at the command line.
- java -server -Djetty.port=9999 -jar blazegraph.jar
- Question 1: List the laureate awards (given by their label) for which the description of the contribution contains the word "human".
- Question 2: List the laureate awards (given by their label) for which the description of the contribution contains the word "human" together with the word "behavior" (i.e., both words must be there).
- Question 3: For the laureate awards for which the description of the contribution contains the word "theory", list the ones that are the top-3 hits in the search (hint: you need to use
ORDER BYtogether withLIMIT).
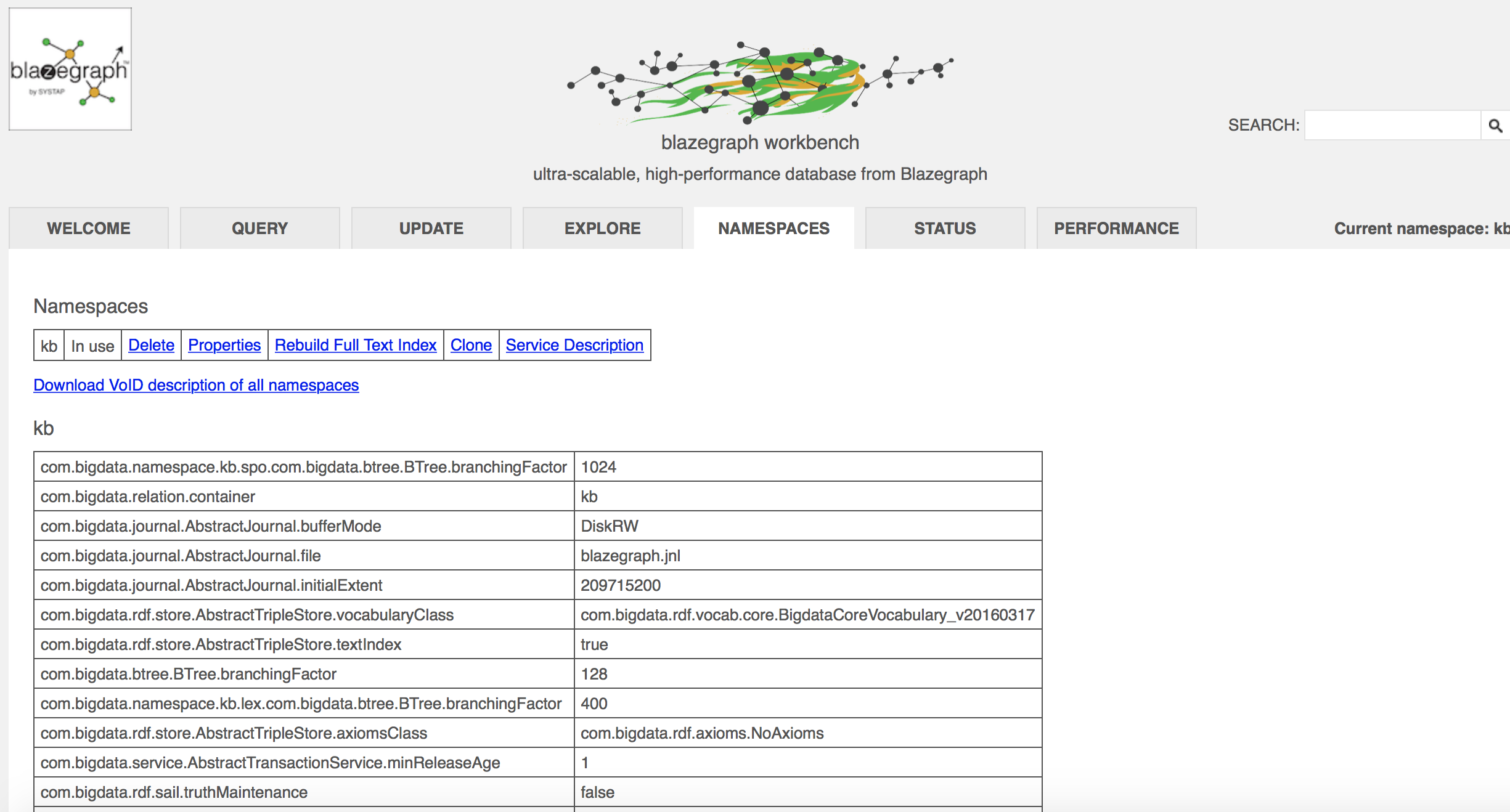
true, the full-text search should be enabled. Otherwise, you need to click "Rebuild Full Text Index."
Theme 3: Linked Data Publishing
In this hands-on, you will use Pubby to set up a Linked Data server for the Nobel Prize dataset on your computer. Note that Pubby retrieves the data that it returns in response to a URI look-up request by querying a SPARQL endpoint using SPARQL DESCRIBE queries. The Blazegraph server that you have set up during the second hands-on session provides a SPARQL endpoint for the Nobel Prize dataset that you have loaded. We will use this SPARQL endpoint as the back-end for Pubby. Hence, your Blazegraph server must be running for the following tasks to work correctly.
You also need a Java servlet container such as Jetty or Tomcat because Pubby runs as a servlet in such a container. If you do not have a Java servlet container on your computer that you can use, Jetty is a light option for you. Download the latest version Jetty and unzip (note that this version of Jetty requires Java 8; if you do not have it, download a version of Jetty for Java 7).
Next, download Pubby (use the latest version) and unzip. Now copy the 'webapp' directory of Pubby into 'webapps' directory of Jetty/Tomcat. Rename the resulting 'webapp' directory (inside the 'webapps' directory) to 'mydataset'.
Modify the configuration file of Pubby. The file is called 'config.ttl' and you find it in 'webapps/mydataset/WEB-INF/'. Use the following configuration (and adjust if needed).
<> a conf:Configuration;
# Project name for display in page titles
conf:projectName "My Test";
# Homepage with description of the project for the link in the page header
conf:projectHomepage <http://localhost:8081/mydataset/>;
# The Pubby root, where the webapp is running inside the servlet container.
conf:webBase <http://localhost:8081/mydataset/>;
# If labels and descriptions are available in multiple languages,
# prefer this one.
conf:defaultLanguage "en";
conf:dataset [
# SPARQL endpoint URL of the dataset
conf:sparqlEndpoint <http://127.0.0.1:9999/blazegraph/sparql>;
# Common URI prefix of all resource URIs in the SPARQL dataset
conf:datasetBase <http://data.nobelprize.org/resource/>;
# Will be appended to the conf:webBase to form the public
# resource URIs; if not present, defaults to ""
conf:webResourcePrefix "resource/";
# Fixes an issue with the server running behind an Apache proxy;
# can be ignored otherwise
conf:fixUnescapedCharacters "(),'!$&*+;=@";
] .
Now, start the servlet container. For instance, for Jetty, execute the following command (you should take care of the port you are using):
- java -jar start.jar jetty.port=8081
- http://localhost:8081/mydataset/resource/laureate/458
- http://localhost:8081/mydataset/resource/category/Peace
- curl -L -H "Accept: text/turtle" http://localhost:8081/mydataset/resource/laureate/458
- curl -L -H "Accept: application/rdf+xml" http://localhost:8081/mydataset/resource/laureate/458
-L parameter in the curl commands to observe what happens if curl does not automatically follow redirects in HTTP responses. Try also with an Accept header that requests text/html.
Page responsible: Olaf Hartig
Last updated: 2018-03-09
