
Problemlösning
Konsten att lösa problem
Problemlösning är inte helt enkelt, vilket är ganska naturligt. Det finns dock några generella steg som man genomgår när man löser problem och detta brukar kallas problemlösningsprocessen.
George Polya (1945) skrev i How to solve it att det består av fyra steg:
- Förstå problemet
- Ta fram en plan
- Genomför planen
- Utvärdera lösningen.

Förstå problemet
- Kan du formulera om problemet med dina egna ord?
- Förstår du alla ord och begrepp i problemformuleringen?
- Vad vet du och vad är okänt?
- Finns det överhuvudtaget tillräckligt med information för att lösa problemet?
- Kan du rita en bild eller ett diagram som hjälper dig att förstå problemet?
- Vad är egentligen målet? Hur vet du när du är klar?
- Har du läst hela texten?
Ta fram en plan
- Gör ett försök och testa lösningen, och upprepa flera gånger.
- Jämför med lösningar på andra, gärna likartade, problem.
- Lös en mindre del eller en variant av problemet först.
- Dela upp problemet i mindre delar och lös varje del för sig.
- Formulera om problemet och ta fram en lösning som når målet, men inte på samma sätt som problemet är formulerat.
Genomför (implementera) planen
Allt är nu på plats, bara att implementera.
Utvärdera lösningen
- Kontrollera att lösningen är korrekt genom att jämföra den med det mål som uttrycks i problemet.
- Fundera över om lösningen kan användas för att lösa andra problem, antingen rakt av eller med mindre ändringar.
- Fundera över vad du har lärt dig. Vilken ny kunskap har du? Hur har din problemlösningsförmåga utvecklats?
Algoritmer
"An algorithm is an ordered set of unambiguous, executable steps, that defines a terminating process". Detta stämmer kanske inte riktigt överens med hur media ibland talar om algoritmer (som något som t.ex. bestämmer vad man ska se i sociala media), men det är den ursprungliga betydelsen och den som gäller inom datavetenskap.
Ett bra recept är alltså en sorts algoritm: Det innehåller ett antal steg som är tydligt beskrivna så att man kan förstå vad man ska göra, det går faktiskt att utföra stegen (i en lämplig ordning), och det finns inga steg som fortsätter i all oändlighet utan du som lagar maten blir så småningom klar (terminering). Här är ett exempel:
- Blanda mjöl och salt i en bunke. Vispa i hälften av mjölken och vispa till en slät smet. Vispa i resten av mjölken och äggen.
- Smält smöret i stekpannan och vispa ner i smeten. Stek tunna pannkakor av smeten i en stek- eller pannkakspanna.
- Servera med sylt, bär eller frukt.
Detta är inte en algoritm:
2 * 5.0Det är bara ett uttryck, inte en instruktion att göra något. Men följande programkod från labb 1 är en simpel algoritm, eller i alla fall en Python-specifik implementation av en simpel algoritm:
a=45
if a == 45:
print("yes")
else:
print("no")Bilden nedan illustrerar att vi går från en beskrivning av det önskade resultatet, till en steg-för-steg-beskrivning av hur man faktiskt utför detta (först multiplicera, sedan addera), till ett program i något väldefinierat programmeringsspråk.

Ett exempel på problem: TV-tittande
Tänk dig nu att du vill lösa ett problem relaterat till TV-tittande: Hur ska du hitta något bra att titta på (på vanliga "linjär-TV" utan streaming), och hur ska du bestämma dig för när det är dags att ge upp?
Du tänker vidare på detta och kommer fram till att du vill gå genom alla kanaler från början, och när det blir brus ("inga mer kanaler") ger du upp. Men du behöver göra de här vaga tankarna lite mer konkreta och specifika innan du faktiskt börjar skriva all kod för detta program (speciellt om du hade något lite mer avancerat än TV-tittande i åtanke). Annars är risken att det blir ett alldeles för stort hopp mellan (a) "lösa" och oprecisa ideer om hur man ska göra, och (b) den programkod du behöver skriva.
Vilka risker då? Jo, ju tidigare i programmeringsprocessen man upptäcker eventuella fel, desto mindre tid tar det att korrigera dem. Om vi har tänkt lite fel från början kanske vi spenderar veckor på att få den perfekta implementationen av en felaktig idé, och blir tvungna att slänga bort den skrivna koden.
Och hur minskar vi de här riskerna? Det finns flera alternativ som låter oss göra våra tankar mycket tydligare för oss själva utan att vi behöver gå hela vägen till programkod i Python.
Flödesschema för TV-tittande
Ett sätt att börja precisera tankarna är att rita upp vad algoritmen ska göra. Det kan man t.ex. göra med hjälp av ett flödesdiagram. Detta kan vara speciellt användbart när man vill hålla reda på olika former av villkor som behöver testas, och när man vill se att alla olika grenar i programmet tas omhand och leder till rätt plats.
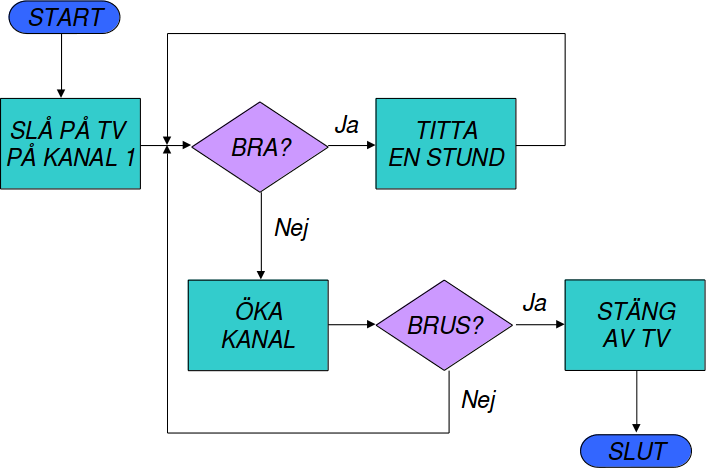
I diagrammet ovan kan det vara lättare att se om programmets flöde verkligen stämmer överens med det man vill göra. Ändå är det mycket enklare att rita detta än att skriva ett fullständigt program, inte minst för att man kan använda begrepp som "titta en stund" utan att behöva programmera detta.
Pseudokod för TV-tittande
Pseudokod är som namnet antyder inte riktig kod. Det är ett sätt att skriva kod ämnad åt människor istället för datorer och används för att beskriva algoritmer:
Slå på TV:n på kanal 1
Så länge det inte brusar
Så länge programmet är intressant
Titta en stund
Byt till nästa högre kanal
Slå av TV:n
Pseudokod kan skrivas på nästan vilket sätt som helst, så länge andra människor förstår koden.
-
Det går bra att använda kod som liknar satser i vanliga programspråk, till exempel if x == y eller for each x in y.
-
Man kan också skriva i ren text: remove smallest element from x.
-
Man kan använda matematiska termer: 2 * 5 mod 3.
Pseudokod kan fylla flera viktiga funktioner:
-
Det kan användas när man (som här) försöker utveckla en ny algoritm, för att man inte ska behöva tänka på alla programspråksdetaljer när man testar om den övergripande idén verkar fungera. En sats som remove smallest element from x är ju relativt otvetydig och lätt att förstå, även om vi ännu inte har bestämt (eller tagit reda på) hur detta faktiskt implementeras. Kanske man behöver iterera över listan x för att hitta en position för minsta elementet, och sedan radera elementet på den positionen, vilket kan ta flera rader kod. När vi utvecklar själva algoritmen kan vi undvika dessa detaljerade kodrader i vår pseudokod genom att lägga pseudokoden på en högre nivå av abstraktion.
-
Det kan användas för att beskriva en färdig, implementerad algoritm utan att man behöver använda ett specifikt programspråk som läsaren kanske inte förstår. Då vill vi se till att få med alla viktiga detaljer från den faktiska implementationen, som kanske ursprungligen skrevs i Python, C++, Ada, Java, eller något annat konkret programmeringsspråk. Pseudokoden blir alltså lika detaljerad som den verkliga implementationen, men håller sig till språkkonstruktioner som man kan förvänta sig att alla förstår. Det inkluderar både konstruktioner som liknar programkod och konstruktioner som helt enkelt beskrivs i ren text.
Pseudokod: Ett sidospår
Vi passar på att ta ett litet sidospår där vi tittar påståendet ovan:
"Pseudokoden (...) håller sig till språkkonstruktioner som man kan förvänta
sig att alla förstår". Varför måste man gå till någon sorts låtsasspråk
för att andra ska förstå? Räcker det inte att jag skriver program i mitt eget
favoritspråk? Det borde de väl förstå?
Här kan vi ta några exempel från Rosetta Code, som visar hur olika problem kan lösas i många olika språk. Alla dessa implementerar fakultetsfunktionen.
ABAP:
form factorial using iv_val type i.
data: lv_res type i value 1.
do iv_val times.
multiply lv_res by sy-index.
enddo.
iv_val = lv_res.
endform.
Ada:
function Factorial (N : Positive) return Positive is
Result : Positive := N;
Counter : Natural := N - 1;
begin
for I in reverse 1..Counter loop
Result := Result * I;
end loop;
return Result;
end Factorial;
ALGOL 68:
PROC factorial = (INT upb n)LONG LONG INT:(
LONG LONG INT z := 1;
FOR n TO upb n DO z *:= n OD;
z
); ~
AntLang:
factorial:{1 */ 1+range[x]} /Call: factorial[1000]
C++ med Boost:
#include <boost/iterator/counting_iterator.hpp>
#include <algorithm>
int factorial(int n)
{
// last is one-past-end
return std::accumulate(boost::counting_iterator<int>(1), boost::counting_iterator<int>(n+1), 1, std::multiplies<int>());
}Kotlin:
fun facti(n: Int) = when {
n < 0 -> throw IllegalArgumentException("negative numbers not allowed")
else -> {
var ans = 1L
for (i in 2..n) ans *= i
ans
}
}
fun factr(n: Int): Long = when {
n < 0 -> throw IllegalArgumentException("negative numbers not allowed")
n < 2 -> 1L
else -> n * factr(n - 1)
}PicoLisp:
(de fact (N)
(if (=0 N)
1
(* N (fact (dec N))) ) )
Rockstar:
Real Love takes a heart
A page is a memory.
Put A page over A page into the book
If a heart is nothing
Give back the book
Put a heart into my hands
Knock my hands down
Give back a heart of Real Love taking my hands
Ruby:
def factorial_iterative(n)
(2...n).each { |i| n *= i }
n.zero? ? 1 : n
endSelf:
factorial: n = (|r <- 1| 1 to: n + 1 Do: [|:i| r: r * i]. r) Övergripande lösningsmodeller
Ovanför algoritmnivån kan du behöva tänka på hur ett större program ska hänga ihop -- och då behöver du välja vilken ände du bearbetar först. Vi kommer att se på två lösningsmodeller: bottom-up och top-down.
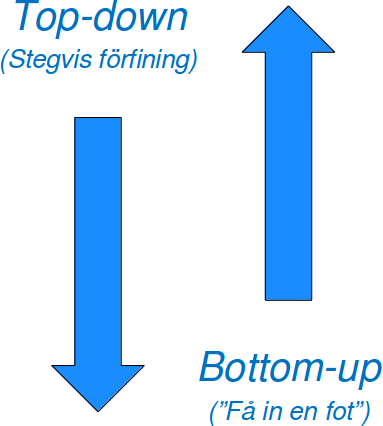
Programmering enligt top-down-modellen
-
Börja med att titta på problemet i helhet. Försök att dela upp det i mindre, namngivna, delproblem som kan lösas oberoende av varandra. Pseudokoden för TV-tittande är ett exempel: Den ger en övergripande struktur utan att ange exakt hur man byter kanal.
-
Specificera delproblemen, utan att skriva koden för dem. Vad ska funktioner ta för indata och vad ska de returnera? Delegera uppgiften att lösa delproblemen till någon annan, eller till dig själv vid en senare tidpunkt.
-
Med väl specificerade delproblem som är oberoende av varandra får man också en bra struktur på programmet. En del av programmet behöver inte känna till eller bry sig om resten (inga globala variabler, till exempel). Detta brukar på engelska kallas separation of concerns och är något man ofta vill sträva mot även om man inte tillämpar top-down-modellen.
Exempel
Vi vill ha ett program som kan simulera n slumpvandringar med k steg. Varje steg är en längdenhet och kan gå i en av fyra riktningar: vänster, höger, uppåt, nedåt.
För varje slumpvandring ska längden mellan start- och slutpunkten beräknas, och i slutet ska genomsnittet av alla längderna beräknas.
Detta är programmeringsövning 13 från kapitel 9 i läroboken och vi ska lösa detta problem steg för steg enligt top-down-modellen.
Slumpvandring
Huvudprogrammet
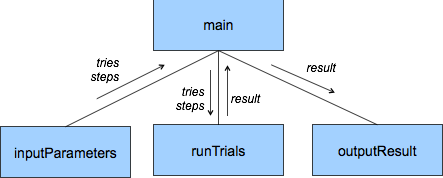
def main():
tries, steps = input_parameters()
result = run_trials(tries, steps)
output_result(result)Nu har vi en struktur för den översta nivån och vi kan se att koden verkar rimlig, så länge hjälpfunktionerna gör vad de ska.
Funktioner på andra nivån
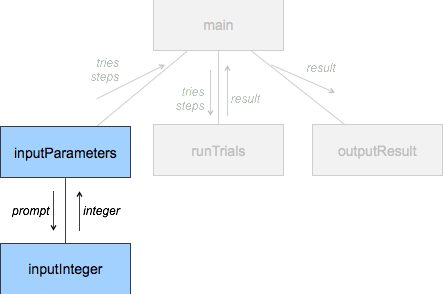
def input_parameters():
print("Welcome to the Random Walk Simulation Program!")
print("We will simulate n random walks of k steps on the blocks of")
print("a city street and output the mean distance travelled.")
print("-" * 50)
tries = input_integer("Enter number of tries (n): ")
steps = input_integer("Enter number of steps for each try (k): ")
return tries, steps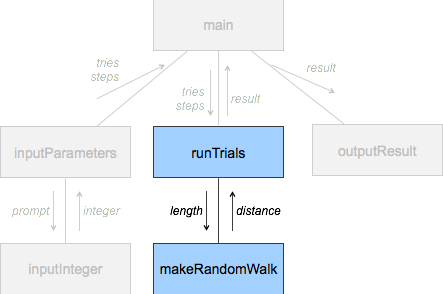
def run_trials(tries, steps):
total = 0.0
for i in range(tries):
length = make_random_walk(steps)
total += length
return total/tries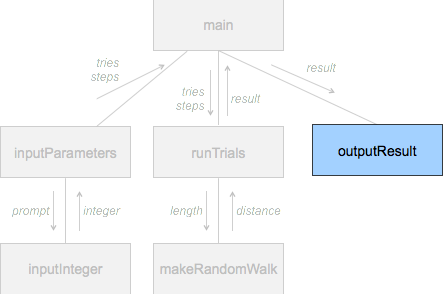
def output_result(result):
print("The mean distance in this simultation", result)Funktioner på tredje nivån
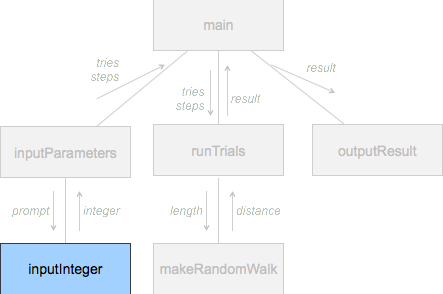
def input_integer(prompt):
while True:
str = input(prompt)
if str.isnumeric() and int(str) > 0: break
print("Please enter a positive integer!")
return int(str)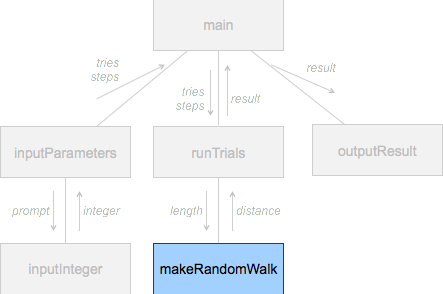
from random import randint
import math
def make_random_walk(steps):
x, y = 0, 0
delta = ((1, 0), (-1, 0), (0, 1), (0, -1))
for i in range(steps):
direction = randint(0, 3)
x += delta[direction][0]
y += delta[direction][1]
return math.sqrt(x * x + y * y)Exempel på körning
> python3 randomwalk.py
Welcome to the Random Walk Simulation Program!
We will simulate n random walks of k steps on the blocks of
a city street and output the mean distance travelled.
--------------------------------------------------
Enter number of tries (n): 100
Enter number of steps for each try (k): 15
The mean distance in this simulation: 3.142920319334164
Samma problem enligt bottom-up-modellen
-
Börja med att konstrura en funktion som kan göra någonting som verkar ha med problemet att göra. Utforma enhetstester och testa (och korrigera) funktionen tills den funkar. Börja med det som verkar lättast, svårast, viktigast eller liknande.
-
Bygg på med ytterligare funktioner, som också enhetstestas ordentligt, tills programmet löser hela problemet.
Exempel:
-
Om vi ska lösa det här problemet behöver vi ett sätt att mata in enskilda tal. Vi kan kalla funktionen för
input_integer. Vi skriver den funktionen, utan att se till hur den passar in i resten av programmet. Till skillnad från ren top-down-programmering har vi nu en kodsnutt som faktiskt kan köras och testas, men vi har mindre koll på dess användning i ett större sammanhang. -
Sedan behöver vi också kunna läsa in alla parametrar för lösningen. Vi kan skriva
input_parameters()som gör detta. Den baseras påinput_integer()som vi ju redan har skrivit, så vi kan testa den resulterande koden direkt.
Hybrid
I verkligheten använder man ofta en sorts hybrid av båda modellerna. Man löser sällan små delproblem strikt bottom-up utan att ha någon sorts idé om hur resten av programmet ska se ut, och man skriver sällan större program strikt top-down så att de inte kan köras eller testas förrän allt är klart ända ner till bottennivån. Istället kan man t.ex. göra en övergripande design av programmet, där man ser de viktigaste delarna. Delar kan sedan implementeras och testas för sig (t.ex. runTrials() och makeRandomWalk() utan inmatning), och sedan kombineras.
Algoritmkomplexitet
Vi vill gärna konstruera en algoritm som är så effektiv som möjligt (går snabbt och använder lite minne). Vi kan naturligtvis testa detta med olika verktyg, men vi kan också teoretiskt beräkna algoritmens komplexitet. Många gånger handlar det om att det någonstans i algoritmen finns en kostsam operation som man vill göra så få gånger som möjligt. Vi ska analysera ett sådant exempel.
Algoritm för att sy ett lapptäcke
Vi ska sy ett lapptäcke med 8 x 8 rutor som består av fyra olika färger arrangerade i mönstret nedan.

- Hur kan vi göra det så rationellt som möjligt?
- Vad är det för kostsam grundoperation som vi vill minimera?
- Hur många gånger behöver vi utföra operationen för att skapa ett lapptäcke med n x n rutor?
Låt oss säga att den kostsamma operationen är att göra sömmarna, medan t.ex. sprätta är enkelt. Låt oss också säga att det kostsamma i en söm är starten och slutet (positionering, avsluta sömmen) medan det inte spelar någon större roll hur lång själva sömmen är.
Algoritm 1
- Klipp ut 64 enskilda kvadrater.
- Sy ihop kvadraterna i 8 enskilda rader. Var och en av de 8 raderna kräver 7 sömmar.
- Sy ihop de 8 färdiga raderna med varandra. Detta kräver 7 sömmar.
För att få ett lapptäcke med sidlängd n krävs då n^2-1 sömmar.

Algoritm 2
- Klipp ut 16 remsor av storlek 4x1.
- Konstruera fyra kvadrater som innehåller fyra remsor vardera. Konstruera dem i olika ordning (remsor [1234], [2341], [3412], [4123]). Var och en av de 4 kvadraterna kräver 3 sömmar.
- Klipp isär de små kvadraterna till remsor på andra ledden (övre högra delen av figuren).
- Sy ihop de 16 remsorna. Detta kräver 15 sömmar.
För att få ett lapptäcke med sidlängd n krävs då (n/2) * (n/2-1) + (n/2)^2-1 sömmar.

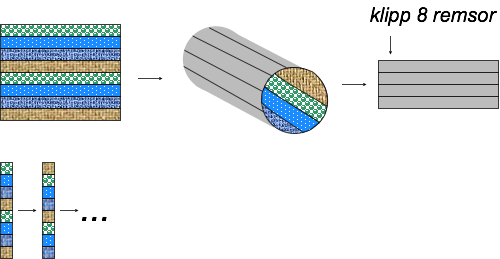
Algoritm 3
- Klipp ut 8 remsor av storlek 8x1.
- Sy ihop de 8 remsorna med mönstret [12341234].
- Sy ihop remsorna till ett rör (illustreras nedan med mönstret på insidan). Detta kräver 7 sömmar.
- Klipp röret 7 gånger för att få 8 cirklar.
- Sprätta en söm i varje cirkel, men på olika ställen. Detta ger 8 remsor som börjar med olika mönster.
- Sy ihop de 8 olika remsorna. Detta kräver 7 sömmar.
För att få ett lapptäcke med sidlängd n krävs då 2*(n-1) sömmar. Vi har "blivit av med kvadraten".
Tidskomplexitet för lapptäcksalgoritmer
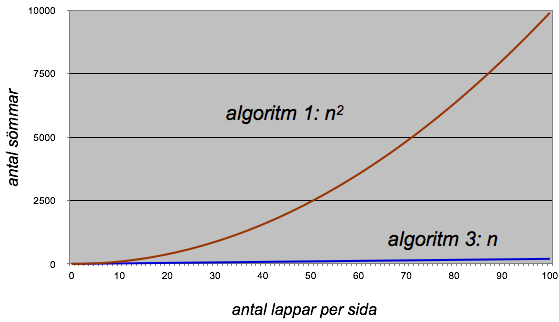
Men man ska inte dra detta alldeles för långt. En algoritm med lägre tidskomplexitet kan vara långsammare för tillräckligt små problem -- eftersom varje enskild operation kan tänkas ta längre tid. Algoritmen med högre tidskomplexitet kommer dock alltid att ta mer tid så snart problemet blir tillräckligt stort. Även om algoritmen med högre tidskomplexitet utför billigare operationer, kommer den så småningom (för tillräckligt höga n) att kräva så många fler operationer att den totalt sett tar mer tid.
I bilden nedan är algoritmerna lika snabba för n=10, och för problem som är mindre kan algoritmen som tar kvadratisk tid vara snabbare.
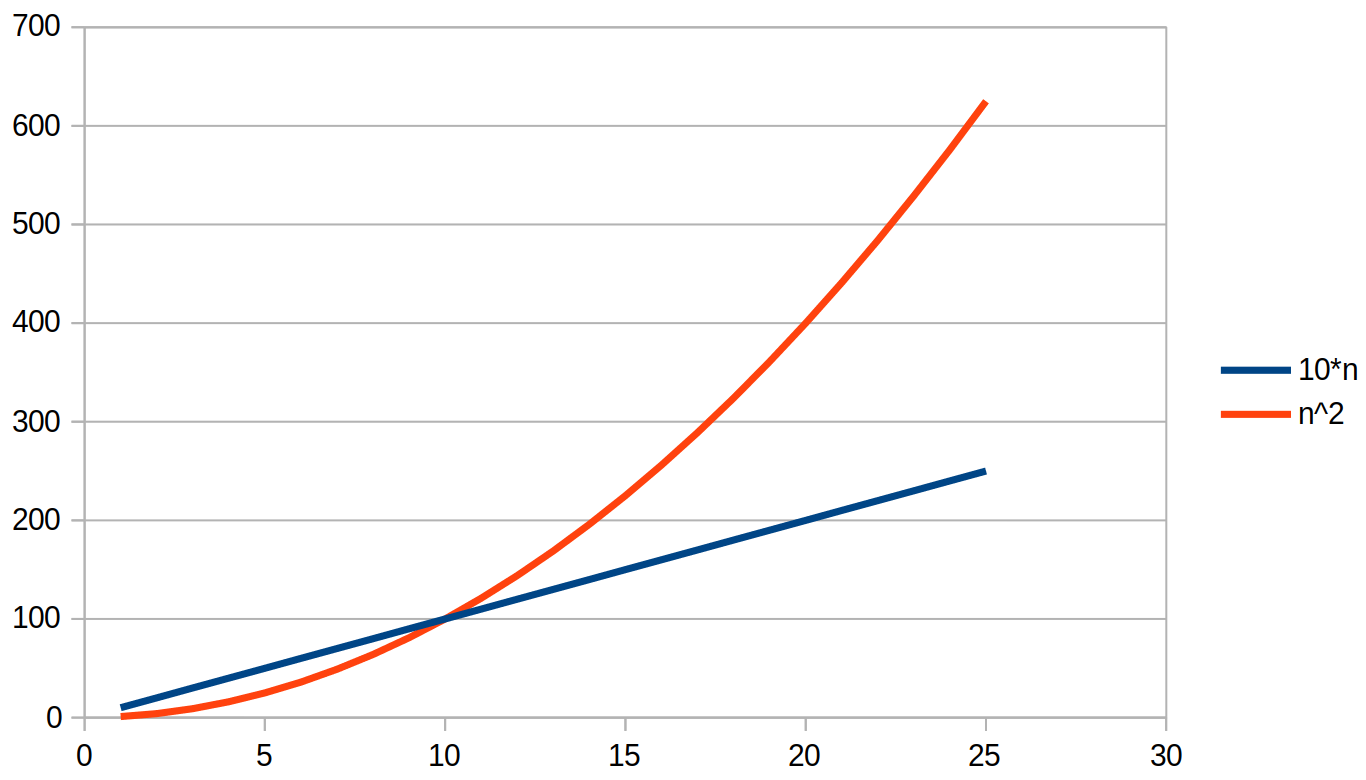
Tidskomplexitet i allmänhet
Det vi illustrerade ovan gäller också för många andra problem. Det finns till exempel sorteringsalgoritmer som för sortering av n element kräver n^2 operationer -- och andra algoritmer som klarar sig med n * log(n), vilket växer mycket långsammare när n blir stort.
Att lösa ett problem med en effektiv algoritm kan därför vara viktigare än att optimera implementationen ("kodningen") av en ineffektiv algoritm.
Sammanfattning
- Det finns ingen enkel metod som löser alla problem, men det finns många tips på strategier som kan funka i många fall.
- Två övergripande strategier är top-down och bottom-up.
- Algoritmer är generella beskrivningar av hur program kan funka. De kan uttryckas på flera olika sätt, t.ex. med pseudokod eller flödesdiagram. Redan innan vi har implementerat algoritmerna kan vi analysera deras komplexitet.
Sidansvarig: Peter Dalenius
Senast uppdaterad: 2021-12-03
