
Iteration och rekursion
Vi har tidigare använt upprepningar över tal med iteration (konstruktionen for) och rekursion (funktioner som anropar sig själva). Nu ska vi titta på metoder för att upprepa något för varje element i en lista.
Hur kan man tänka?
Iteration
Om man beräknar en funktion med hjälp av iteration har man hela tiden ett aktuellt delresultat. Man börjar med ett startvärde, och för varje steg uppdaterar man det nuvarande resultatet. Vi kan till exempel beräkna längden av en lista på följande sätt:
def length(seq):
result = 0
for element in seq:
result += 1
return resultVi börjar alltså med resultatet 0, och för varje element vi hittar i sekvensen adderar vi 1 till resultatet. Till slut returnerar vi resultatet.
Man kan också beräkna fakultetsfunktionen på följande sätt:
def factorial(n):
result = 1
for k in range(2, n+1):
result *= k
return result Här har vi börjat med resultatet 1, och sedan multiplicerat med alla tal mellan 2 och n, ett i taget.
Vi kommer att återvända till iteration senare, men först ska vi göra en djupdykning i rekursion.
Rekursion: Ett problem där det förenklar
Vi har tittat en aning på rekursion förut, men då i ett sammanhang där vi ville lösa ett problem som kunde lösas lika bra med iteration. Varför då? För många kan ju iteration verka lättare att förstå, så varför införa en metod till för att uppnå samma resultat?
Anledning 1 (överkurs): I vissa former av programmering kan det finnas fördelar med att rekursera istället för att iterera. Det kan till exempel handla om "ren" funktionell programmering där man av olika anledningar inte vill ha variabler som byter värden. I fakultetsfunktionen ovan får ju result nya värden hela tiden, men i den rekursiva implementationen nedan ändrar vi aldrig på värdet på någon variabel. När vi tilldelar result ett värde ändras detta aldrig.
def factorial(k):
if k == 1:
return 1
else:
result = k * factorial(k - 1)
return resultMen ren funktionell programmering (https://en.wikipedia.org/wiki/Purely_functional_programming) är överkurs i det här stadiet.
Anledning 2 (viktig!): I många lägen har man problem som faktiskt löses mycket enklare med rekursion än med iteration. Vi ska gradvis bygga upp ett sådant problem.
Tänk dig till exempel att vi har en vanlig lista med heltal och vi vill beräkna summan av alla tal i listan. Då kan vi göra så här med iteration:
def sum_of_flat_list(seq):
sum = 0
for element in seq:
sum += element
return sumNu gör vi problemet lite svårare: Vi har en lista som kan vara nästlad i en nivå. Vi kan t.ex. ha listan [1, 2, [3, 4, 5], 6, [7, 8]] eller listan [[12,34]]. Då kan vi summera så här:
def sum_of_two_level_list(seq):
sum = 0
for element in seq:
if isinstance(element, int):
sum += element
else:
# The element must be a nested list
for subelement in element:
# This element must be an int
sum += subelement
return sumSedan går vi över till listor i tre nivåer. Då ser koden ut så här:
def sum_of_three_level_list(seq):
sum = 0
for element in seq:
if isinstance(element, int):
sum += element
else:
# The element must be a nested list
for subelement in element:
if isinstance(subelement, int):
sum += subelement
else:
# The element must be a nested list
for subsubelement in subelement:
# This element must be an int
sum += subsubelement
return sumOch i fyra nivåer:
def sum_of_four_level_list(seq):
sum = 0
for element in seq:
if isinstance(element, int):
sum += element
else:
# The element must be a nested list
for subelement in element:
if isinstance(subelement, int):
sum += subelement
else:
for subsubelement in subelement:
if isinstance(subsubelement, int):
sum += subsubelement
else:
# The element must be a nested list
for subsubsubelement in subsubelement:
# This element must be an int
sum += subsubsubelement
return sumVi kan visserligen se ett mönster i koden, men den börjar ändå bli jobbigt att hålla koll på vad som händer.
Och vad ska vi göra om listan kan vara godtyckligt djupt nästlad? Det vill säga, tänk dig att vi inte vet i förväg om någon kommer att anropa listan med en lista av djup 3, eller 10, eller 200, eller 49152. Hur ska vi skriva koden så att den klarar av alla tänkbara fall? Vi kan ju inte nästla loopar hur länge som helst i koden!
Låter det som ett osannolikt problem? Det kanske det är om man bara tänker på listor av heltal. Men vi kan också tänka oss att man hanterar familjeträd där varje nivå i listan är en generation:
[person,
[child1,
[grandchild1, grandchild2, grandchild3]],
[child2,
[grandchild4,
[greatgrandchild1],
grandchild5, grandchild6]]
]Hur behandlar vi alla dessa utan att begränsa hur många generationer vi klarar av?
Det går att göra det på ett iterativt sätt, men det blir ganska krångligt att hantera. I stället kommer rekursionen till vår räddning! För summeringsproblemet kan vi skriva en rekursiv lösning så här:
def sum_of_any_level_list(seq):
sum = 0
for element in seq:
if isinstance(element, int):
sum += element
else:
# The element must be a nested list
sum += sum_of_any_level_list(element)
return sumVad händer då när vi själva anropar sum_of_any_level_list([1, 2, [3, 4, [5, 6]], 2, 1, 12, 4711, [[[[5]]]], 10]?
- Funktionen itererar (!) över elementen på högsta nivån.
- För varje element som är ett heltal adderas det heltalet till summan.
- De andra elementen är alltså nästlade listor. Vi behöver inte bry oss om hur djupt nästlade de är. Vi vet att de är listor, och att vi kan anropa oss själva för att beräkna deras summor. Vi anropar alltså t.ex.
sum_of_any_level_list([3, 4, [5, 6]]).- Då är vi i ett nytt anrop till funktionen, där den itererar (!) över elementen på den nuvarande högsta nivån: De 3 elementen
3,4, och[5,6].- För varje element som är ett heltal adderas det heltalet till summan.
- De andra elementen är alltså nästlade listor. (...)
- Då är vi i ett nytt anrop till funktionen, där den itererar (!) över elementen på den nuvarande högsta nivån: De 3 elementen
Som du förhoppningsvis ser slipper vi att själva nästla våra loopar: Vi kan alltid anropa oss själva, och detta nya anrop kan också anropa samma funktion, och detta anrop kan också anropa samma funktion... utan någon ändlig gräns för hur många gånger det kan ske. Vi har eliminerat behovet av att klippa och klistra massor av nivåer av loopar!
Notera att vi här har en äkta rekursiv lösningsmodell. Funktionen sum_of_any_level_list är specificerad så att den ska beräkna summan av alla heltal i en godtyckligt nästlad lista. Om vi då stöter på en nästlad behöver vi lösa exakt samma problem igen: Vi behöver (rekursivt) beräkna summan av alla heltal i denna godtyckligt nästlade lista. Det är då rekursion är en väldigt trevlig och användbar lösning.
Mer om rekursion på djupet senare!
I detta läge har vi ännu inte hunnit gå genom så mycket om nästlade datastrukturer. Därför kommer de flesta kommande exempel just nu att handla om rekursion som en ren ersättning till iteration, vilket också är bra att kunna -- och vi återkommer med mer exempel på rekursion över t.ex. nästlade listor och träd i ett senare skede.
Men vi ville ändå ta upp detta exempel för att ge ytterligare en motivering till varför rekursion är så viktigt!
I ett senare skede ska vi även titta på dubbelrekursion, vilket i princip betyder att vi använder rekursion både för att iterera "rakt fram" i en nästlad lista eller annan datastruktur (det som vi nu använde en for-loop till) och för att gräva oss djupare ner i nivåerna i strukturen.
Rekursion som ersättning för iteration
Rekursion handlar alltså om att definiera något i termer av sig själv. Om vi ska resa utomlands kan vi till exempel börja med att resa till flygplatsen, sedan resa med flygplan till nästa flygplats, och till sist resa från denna flygplats till hotellet. Vi bryter ner resan i mindre resor.
Om vi ska beräkna en funktion med hjälp av rekursion, handlar det också om att hitta delproblem som vi kan lösa på ett enklare sätt, och att kombinera ihop lösningarna för de delproblemen till en lösning för hela problemet.
Vi går tillbaka till problemet med att beräkna längden av en lista. Vad finns det för delproblem här? Ja, om listan är tom är ju längden 0. Och är den inte tom har vi minst ett element, kanske flera. I så fall:
- Längden av första elementet är 1. Det delproblemet har vi löst.
- Längden av hela listan utom första elementet är också ett mindre delproblem, och det delproblemet kan vi lösa genom rekursion.
def length(seq):
if not seq:
return 0
else:
rest_of_list = seq[1:] # Slicing!
return 1 + len(rest_of_list)Viktigt, men kanske svårt just nu: Återvänd i så fall till detta senare!
Vi påminner igen om att detta använder en rekursiv lösningsmodell för att det delproblem som det rekursiva anropet löser är av exakt samma form som det ursprungliga problemet: längden av en (del)lista. Ibland kan vi se funktioner som ser ut så här:
def length(seq):
return length2(seq, 0)
def length2(seq, length_before):
if not seq:
return length_before
else:
return length2(seq[1:], 1 + length_before)Vad gör då detta? Jo, det fungerar visserligen... men funktionen length2 returnerar inte längden av en lista. Den returnerar längden av en lista plus talet length_before. Vi får en sekvens av anrop som ser ut så här:
- anropa
length([1,2,3])- returnera
length2([1,2,3], 0)- returnera
length2([2,3], 1)- returnera
length2([3], 2)- returnera
length2([], 3)- returnera 3
- returnera alltså 3
- returnera
- returnera alltså 3
- returnera
- returnera alltså 3
- returnera
- returnera alltså 3
- returnera
Alla delanrop kommer att returnera 3, oavsett längden på listan som ges som parameter. De returnerar alltså inte svaret på ett äkta delproblem av den ursprungliga frågan! Detta implementerar istället en iterativ lösningsmodell där en ackumulerad längd hela tiden skickas vidare ner (0, 1, 2, 3) och där det slutliga värdet till slut returneras uppåt i anropskedjan igen.
Den rekursiva lösningens anrop ser istället ut så här:
- anropa
length([1,2,3])- returnera
1 + length([2,3])- returnera
1 + length([3])- returnera
1 + length([])- returnera
0(basfall)
- returnera
- returnera alltså 1
- returnera
- returnera alltså 2
- returnera
- returnera alltså 3
- returnera
I samtliga fall returnerar man längden av den lista man fick som parameter och löser ett problem av samma struktur som basproblemet -- alltså en rekursiv lösningsmodell.
I den här bilden illustrerar vi hur man räknar ut längden av listan ['a', 'b', 'c'] på ett detta sätt.
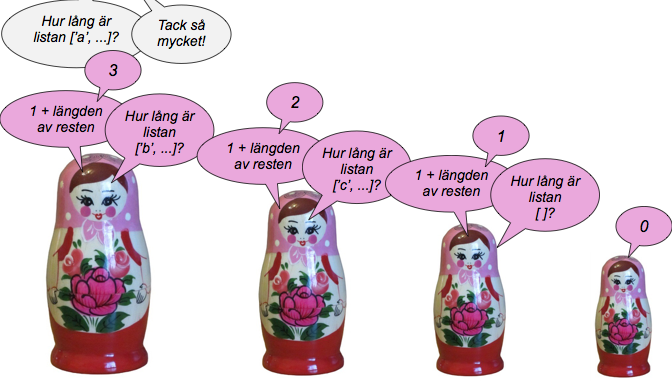
Att implementera en rekursiv funktion
Alla rekursiva funktioner har två krav på sig:
-
Rekursionen får inte fortsätta köras i all oändlighet, så den måste ha minst ett basfall där funktionen inte kallar på sig själv.
-
Funktionen måste ha någon möjlighet att kalla på sig själv. Annars är den ju inte rekursiv.
Om man dessutom ska använda en rekursiv lösningsmodell måste det rekursiva anropet lösa ett delproblem som är av exakt samma form som det ursprungliga problemet, så som vi har diskuterat tidigare.
Basfall
Det är oftast enklast att börja titta på basfallet hos en funktion. Tanken här är att vi vill hitta minst ett fall där beräkningen av returvärdet är trivial och där vi vill att upprepningen ska avslutas, till exempel tomma sekvensen i det tidigar exemplet. Ibland behöver man flera sådana fall.
Rekursionsfall
Rekursion är rätt så ointressant utan rekursionsfall, och de kan ofta vara svårare att hitta än basfallen. Här gäller det att hitta en liten, upprepningsbar del av problemet som kan utföras givet att någon annan (nästa rekursionsanrop) utför resten.
Exempel på rekursiva funktioner
För att se hur man väljer rekursions- och basfall ska vi titta på några exempel:
-
factorial: Fakultetsfunktionen som implementerades i kapitlet om upprepning -
list_lenberäkna längden på en lista -
find_vowels: hitta alla vokaler i en sträng -
find_min_max: Hitta största och minsta värdet i en lista -
list_contains_n: returneraTrueomnär i en lista, anarsFalse
factorial
Fakultetsfunktionen används ofta för att exemplifiera rekursion. Vi går in lite djupare på detta.
Definitionen av fakultetsfunktionen säger att n! är lika med produkten av alla positiva heltal mindre än eller lika med n. Alltså har vi till exempel 7! == 1*2*3*4*5*6*7.
Denna definition är i sig inte alls rekursiv. Den ger oss ju helt enkelt en lång lista av tal. Men vi kan se att 1*2*3*4*5*6*7 är samma sak som 1*2*3*4*5*6 gånger 7, och detta är ju faktiskt 6! * 7. Hurra! Vi löser problemet att beräkna 7! genom att först lösa ett delproblem, 6!, och sedan multiplicera svaret med 7.
Mer generellt kan vi då säga att n! = n*(n-1)!... utom när n==1, för då skulle det ju bli 1! = 1*0!, och 0! är inte definierat. Det var alltså där vi var tvungna att "stanna" i ett basfall.
Basfall
Basfallet blir alltså enligt ovan att 1! == 1.
def factorial(n):
if n == 1:
return 1
...Rekursionsfall
Som vi såg ovan hade vi n! = n*(n-1)! och detta blir vårt rekursionsfall.
def factorial(n):
if n <= 1:
return 1
else:
recursion_result = factorial(n-1)
return n * recursion_resultEftersom variabeln recursion_result bara används en gång kan vi förenkla
detta till
def factorial(n):
if n <= 1:
return 1
else:
return n * factorial(n-1)
list_len
Här dyker vi lite djupare ner i ett fall vi redan har diskuterat.
Basfall
Här vill vi välja indata som är enkel att hitta, och där vi direkt vet svaret. Efter lite fundering kommer man på att en tom lista altid har längden 0 och att man genom seq == [] eller not seq kan se om listan är tom.
def list_len(seq):
if not seq:
return 0
...Rekursionsfall
När vi inte har en matematisk definition får vi ta en annan väg till att hitta ett rekursionsfall. Vi vill hitta en liten del av uppgiften som kan göras enkelt, och sedan lösa resten av problemet genom rekursion.
Vi måste alltså komma på ett sätt att göra problemet att beräkna längden av en lista lite mindre så vi kan ge det problemet till nästa rekursion. Efter lite fundering kommer man fram till att längden av en lista är 1 + längden av listan utan första elementet.
Fullständiga koden blir alltså:
def list_len(seq):
if not seq:
return 0
else:
return 1 + list_len(seq[1:])
find_vowels
Basfall
Det kan vara intressant att försöka hitta en koppling mellan en iterativ implementation och valet av basfall. Studera därför följande iterativa version av find_vowels:
def find_vowels_iter(str):
result = []
for elem in str:
if elem in ['a','e','o'...]:
result += [elem]
return resultNu ska vi skapa en rekursiv version. Basfallet ska som bekant inte behöva någon upprepning och därför kan det vara en idé att undersöka hur den iterativa funktionen skulle bete sig om for-loopen togs bort. I det här fallet ser man ganska enkelt att funktionen skulle returnera
[].
Så vid vilka indata skulle vi få detta resultat? Genom att studera for-loopen kan man se att inga iterationer skulle köras om str är tom.
Basfallet till funktionen är alltså
def find_vowels(str):
if not str: # or str == ""
return []
...Rekursionsfall
Åter igen har vi en situation där vi om vi utför en liten del av uppgiften kan få resten av svaret tillbaka. När man har en sekvens av värden (t.ex. en lista eller en sträng) är det oftast en bra idé att behandla ett element och låta nästa rekursionsanrop ta hand om resten.
alltså vet vi att om vi kan skilja på vokal och konsonant så kan vi få alla vokaler från resten av strängen. Om bokstaven vi har är en vokal är det bara att lägga på den på listan, anars skickar vi bara listan vidare 'bakåt'. Här har vi alltså två fall som kan inträffa, antingen är första bokstaven en vokal, eller inte.
I python kan vi uttrycka det på följande sätt
def find_vowels(str):
if not str:
return []
# Since all branches use the result of the recursion, we can
# recurse here instead of in the if-statement
recurse_result = find_vowels(str[1:])
if str[0] in ['a', 'e', 'o'...]:
# Add the letter to the rest of the result
return recurse_result + [str[0]]
else:
# The current letter is not a vowel, just return the result of the recursion
return recurse_resultFör att få en känsla för vad rekursionen gör kan man använda följande figur där x-axeln är funktionsdjup och y-axeln är tid.

list_contains_n
Basfall
Det finns inget som säger att man bara kan ha ett basfall. När man letar efter ett element i en lista är det helt onödigt att leta i resten av listan om man hittar elementet en gång. list_contains_n borde alltså ha två basfall:
- Listan är tom ->
False - Första elementet är
n->True
def list_contains_n(n, seq):
if not seq:
return False
elif seq[0] == n:
return True
...Rekursionsfall
I funktionen list_contains_n har vi redan sett till att basfallet undersöker det nuvarande elementet och att vi kommit förbi basfallet betyder att nuvarande elementet inte är det vi letar efter. Det enda vi kan göra då är att gå vidare med rekursionen utan att göra några beräkningar.
def list_contains_n(n, seq):
if not seq:
return False
elif seq[0] == n:
return True
else:
return list_contains_n(n, seq[1:])
find_min_max
Efter de tidigare exemplen kan man kanske gissa att basfallet även här inträffar
när seq är tom. Det är delvis sant men det kan leda till problem. Fundera på
vad minsta och största värdet för en tom lista är. En första tanke skulle kunna vara
(0, 0), men det leder till lite problem. Vad händer om man i ett framtida steg
jämför (0,0) med 5? Största värdet blir rätt eftersom 5 > 0, men minsta
värdet blir fortfarande 0 eftersom 0 < 5.
Ett bättre antagande är att använda värdet (None, None) vilket även stämmer matematiskt.
Största och minsta värdet av en tom lista är ju faktiskt inget värde.
Vårat basfall blir alltså
def find_min_max(seq):
if not seq:
return (None, None)
...
find_min_max
Basfall
Än så länge ser vår funktion find_min_max ut så här:
def find_min_max(seq):
if not seq:
(None, None)
...Rekursionsfall
Som vanligt vill vi utföra en liten del av problemet och delegera resten till nästa rekursion. En enkel uppgift som kan lösas är ju att jämföra nuvarande element med min och max från resten av listan.
Vi börjar alltså med att hämta min och max för resten av listan, sedan jämför vi resultatet med nuvarande värdet och skickar tillbaka nya min och max:
def find_min_max(seq):
if not seq:
(None, None)
(min, max) = find_min_max(seq[1:])
if seq[0] < min:
min = seq[0]
if seq[0] > max:
max = seq[0]
return (min, max)Fundera nu på vad som händer om funktionen får listan [1].
Listan är inte tom, så den kommer att kalla på sig själv igen. Den här gången
är listan tom och None, None kommer att returneras. Första if-satsen kommer
att exekveras och seq[0] kommer att jämföras med None vilket kommer att
krasha programet.
Vi måste alltså göra en kontroll för om min och max är None, och i så fall ändra
dem till första värdet i listan. Funktionen skulle då se ut såhär:
def find_min_max(seq):
if not seq:
(None, None)
(min, max) = find_min_max(seq[1:])
if min is None or seq[0] < min:
min = seq[0]
if max is None or seq[0] > max
max = seq[0]
return (min, max)Vilket är en helt OK lösning.
Det finns dock en förbättring man skulle kunna lägga till. Istället för att jämföra
(min, max) med None i varje iteration kan man lägga till ett nytt basfall, len(seq) == 1.
och då returnera (seq[0], seq[0]). Inget rekursionsanrop skulle då nå det första basfallet
utan stanna på len=1 och altid få en siffra att jämföra med. Koden skulle då se ut såhär:
def find_min_max(seq):
if not seq:
(None, None)
elif len(seq) == 1:
(seq[0], seq[0])
(min, max) = find_min_max(seq[1:])
if seq[0] < min:
min = seq[0]
if seq[0] > max
max = seq[0]
return (min, max)En annan form av rekursion
Tidigare tittade vi på denna rekursiva implementation av factorial:
def factorial(n):
if n <= 1:
return 1
else:
return n * factorial(n-1)Nu skriver vi en annan variant som också anropar sig själv:
def factorial(n):
return factorial2(n, 1)
def factorial2(n, product_so_far):
if n <= 1:
return product_so_far
else:
return factorial2(n-1, n * product_so_far)Om vi nu anropar factorial(7) händer följande:
- factorial(7) anropar factorial2(7, 1)
- factorial2(7, 1) anropar factorial2(6, 7)
- factorial2(6, 7) anropar factorial2(5, 42)
- factorial2(5, 42) anropar factorial2(4, 210)
- ...
Detta är bara rekursivt i den tekniska bemärkelsen att funktionen anropar sig själv. Det vi "missar" är att vi inte först beräknar lösningen till ett eller flera delproblem och sedan kombinerar ihop de lösningarna när vi är på väg "uppåt" ut ur funktionen, vilket är den vanliga rekursiva lösningsmetoden. Istället beräknar vi ständigt nya värden som vi skickar "nedåt" till den anropade funktionen.
Detta är inte nödvändigtvis fel i sig, men det är en en iterativ lösningsmetod även om den är rekursivt implementerad.
Iterativ upprepning
Python, och många andra programmeringsspråk har två sätt att upprepa något. for
som ni sett tidigare i kapitlet om upprepning, och while.
for
For-loopar kör en gång för alla element i en iterator. Iteratorer är relativt komplexa men för den här kursen räcker det med att veta följande:
- En iterator är en sekvens av värden
- En lista konverteras automatiskt till en iterator
-
range()funktionen returnerar en iterator
Syntaxen för en for-loop ser ut på följande sätt:
for elem in iterator:
do_something(elem)Om iterator är en lista kommer elem tilldelas varje värde i listan ett efter ett.
För er som är vana vid java eller C (for(int i = 0; i < n; i++))
I Java kunde man från början inte skriva for elem in list, utan fick en vana
att alltid använda indexering för att komma åt elementen i listor. I vissa
andra språk i "C-familjen" gäller detta fortfarande.
Även om det fungerar så är det inte rätt sätt att göra det i Python.
I java:
for (int i = 0; i < iter.length; i++) {
System.out.println(iter[i])
}Vad många försöker i Python:
for i in range(0, len(iter)):
print(iter[i])Det fungerar för vissa typer av behållare, som listor, men det är mer "pythoniskt" att göra på detta sätt, vilket även fungerar med t.ex. mängder där inga index existerar:
for elem in iter:
print(elem)Om man även vill få ut ett index kan man göra så här:
for index, elem in enumerate(iter):
print(elem)While
Ett annat sätt att göra upprepning i Python är med en while-loop. Som namnet
antyder gör den något så länge ett krav är uppfyllt.
current = 5
factorial = 1
while current > 0:
factorial = factorial * current
current = current - 1
print(factorial)
# > 120Om man jämför med for blir det en del extra kod. Den räknare som vi använder, i det här fallet current, måste vi först initialisera och sedan förändra i varje varv. Å andra sidan kan vi med while styra mer exakt vad som händer i början och slutet av upprepningen.
break och continue
Ibland vill man avbryta en loop i förtid, eller hoppa över ett visst element. För
det har python nyckelorden break och continue.
break avslutar körningen helt och fortsätter efer loopen.
continue avslutar nuvarande iterationen och går vidare till nästa.
Exempel på använding av break:
# Find the index of `needle` in `seq`
result = None
# Iterate over all elements in seq
for i in range(len(seq)):
if seq[i] == needle:
result = i
# Since we found needle, there is no reason to keep iterating, break
breakExempel på använding av continue
def search_for_primes(min, max)
# Go through all the numbers between min and max
for i in range(min, max):
# Even numbers can not be primes, skip them
if is_even(i):
continue
do_expensive_prime_calculation()Mallar för iteration
Vi ska titta på några typiska situationer där man använder upprepning. Dessa kan fungera som mallar när man vill göra liknande saker. Det finns en tydlig poäng med att följa ett mönster, eftersom det ökar kodens läsbarhet. Självklart fungerar inte mallarna alltid så det räcker inte att bara lära sig några mallar.
Loop med vaktpost (eng. sentinel loop)
def average():
""" Calculates and prints the average value of integers given as input """
input_sum = 0.0
count = 0
x = int(input("Enter a number (negative to quit): "))
while x >= 0:
input_sum += x
count += 1
x = int(input("Enter a number (negative to quit): "))
print("The average is ", input_sum / count)>>> average()
Enter a number (negative to quit): 3
Enter a number (negative to quit): 12
Enter a number (negative to quit): 4
Enter a number (negative to quit): -1
The average is 6.333333333333333Loop med test i slutet
def input_positive():
""" Returns a positive integer given as input """
while True:
string = input("Enter a positive number: ")
if string.isnumeric() and int(string) > 0:
break
return int(string)>>> input_positive()
Enter a positive number: abc
Enter a positive number: -45
Enter a positive number: 0
Enter a positive number: 23.45
Enter a positive number: 4
4Loop med test i mitten
def input_positive():
""" Returns a positive integer given as input """
while True:
string = input("Enter a positive number: ")
if string.isnumeric() and int(string) > 0:
break
print("That was not a positive number!")
return int(string)Loop som läser in från en fil
def average_file(file_name):
""" Calculates and prints the avarage value of integers in a file """
input_sum = 0.0
count = 0
# 'r' säger att vi vill öppna filen för läsning.
# Vi kan inte skriva till filen om vi inte öppnar den med 'w'.
file_content = open(file_name, 'r')
for line in file_content:
input_sum += int(line)
count += 1
print("The average is", input_sum / count)>>> average_file("data.txt")
The average is 5.0Innehållet i data.txt:
4
5
6
Sidansvarig: Peter Dalenius
Senast uppdaterad: 2021-12-03
