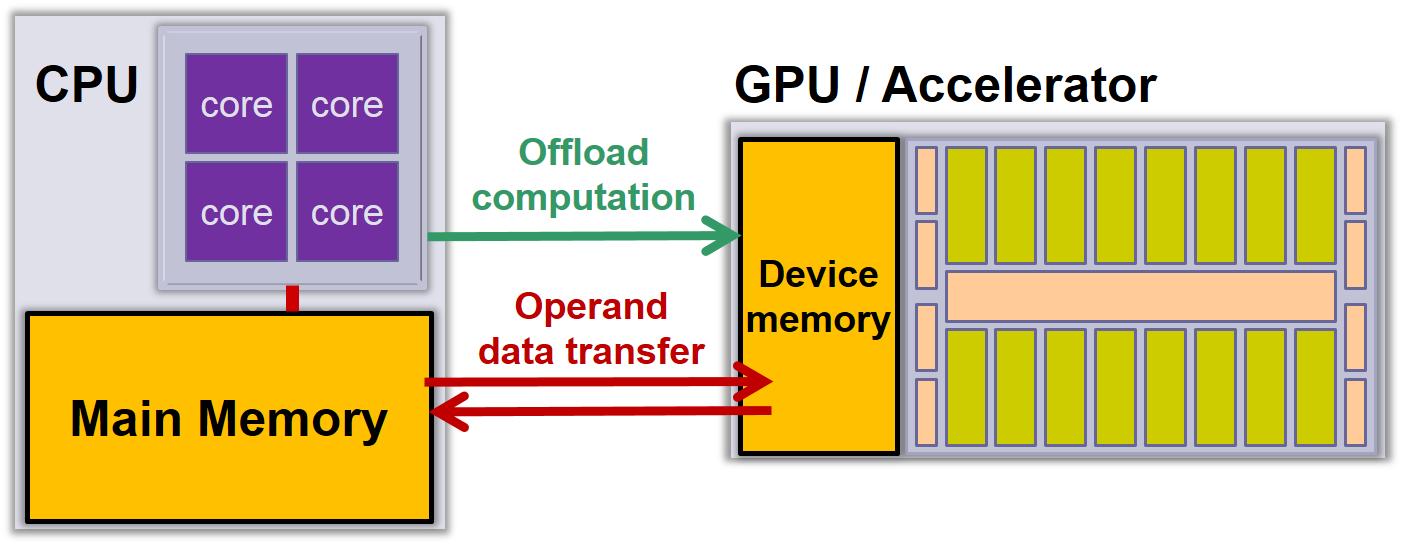
 VectorPU is a C++ annotation framework for operands of CPU and GPU functions
that allows to specify their access mode and helps to minimize the
amount of data transfers between main memory and device memory.
VectorPU also provides a generic data-container that supports coherent
software caching and automatic communication for accessed elements,
without hardware support.
VectorPU achieves similar programming comfort as CUDA Unified Memory
but has lower overhead.
VectorPU is a C++ annotation framework for operands of CPU and GPU functions
that allows to specify their access mode and helps to minimize the
amount of data transfers between main memory and device memory.
VectorPU also provides a generic data-container that supports coherent
software caching and automatic communication for accessed elements,
without hardware support.
VectorPU achieves similar programming comfort as CUDA Unified Memory
but has lower overhead.
-
Lu Li, Christoph Kessler:
VectorPU: A Generic and Efficient Data-container and Component Model for Transparent Data Transfer on GPU-based Heterogeneous Systems.
Proc. 8th Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures and 6th Workshop on Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'17), Stockholm, Jan. 2017, ACM. DOI: 10.1145/3029580.3029582. - VectorPU poster, MCC'17, Uppsala, Nov. 2017
|
|

|
Overview
VectorPU is a STL-like data container on GPU-based heterogeneous systems, which could be seaminglessly integrated to STL or Thrust algorithm library. It enables automatic data coherence management for abitrary kernels, either on CPU or GPU, without redundant data transfers. We provide a easy-to-use annotation language for programmers to use. VectorPU's performance is much faster than Nivida's Unified Memory, and no noticeable slowdown compared to experts' handwritten code.
Main features:
- Automatic data allocation/deallocation for host and device memory
- Automatic data transfer between host and device memory
- Reusable and switchable flow signature to express access modes (read, write etc.)
- Smart (coherenced) pointer and iterator
- Partial coherence supported
- Self-adative (portable) data structures by interfacing with XPDL
- Multi-GPU support
Source Code and Documentation
If you use VectorPU for your work, please cite it in any resulting publications as:
-
Lu Li, Christoph Kessler:
VectorPU: A Generic and Efficient Data-container and Component Model
for Transparent Data Transfer on GPU-based Heterogeneous Systems.
In: Proc. 8th Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures and 6th Workshop on Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'17),
Stockholm, Jan. 2017, ACM. DOI: 10.1145/3029580.3029582
Current version:
Remarks: Tested on several systems with Nvidia CUDA Kepler and Maxwell GPUs
Publications
-
Lu Li, Christoph Kessler:
VectorPU: A Generic and Efficient Data-container and Component Model for Transparent Data Transfer on GPU-based Heterogeneous Systems.
Proc. 8th Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures and 6th Workshop on Design Tools and Architectures for Multicore Embedded Computing Platforms (PARMA-DITAM'17), Stockholm, Jan. 2017, ACM. DOI: 10.1145/3029580.3029582. -
Lu Li, Christoph Kessler:
Lazy Allocation and Transfer Fusion Optimization for GPU-based Heterogeneous Systems.
To appear in Proc. Euromicro PDP-2018 Int. Conf. on Parallel, Distributed, and Network-Based Processing, Cambridge, UK, Mar. 2018, IEEE.
Code Examples
- Sorting an array on a GPU
- Heterogeneous or hybrid computing
#include <vectorpu.h>
int main()
{
vectorpu::vector<My_Type> x(N);
std::generate(WI(x), WEI(x), RandomNumber);
thrust::sort(GRWI(x), GRWEI(x));
std::copy(RI(x), RI(x), ostream_iterator<My_Type>(cout, ""));
return 0;
}
#include <vectorpu.h>
int main()
{
vectorpu::vector<My_Type> v1(N), v2(N);
std::generate(WI(v1), WEI(v1), RandomNumber);
std::generate(WI(v2), WEI(v2), RandomNumber);
userspace::sort<<<32,256>>>(GRWI(v2),GRWEI(v2));
std::sort(GRWI(v1), GRWEI(v1));
cudaDeviceSynchronize();
return 0;
}

