Skeleton programming is an approach where an application is written
with the help of "skeletons". A skeleton is a pre-defined, generic component
such as map, reduce, scan, farm, pipeline etc.
that implements a common specific pattern of computation and data dependence, and
that can be customized with (sequential) user-defined code parameters.
Skeletons provide a high degree of abstraction and portability
with a quasi-sequential
programming interface, as their implementations encapsulate all
low-level and platform-specific details such as
parallelization, synchronization, communication, memory management,
accelerator usage and other optimizations.
 SkePU is an open-source skeleton programming framework for multicore CPUs
and multi-GPU systems.
SkePU is an open-source skeleton programming framework for multicore CPUs
and multi-GPU systems.
It is a C++ template library with six data-parallel
and one task-parallel skeletons, two generic container types, and
support for execution on multi-GPU systems both with CUDA and OpenCL.
Overview
Main features:
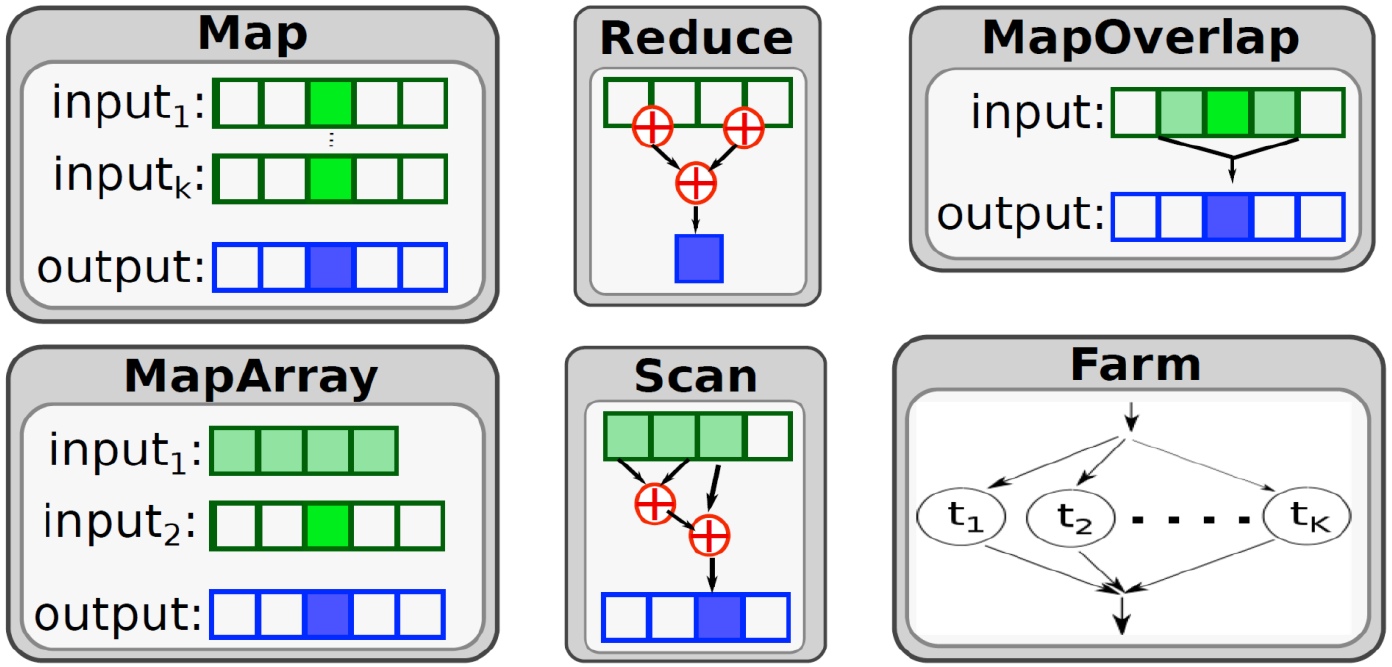
Supported skeletons: (some illustrations are given on the right for 1D operands)
- map (dataparallel elementwise application of a function
with arbitrary arity. Up to 3 operands
are currently supported, support for unlimited arity is under way),
- reduce,
- mapreduce,
- maparray (map with some replicated operand arrays),
- mapoverlap (stencil operation in 1D and 2D),
- scan (prefix-op), and
- farm (independent task farming with dynamic load balancing).
Multiple back-ends and multi-GPU support:
Each skeleton has several different backends (implementations): for sequential C,
OpenMP, OpenCL, CUDA, and multi-GPU OpenCL and CUDA.
There is also an experimental back-end for MPI
(which is not part of the public distribution below).
Tunable context-aware implementation selection:
Depending on
a skeleton call's execution context properties (usually, operand size),
different back-ends (skeleton implementations) for different execution unit types
will be more efficient than others.
SkePU provides a tuning framework that allows it to automatically
select the expected fastest implementation variant at each skeleton call.
Smart containers (Vector, Matrix)
for passing operands to skeleton calls:
Smart containers are runtime data structures wrapping operand data
that control software caching of operand elements
by automatically keeping track of the valid copies of their element
data and their memory locations. Smart containers can, at runtime,
automatically optimize communication,
perform memory management, and synchronize asynchronous skeleton calls
driven by operand data flow.
Hybrid execution (CPU, GPU) of skeleton calls using an overpartitioning
approach with dynamic heterogeneous scheduling (in the StarPU-integrated version)
SkePU comes in two different distributions:
(1) as a stand-alone version
which includes an off-line autotuning framework preparing for context-aware dynamic
selection of the expected fastest implementation variant at each skeleton call,
and
(2) as a version that is integrated with the
StarPU runtime system.
The latter version provides support for hybrid CPU+GPU execution,
performance-aware dynamic scheduling and load balancing.
Source Code and Documentation
Source code for SkePU 1.x is available on request
Last 1.x version: SkePU v1.2 (released 13/5/2015, latest patch 25/5/2015)
Standalone SkePU (Last updated 13/5/2015)
Major new features:
- Streaming support for CUDA GPU execution of most skeletons,
- MultiVector container for passing an arbitrary number of operands to MapArray,
- new example applications (e.g. Median Filtering),
- and a number of fixes e.g. in memory management.
See also the html documentation generated by doxygen.
- SkePU with StarPU integration, v0.8.1 (Last updated 13/5/2015)
- Updated and tested for StarPU 1.1.4 (latest stable StarPU version)
with CUDA/nvcc 5.0 and gcc 4.8.1.
See also the html documentation generated by doxygen.
Publications
2010
Johan Enmyren and Christoph W. Kessler.
SkePU: A multi-backend skeleton programming library for multi-GPU systems.
In Proc. 4th Int. Workshop on High-Level Parallel Programming and Applications (HLPP-2010), Baltimore, Maryland, USA. ACM, September 2010
(PDF)
Johan Enmyren, Usman Dastgeer and Christoph Kessler.
Towards a Tunable Multi-Backend Skeleton Programming Framework for Multi-GPU Systems.
Proc. MCC-2010 Third Swedish Workshop on Multicore Computing, Gothenburg, Sweden, Nov. 2010.
2011
- Usman Dastgeer, Johan Enmyren, and Christoph Kessler.
Auto-tuning SkePU: A Multi-Backend Skeleton Programming Framework for Multi-GPU Systems.
Proc. IWMSE-2011, Hawaii, USA, May 2011, ACM
(ACM DL)
A previous version of this article was also presented at:
Proc. Fourth Workshop on Programmability Issues for Multi-Core Computers (MULTIPROG-2011), January 23, 2011, in conjunction with HiPEAC-2011 conference, Heraklion, Greece.
Usman Dastgeer and Christoph Kessler.
Flexible Runtime Support for Efficient Skeleton Programming
on Heterogeneous GPU-based Systems
Proc. ParCo 2011: International Conference on Parallel Computing,
Ghent, Belgium, 2011.
(PDF)
-
Usman Dastgeer.
Skeleton Programming for Heterogeneous GPU-based Systems.
Licentiate thesis. Thesis No. 1504, Department of Computer and Information Science,
Linköping University, October, 2011
(LIU EP)
2012
Christoph Kessler, Usman Dastgeer, Samuel Thibault, Raymond Namyst, Andrew Richards,
Uwe Dolinsky, Siegfried Benkner, Jesper Larsson Träff and Sabri Pllana.
Programmability and Performance Portability Aspects of Heterogeneous
Multi-/Manycore Systems.
Proc. DATE-2012 conference on Design Automation and Testing in Europe,
Dresden, March 2012.
(PDF (author version),
PDF at IEEE Xplore)
Usman Dastgeer and Christoph Kessler.
A performance-portable generic component for 2D convolution computations
on GPU-based systems.
Proc. MULTIPROG-2012 Workshop at HiPEAC-2012, Paris, Jan. 2012.
(PDF)
2013
Usman Dastgeer, Lu Li, Christoph Kessler.
Adaptive implementation selection in the SkePU skeleton programming library.
Proc. 2013 Biennial Conference on Advanced Parallel Processing Technology
(APPT-2013), Stockholm, Sweden, Aug. 2013.
(PDF)
Mudassar Majeed, Usman Dastgeer, Christoph Kessler.
Cluster-SkePU: A Multi-Backend Skeleton Programming Library for GPU Clusters.
Proc. Int. Conf. on Parallel and Distr. Processing Techniques and Applications (PDPTA-2013), Las Vegas, USA, July 2013.
(PDF)
2014
Usman Dastgeer.
Performance-Aware Component Composition for GPU-based Systems.
PhD thesis, Linköping Studies in Science and Technology, Dissertation
No. 1581, Linköping University, May 2014.
(LiU-EP)
Christoph Kessler, Usman Dastgeer and Lu Li.
Optimized Composition: Generating Efficient Code for Heterogeneous Systems
from Multi-Variant Components, Skeletons and Containers.
In: F. Hannig and J. Teich (eds.), Proc. First Workshop on Resource awareness and adaptivity in multi-core computing (Racing 2014), May 2014, Paderborn, Germany, pp. 43-48. (PDF)
Usman Dastgeer and Christoph Kessler.
Smart Containers and Skeleton Programming for GPU-based Systems.
Proc. of the 7th Int. Symposium on High-level Parallel Programming and Applications (HLPP'14), Amsterdam, July 2014. (PDF slides)
2015
Usman Dastgeer and Christoph Kessler.
Smart Containers and Skeleton Programming for GPU-based Systems.
Int. Journal of Parallel Programming
44(3):506-530, June 2016 (online: March 2015), Springer.
DOI: 10.1007/s10766-015-0357-6.
2016
Oskar Sjöström, Soon-Heum Ko, Usman Dastgeer,
Lu Li, Christoph Kessler:
Portable Parallelization of the EDGE CFD Application for GPU-based Systems using the SkePU Skeleton Programming Library.
Proc. ParCo-2015 conference, Edinburgh, UK, 1-4 Sep. 2015.
Published in: Gerhard R. Joubert, Hugh Leather, Mark Parsons, Frans Peters, Mark Sawyer (eds.):
Advances in Parallel Computing, Volume 27: Parallel Computing: On the Road to Exascale,
IOS Press, April 2016, pages 135-144.
DOI 10.3233/978-1-61499-621-7-135.
Sebastian Thorarensen, Rosandra Cuello, Christoph Kessler,
Lu Li and Brendan Barry:
Efficient Execution of SkePU Skeleton Programs on the
Low-power Multicore Processor Myriad2.
Proc. 24th Euromicro International Conference on Parallel, Distributed,
and Network-Based Processing (PDP 2016),
pages 398-402, IEEE, Feb. 2016.
DOI: 10.1109/PDP.2016.123.
August Ernstsson, Lu Li, Christoph Kessler:
SkePU 2: Flexible and type-safe skeleton programming for heterogeneous parallel systems.
Accepted for HLPP-2016, Münster, Germany, 4-5 July 2016.
In press
Christoph W. Kessler, Sergei Gorlatch, Johan Enmyren, Usman Dastgeer, Michel Steuwer, Philipp Kegel.
Skeleton Programming for Portable Many-Core Computing.
Book Chapter, 20 pages, in: S. Pllana and F. Xhafa, eds.,
Programming Multi-Core and Many-Core Computing Systems,
Wiley Interscience, New York, accepted 2011, to appear, 2016 (?)
Code Examples
SkePU is a C++ template library targeting GPU-based systems that provides a higher abstraction level to the application programmer. The SkePU code is concise, elegant and efficient. In the following example, a dot product calculation of two input vectors is shown using the MapReduce skeleton available in the SkePU library. In the code, a MapReduce skeleton instance (dotProduct) is created which maps two input vectors with mult_f and then reduces the result with plus_f,
thus instantiating a dot product function.
Behind the scene, the computation can either run on a sequential CPU,
multi-core CPUs, single or multiple GPUs based on the execution configuration
and platform used for the execution.
#include < iostream >
#include "skepu/vector.h"
#include "skepu/mapreduce.h"
BINARY_FUNC(plus_f, double, a, b,
return a+b;
)
BINARY_FUNC(mult_f, double, a, b,
return a*b;
)
int main()
{
skepu::MapReduce <mult_f, plus_f> dotProduct(new mult_f, new plus_f);
skepu::Vector <double> v1(500,4);
skepu::Vector <double> v2(500,2);
double r = dotProduct(v1,v2);
std::cout <<"Result: " << r << "\n";
return 0;
}
// Output
// Result: 4000
Applications
Several test applications have been developed using the SkePU skeletons,
including
- a Runge-Kutta ODE solver
- separable and non-separable 2D image convolution filters
- Successive Over-Relaxation (SOR)
- Coulombic potential grid application
- N-body simulation
- LU Decomposition
- Mandelbrot fractals
- Smooth Particle Hydrodynamics (SPH, fluid dynamics shocktube simulation)
- Pearson Product-Moment Correlation Coefficient (PPMCC)
- Mean Squared Error (MSE)
- Median filtering
Their source code is included in the SkePU distribution.
Some Features
This section lists some results of tests conducted with several applications,
highlighting different performance-related aspects. For a comprehensive
description and evaluation of SkePU features and implementation,
see e.g. Chapters 3 and 4
of
Usman Dastgeers PhD thesis.
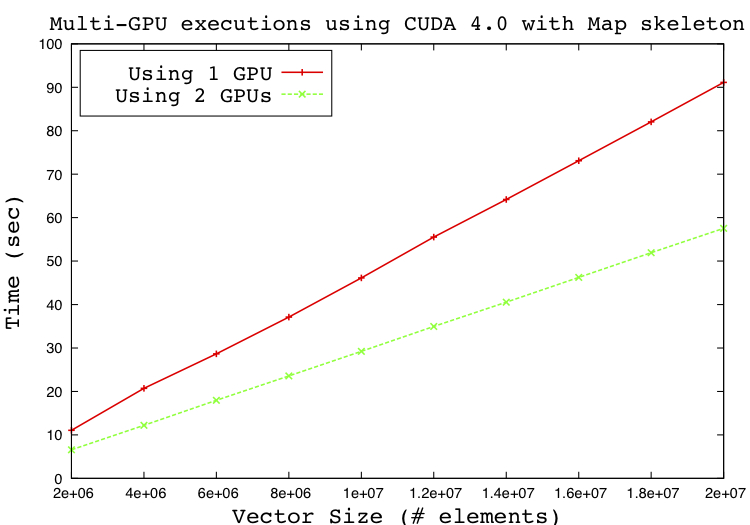
Multi-GPU Execution
SkePU supports multi-GPU executions using CUDA and OpenCL,
even with early CUDA versions.
With CUDA before version 4.0, the multi-GPU execution was
rather inefficient due to the threading overhead on the host side.
With CUDA 4.0 and later, it is possible to use all GPUs in the system concurrently
from a single host (CPU) thread. This makes multi-GPU executions using CUDA
a viable option for many applications.
In SkePU, support for multi-GPU executions is changed when using CUDA 4.0
to use single host thread. The diagram below compares execution on one
and two GPUs with SkePU multi-GPU execution using CUDA 4.0.
Auto-tuned context-aware back-end selection for skeleton calls
The stand-alone version of SkePU applies an off-line (deployment-time)
machine learning
technique to predict at runtime the fastest back-end for a skeleton call,
depending on the call context (in particular, operand sizes).
This includes the choice between a CPU implementation
(sequential or with multiple OpenMP threads), or between
CUDA resp. OpenCL with one or several GPUs. Even the number
of GPU threads and thread blocks can be tuned.
See the documentation and publications for further details.
The StarPU-integrated version of SkePU instead delegates the back-end selection
to the StarPU runtime system's built-in dynamic performance modeling and
tuning mechanism.
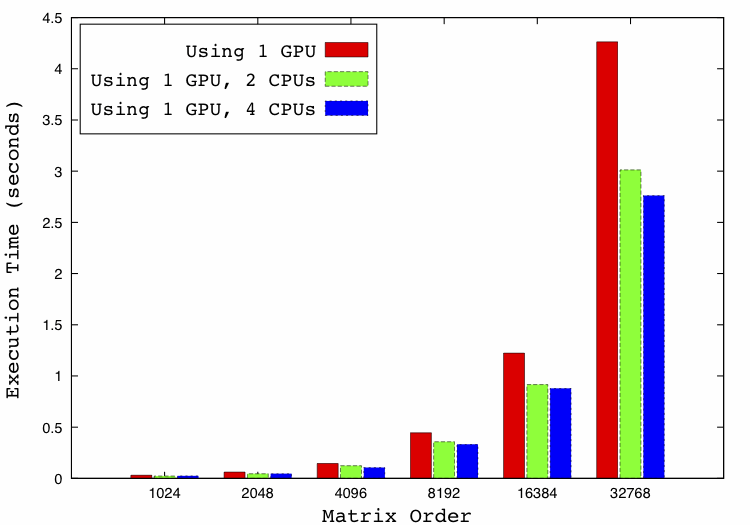
Hybrid Execution
When using SkePU with StarPU support, SkePU can split the work of one or
more skeleton executions into multiple tasks and use multiple computing devices
(CPUs/GPUs) in an efficient way.
The diagram below shows a Coulombic potential grid application execution
on a hybrid platform (CPUs and GPU) for different matrix sizes.
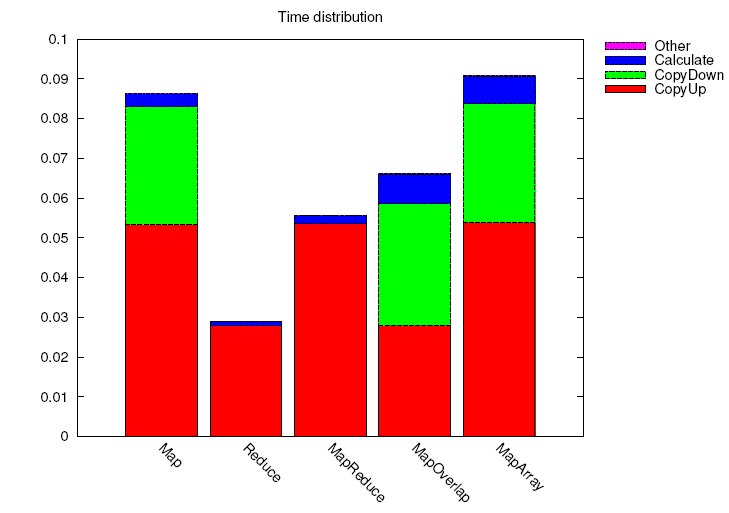
Smart Containers
The diagram to the right shows a breakdown of the execution time
for different SkePU single-skeleton computations coded in OpenCL,
showing PCIe memory transfer and kernel computation times.
It highlights the overhead for transferring data to (red) and from (green) GPUs
in relation to the kernel's computational work (blue).
In order to eliminate unnecessary data transfers across multiple
subsequent skeleton calls,
SkePU provides "smart containers"
for passing operands in generic STL-like data structures such as Vector and Matrix.
A smart container internally performs software caching of
recently accessed elements in various device memories and
reusing them in subsequent calls on the same device where applicable,
resulting in a run-time optimization of operand communication.
In particular, it implements a "lazy memory copying" technique,
transferring written elements back from device memory only if
accessed by the CPU after the call.
The smart container concept and implementation has been
revised in SkePU v1.1 (2014) compared to earlier versions.
The Vector and Matrix smart containers in SkePU v1.1 internally
implement a variant of the MSI coherence protocol,
providing sequential consistency (thus no need to
explicitly flush() device copies any more in a multi-GPU scenario).
For multi-GPU usage, it also supports direct GPU-GPU transfer
of coherence messages where available, and uses lazy
deallocation of device copies to reduce memory management overhead.
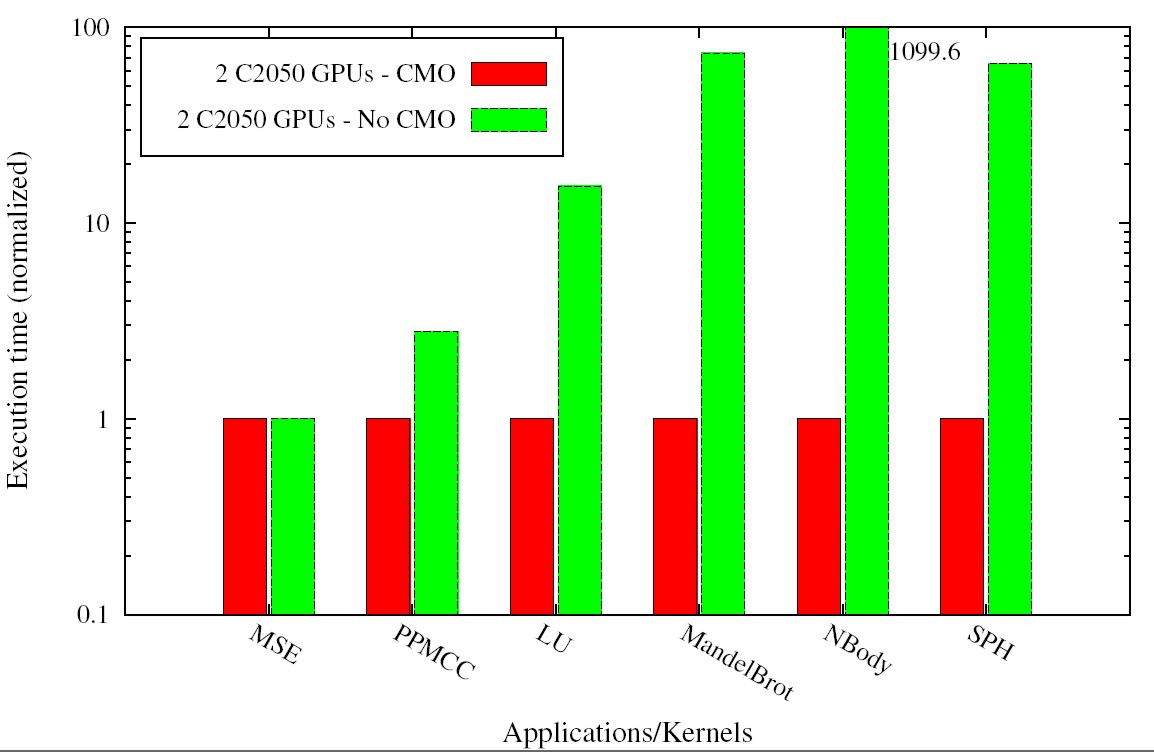
Smart containers can lead to a significant performance gain
over "normal" containers, especially for iterative computations
such as Nbody simulation or SPH where we observed speedups of
up to 3 orders of magnitude by using smart containers
instead of naive operand data transfer before and after each
kernel invocation. Some speedup results for a system with 2 GPUs,
averaged over many runs with different problem sizes,
are shown below to the right. For the details, see
the documentation and publications.
Performance Comparison
The diagram below shows the performance of the
dotProduct example
computed using different backends, highlighting performance differences
between different back-ends. Moreover, it compares with CUBLAS,
as the Multi_OpenCL MapReduce implementation of SkePU outperforms all
others in this case.
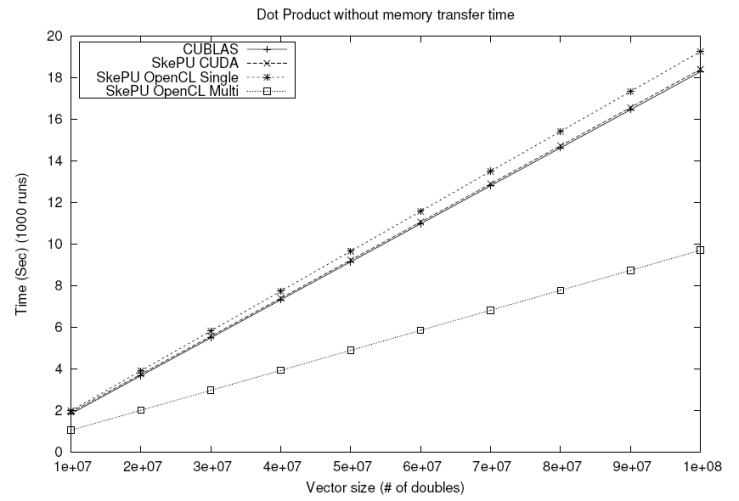
For more results, see the publications section.
Software License
SkePU is licensed under the GNU General Public License as published by
the Free Software Foundation (version 3 or later).
For more information, please see the license file included in the downloadable
source code.
Ongoing work
SkePU is a work in progress.
Future work includes adding support for more skeletons and containers,
e.g. for sparse matrix operations; for further task-parallel skeletons;
and for other types of target architectures.
For instance, there exists an experimental prototype with MPI backends,
allowing to run SkePU programs on multiple nodes of a MPI cluster
without modifying the source code (not included in the above public distribution).
If you would like to contribute, please let us know.
Contact
For reporting bugs, please email to "<firstname> DOT <lastname> AT liu DOT se".
Acknowledgments
This work was partly funded by the EU FP7 projects
PEPPHER and
EXCESS, and by
SeRC project OpCoReS.
Previous major contributors to SkePU include
Johan Enmyren and Usman Dastgeer.
The multivector container for MapArray, and the user guide have been added by
Oskar Sjöström.
Streaming support for CUDA in SkePU 1.2
has been contributed by Claudio Parisi from University of Pisa, Italy,
in a recent cooperation with the FastFlow project.
SkePU example programs in the public distribution
have been contributed by Johan Enmyren, Usman Dastgeer,
Mudassar Majeed and Lukas Gillsjö.
Experimental implementations of SkePU for other target platforms
(not part of the public distribution) have been
contributed e.g. by Mudassar Majeed, Rosandra Cuello and Sebastian Thorarensen.

