
Dataabstraktion
Abstrakt eller konkret?
Vad är det egentligen som är abstrakt och vad är konkret? Man brukar säga att abstrakt är:
- Teoretiskt
- Konstruerad
- Overklig
- Svårfattlig
- Dunkel
- Akademisk
- Begreppsmässig
Och att konkret är:
- Verklig
- Påtaglig
- Faktisk
- Existerande
- Gripbar
Inom datavärlden finns det många typer av abstraktion. Dessa handlar inte alls bara om teori, och betyder inte att något skulle vara dunkelt eller svårfattligt. Istället handlar det om ett sätt att skapa överblick över komplexa system. Det är en process varigenom vi gömmer (och glömmer) detaljerna och istället skapar begrepp på högre nivå (abstraktioner). Begreppsmässig är alltså en ganska bra beskrivning av vad det handlar om.
Det finns flera sorters abstraktion. Procedurabstraktion ägnar vi oss åt när vi definierar funktioner. Vi kanske har konstruerat en formel eller en algoritm som utför en viss uppgift, som att sortera en lista. Denna skriver vi in i en funktion, ger ett namn och en parameterlista. När vi testat funktionen och är övertygade om att den fungerar korrekt är det inte längre så intressant att komma ihåg exakt hur den fungerar, utan vi kan använda den enbart genom att ange namnet. Vi har "abstraherat bort" detaljerna kring implementationen (quicksort?) och kan tänka på en högre nivå ("sortera listan").
På samma sätt är vi inte så intresserade av exakt hur den inbyggda funktionen sum faktiskt summerar, utan bara att den är korrekt. Detta betyder också att implementationen av sum kan ändras i ett senare skede utan att påverka övriga delar av systemet, så länge den uppfyller samma kontrakt -- så länge den gör samma sak.
En annan vanlig typ av abstraktion är dataabstraktion, vilket handlar om att skilja på:
-
Vilka synliga egenskaper en datatyp har: En mappning låter oss slå upp ett värde givet en nyckel; den kan bara lagra ett värde per nyckel; den låter oss ta bort nyckel/värde-par om vi vill; och så vidare.
-
Hur en datatyp konkret är implementerad: Python ger oss normalt tillgång till en konkret mappningstyp som kallas
dict, som är implementerad som en hashtabell (något vi inte har gått genom i detalj). Man skulle också kunna implementera en mappning som en lång lista med (nyckel,värde)-tupler, vilket är enklare men har nackdelen att varje uppslag kräver att man går genom listan till man hittar rätt nyckel. Poängen är att båda implementationerna av den abstrakta datatypen mappning kan uppfylla samma krav och ha i princip samma synliga egenskaper. Även här är man alltså mest intresserad av att en mappning "fungerar korrekt", att den uppfyller ett givet kontrakt.
Vi kan därmed också skilja på två sorters datatyper:
-
En abstrakt datatyp är en (eventuellt matematisk) modell som beskriver datatypens kontrakt, oberoende av något specifikt programmeringsspråk. Tidigare beskrev vi (väldigt ytligt och icke-matematiskt) några egenskaper som en mappning måste ha, såsom att man ska kunna slå upp ett värde givet en nyckel. Den abstrakta datatypen finns typiskt inte alls i implementationen (även om vissa språk har närliggande begrepp).
-
En konkret datatyp är en faktiskt implementerad datatyp med en specifik lagringsstruktur, till exempel implementationen av
dicti CPython 3.6 (CPython är namnet på referensimplementationen av Python).
En abstrakt datatyp kan vara primitiv. Man kan till exempel skapa en matematisk specifikation av hur Pythons heltal fungerar. Heltalen är odelbara (består inte av flera komponenter) men man kan likväl ha nytta av en formell beskrivning hur de ska fungera, för att kunna verifiera om en specifik implementation av heltal är korrekt.
Ändå pratar man oftare om abstrakta datatyper när de är sammansatta -- kanske för att de flesta datatyper vi använder faktiskt är sammansatta, och kanske för att de primitiva datatypernas regler oftare känns "självklara" (vi vet redan, eller tror redan att vi vet, exakt hur heltal fungerar).
Att implementera en abstrakt datatyp
En abstrakt datatyp är alltså en ren modell som inte alls är implementerad i kod. Den är väldigt användbar som specifikation, men för att vi ska kunna skriva fungerande program måste vi sedan implementera den funktionalitet som datatypen ska tillhandahålla.
Här skulle man kunna tänka sig att göra detta på ett extremt konkret sätt, genom att den som vill använda en datatyp går direkt på dess implementationsdetaljer. Till exempel kan vi anta att vi vill ha någon sorts implementation av den abstrakta datatypen mappning och att vi vill representera en mappning som en lista av (nyckel, värde)-tupler enligt ovan. Det kan vi göra på följande sätt, där mappningen är en lista och inget annat:
# Create a mapping
lastnames = []
# Add some entries
lastnames.append(("Jonas", "Kvarnström"))
lastnames.append(("Peter", "Dalenius"))
# Look up a value
for entry in lastnames:
if entry[0] == "Jonas":
print(entry[1])Här syns det överhuvudtaget inte i koden att vi har tänkt oss en specifik datatyp för mappningar. Vi går direkt på den lägsta nivån vi kan tänka oss: Listor, tupler, strängar och index. Detta kan vi göra betydligt bättre!
Vi sa redan att en mappning bland annat måste låta oss slå upp ett värde givet en nyckel. Den abstrakta datatypen måste alltså definiera ett antal operationer vi kan utföra, och i specifikationen av en abstrakt datatyp ger vi ofta dessa operationer namn, t.ex. get(mapping, key) -> value.
Det här kan vi ta fasta på även när det gäller en implementation, alltså en konkret datatyp som uppfyller specifikationen! Vi kan till exempel välja att implementera funktioner enligt den abstrakta datatypens specifikationer.
# Create a mapping
lastnames = createmap()
# Add some entries
setmap(lastnames, key="Jonas", value="Kvarnström")
setmap(lastnames, key="Peter", value="Dalenius")
# Look up a value
print(getmap(lastnames, "Jonas"))Nu har vi kommit en bra bit på vägen mot att abstrahera från vår interna representation. De operationer vi använder här är inte beroende av exakt hur en mappning är implementerad: Vi ser inga listor, tupelelement, index eller liknande ovan. Men om createmap() faktiskt returnerar en lista, och setmap faktiskt modifierar denna lista, kan man även göra så här:
# Let's modify the internal representation
lastnames[0] = 42
# What do we get now?
print(lastnames)
# prints [42, ("Peter", "Dalenius")]
# Look up a value
print(getmap(lastnames, "Jonas"))
# ...Crash, getmap can't handle non-tuples in the listAnvändare kan alltså förstöra innehållet eftersom de kan "peta" var som helst.
Och även om vi inte gör riktigt så allvarliga fel kan vi ju också skriva kod som följande:
for index, x in enumerate(lastnames):
if x[1] == "Kvarnström":
lastnames[index] = (x[0], "SomethingElse")Den här koden tittar på alla tupler x i mappningen och byter ut vissa efternamn mot andra. Men den gör det genom att veta exakt hur mappningen är implementerad! Koden är helt beroende av att vi kan iterera över nyckel-värde-par och att det går att ersätta dem genom att byta ut enskilda tupler, som på sista raden ovan.
Det fungerar utmärkt för vår nuvarande konkreta datatyp som använder sig av tupel-listor, men tänk nu om vi plötsligt inser att detta är väldigt ineffektivt när man har många nycklar, och vill byta ut implementationen mot en effektivare hashtabell istället. Kan vi göra det? Nej, inte utan att ändra på all kod som använder vår datatyp. Den koden kan vara utspridd bland miljoner eller miljarder rader kod i många olika projekt.
Att gömma implementation och representation
För att undvika problemen ovan vill vi oftast gå ett steg till:
-
Den exakta datalagringen ses som en implementationsdetalj. Ingen annan än datatypen själv har något med den att göra.
-
Koden som implementerar datatypen samlas i en egen fil eller modul, som tillhandahåller alla funktioner man kan tänkas behöva för att hantera ett värde av den givna typen. I princip tillhandahåller man alltså funktioner som motsvarar operationerna i en abstrakt datatyp, och som ska uppfylla vissa kontrakt. Hur de uppfyller kontrakten är implementationens ensak. För en mappning skapar man då inga funktioner som förutsätter att varje nyckel/värde-par har ett specifikt index.
-
Koden som använder datatypen (såsom vår kod ovan) får se till att bara använda sig av de tillgängliga operationerna på datatypen. Här ska man inte ha tillgång till några interna detaljer, såsom att varje nyckel/värde-par råkade ha ett index i vår ursprungliga implementation. Vi ska alltså inte använda
lastnamessom en vanlig lista, och indexera den. Vi ska inte ändra ilastnamespå andra sätt än medsetmap, och så vidare.
I vissa språk kan detta hanteras genom rättigheter som definieras i språket, så att enbart "datatypen själv" kan komma åt den interna datalagringen, och kod som försöker komma åt detta "utifrån" helt enkelt inte kan kompileras eller köras. Detta kommer vi bland annat att se i Java. I andra språk får man istället ha ett tankesätt att vissa data bara ska hanteras av de funktioner som tillhör datatypen, och disciplinen att inte gå utanför den regeln. Det är detta vi ska undersöka i labb 8.
Definition av datatyp (igen)
En datatyp är en väldefinierad sorts information som ett datorprogram kan använda. Datatypen talar om vilka dataobjekt som ingår i typen (vilken domän som typen har) samt vilka operationer som är tillåtna.
Datatypen svarar alltså på frågorna:
- Hur ser objekten ut?
- Vad kan man göra med dem?
Datatyper på olika nivåer
-
Min programvara -- bygger på...
-
Sammansatta datatyper -- ett spektrum som kan delas upp på många sätt
- Mer tillämpningsspecifika eller tillämpningsnära: personer, fordon, kurser, schema, ...
- ...
- Allmänna, användbara för många, men ändå inte centrala för språket -- stack, kö, tabell, bråktal, graf, ...
- ...
- Fundamentala i programspråket, men ändå sammansatta -- i Python: Listor, tupler, dict, ...
-
Programspråkets primitiva datatyper (har inga utåt synliga delar): Heltal, flyttal, ...
-
Hårdvarans primitiva datatyper (kan vara annorlunda; t.ex. kan ett språk ge tillgång till flyttal som primitiv datatyp även om hårdvarustöd saknas)
Datatypens definitionsmängd
Storlek:
- Ändlig: Till exempel sanningsvärden (True, False). I de flesta språk har även heltal och flyttal ett ändligt antal möjliga värden (inte oändlig precision).
- Oändlig: Till exempel Pythons heltal, som kan växa utan fördefinierad gräns (enbart minnet sätter gränsen).
Sammansättning:
- Primitiv: Till exempel heltal, som inte kan delas i flera naturliga komponenter.
- Sammansatt: Till exempel listor, dicts, och objekt. En lista kan bestå av flera element, och varje element är en separat "enhet". Ett komplext tal kan bestå av en reell del och en imaginär del.
- Rekursivt definerad: En sammansatt datatyp där en komponent kan ha samma typ som datatypen själv. Ett binärt sökträd kan till exempel vara ett tomt träd, ett löv eller en nod som innehåller upp till två andra binära sökträd.
Typer kan också vara hierarkiska. I Python kan tal (Number) vara heltal, flyttal eller komplexa tal. Ett heltal är en speciell sort av tal.
Primitiva operationer på datatyper
De primitiva operationerna utgör datatypens gränssnitt (eng. interface) gentemot resten av programkoden.
Några exempel på hur man kan klassificera olika primitiver:
- Konstruktorer (eng. constructors) för att skapa objekt.
- Selektorer (eng. selectors) för att plocka ut delarna.
- Igenkännare (eng. recognizers) för att känna igen objekt av viss datatyp eller objekt med särskilda egenskaper.
- Iteratorer (eng. iterators) för att bearbeta alla elementen i ett objekt, ofta med hjälp av högre ordningens funktioner.
- Jämförare (eng. comparator) för att kontrollera när objekt är lika.
- Modifikatorer (eng. modifiers) för att ändra elementen i ett objekt.
Utöver detta kan man definiera operationer för funktionalitet som man ofta behöver när man använder den givna datatypen. Ett komplext tal har till exempel en magnitud. Denna är inte en "del" av talet, men kan lätt räknas ut från talets reella och imaginära delar. Då kan man definiera en operation som returnerar talets magnitud.
Exempel: Symbolisk derivering
Deriveringsregler

Exempel
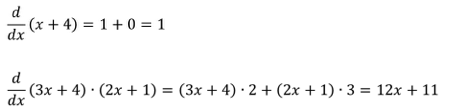
Lösningen nedan är representationsberoende. Programkod som relaterar till hur vi har valt att lagra de matematiska uttrycken är sammanblandad med programkod som behandlar algoritmen för symbolisk derivering. Vi vill istället införa dataabstraktion och alltså gömma informationen om hur data är representerat (eng. information hiding).
def differentiate(expr, var):
"""
Returns a string of the expression of the symbolic derivative of expr using var
"""
if expr == var:
return 1
elif isinstance(expr, str) or isinstance(expr, int):
return 0
elif expr[1] == '+':
return [differentiate(expr[0], var), '+', differentiate(expr[2], var)]
elif expr[1] == '*':
return [[expr[0], '*', differentiate(expr[2], var)],
'+',
[differentiate(expr[0], var), '*', expr[2]]]
else:
raise Exception("Invalid expression")Arbetsmetodik
Nedan ska vi visa hur man går genom följande steg:
- Identifiera datatyper. Studera tillämpningsområdet och karaktärisera den information som hanteras. För sammansatt information, bestäm hur de ingående delarna relaterar till varandra.
- Bestäm primitiva operationer. Se olika typer ovan.
- Bestäm intern representation. För varje datatyp, bestäm hur de enskilda objekten ska representeras (i termer av de datatyper som finns i det språk som används).
- Implementera de primitiva operationerna.
Identifiera datatyper
Vi vill implementera matematiska uttryck. Då ställer vi oss några frågor:
- Vilka sorters matematiska uttryck finns?
- Vilka är primitiva och vilka består av andra delar?
I vårt fall kommer vi fram till att ett uttryck kan vara en konstant, en variabel eller ett sammansatt uttryck. Ett sammansatt uttryck består i sin tur av två uttryck med en operator emellan.
Orden i kursiv stil ovan är de datatyper vi vill ha. Vi skulle kunna gå vidare och definiera dem som fullständiga abstrakta datatyper, men detta kräver att vi har en fullständig modell / specifikation över hur de ska fungera. I det här exemplet nöjer vi oss med en ytligare form av specifikation, som så klart fortfarande är på den abstrakta nivån: Vi har inte alls angivit hur konstanter, variabler eller andra datatyper ska lagras.
Bestäm primitiver
För våra syften antar vi att var och en av datatyperna behöver åtminstone en basuppsättning primitiver: konstruktor (som skapar objekt från dess delar), selektorer (som plockar ut de olika delarna) och igenkännare. Det är dock inte säkert att alla primitiver är nödvändiga för varje datatyp i just det exempel vi ska implementera.
Bestäm representation
Vi bestämmer oss för att representera datatyperna på följande sätt:
- Konstant: Ett vanligt tal så som det representeras i Python (int eller float).
- Variabel: En sträng i Python som innehåller bokstäver.
-
Operator: En sträng i Python som innehåller någon av symbolerna
+eller*. -
Sammansatt uttryck: En lista bestående av tre element:
[uttryck1, operator, uttryck2].
Definiera primitiver
# Konstant
def is_constant(obj):
return isinstance(obj, int) or isinstance(obj, float)
def make_constant(n):
return n
# Variabel
def is_variable(obj):
return isinstance(obj, str)
def same_variable(var1, var2):
return var1 == var2
# Summa
def is_sum(obj):
""" Check if argument is a binary addition expression """
return isinstance(obj, list) and len(obj) == 3 and obj[1] == '+'
def make_sum(left, right):
""" Make a binary addition expression """
return [left, '+', right]
# Produkt
def isproduct(obj):
""" Check if argument is a binary multiplication expression """
return isinstance(obj, list) and len(obj) == 3 and obj[1] == '*'
def make_product(left, right):
""" Make a binary multiplication expression """
return [left, '*', right]
# Uttryck
def arg1(expr):
""" Return the first subexpression """
return expr[0]
def arg2(expr):
""" Return the second subexpression """
return expr[2]Symbolisk derivering (abstraherad version)
Nedan ser vi ett exempel på hur vi använder de primitiva operationerna i deriveringskoden. Denna kod ligger alltså utanför den faktiska implementationen av uttrycken.
def differentiate(expr, var):
"""
Returns a string of the expression of the symbolic derivation of expr using var
"""
if is_constant(expr):
return make_constant(0)
elif is_variable(expr):
if same_variable(expr, var):
return make_constant(1)
else:
return make_constant(0)
elif is_sum(expr):
return make_sum(differentiate(arg1(expr), var),
differentiate(arg2(expr), var))
elif isproduct(expr):
return make_sum(make_product(arg1(expr),
differentiate(arg2(expr), var)),
make_product(differentiate(arg1(expr), var),
arg2(expr)))
else:
raise Exception("Invalid expression!")Vi ser nu att denna kod skulle fortsätta fungera precis lika bra om vi valde att representera sammansatta uttryck som [operator, uttryck1, uttryck2], så länge som vi också ändrade arg1() och arg2() på samma sätt. Vi skulle också kunna representera tal som ("number", n) istället för n.
Sätt att konstruera sammansatta datatyper
Många sammansatta datatyper liknar varandra strukturellt och därför kan det vara bra att försöka hitta överordnade begrepp för att beskriva dem. Följande diskretmatematiska begrepp brukar användas för att karaktärisera olika sorters sammansatta datatyper:
- Tupel
- Ändlig avbildning
- Sekvens
- Mängd
Tupel
| Begrepp | Tupel |
|---|---|
| Vad är det? | En datatyp med ett fixt antal element där varje element har en given datatyp, d.v.s ordningen mellen elementen spelar roll och elementen i sig har olika betydelser |
| Hur beskriver vi det? | <datatyp-1, ..., datatyp-n> |
| Exempel | datum = <år, månad, dag> |
| I Python | tuple |
Ändlig avbildning
| Begrepp | Ändlig avbildning (eng. finite mapping) |
|---|---|
| Vad är det? | En datatyp med fixt antal element av samma datatyp där ordningen mellan elementen egentligen inte spelar så stor roll (enbart om indexmänden är ordnad) |
| Hur beskriver vi det? | [nyckel-1 => data-1, ..., nyckel-n => data-n] |
| Exempel | veckoschema = ["Jonas" => "Kvarnström", "Peter" => "Dalenius"] |
| I Python | dict. Överkurs: Kan även använda list om nycklarna är heltal och är tillräckligt nära 0. Då får man dock inte samma gränssnitt / operationer! |
Sekvens
| Begrepp | Sekvens |
|---|---|
| Vad är det? | En datatyp med ett valfritt antal element av samma datatyp där ordningen mellan elementen spelar roll |
| Hur beskriver vi det? | {{datatyp}}* om det är okej med tomma sekvenser, {{datatyp}}+ om sekvensen måste innehålla något |
| Exempel | utbildningsprogram = {{kurs}}* |
| I Python | list |
Mängd
| Begrepp | Mängd |
|---|---|
| Vad är det? | En datatyp med ett valfritt antal element av samma datatyp där ordningen mellan elementen inte spelar roll |
| Hur beskriver vi det? | {datatyp} |
| Exempel | studieresultat = {kurs} |
| I Python | set |
Sidansvarig: Peter Dalenius
Senast uppdaterad: 2021-12-03
