



As we have said, protocol implementors typically have to be concerned about a lot of operating system issues. This subsection introduces one of the most important of these issues---the process model.
Most operating systems provide an abstraction called a process, or alternatively, a thread. Each process runs largely independently of other processes, and the OS is responsible for making sure that resources, such as address space and CPU cycles, are allocated to all the current processes. The process abstraction makes it fairly straightforward to have a lot of things executing concurrently on one machine; for example, each user application might execute in its own process, and various things inside the OS might execute as other processes. When the OS stops one process from executing on the CPU and starts up another one, we call this a context switch.
When designing a protocol implementation framework, one of the first questions to answer is: ``Where are the processes?'' There are essentially two choices, as illustrated in Figure 5. In the first, which we call the process-per-protocol model, each protocol is implemented by a separate process. This implies that as a message moves up or down the protocol stack, it is passed from one process/protocol to another---the process that implements protocol i processes the message, then passes it to protocol i-1, and so on. How one process/protocol passes a message to the next process/protocol depends on the support the host OS provides for interprocess communication. Typically, there is a simple mechanism for enqueuing a message with a process. The important point, however, is that a context switch is required at each level of the protocol graph---typically a time-consuming operation.
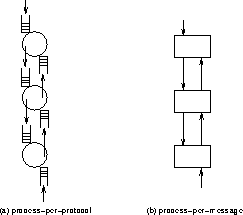
Figure 5: Alternative Process Models.
The alternative, which we call the process-per-message model, treats each protocol as a static piece of code, and associates the processes with the messages. That is, when a message arrives from the network, the OS dispatches a process to be responsible for the message as it moves up the protocol graph. At each level, the procedure that implements that protocol is invoked, which eventually results in the procedure for the next protocol being invoked, and so on. For out-bound messages, the application's process invokes the necessary procedure calls until the message is delivered. In both directions, the protocol graph is traversed in a sequence of procedure calls.
Although the process-per-protocol model is sometimes easier to think about---I implement my protocol in my process and you implement your protocol in your process---the process-per-message model is generally more efficient. This is for a simple reason: a procedure call is an order of magnitude more efficient than a context switch on most computers. The former model requires the expense of a context switch at each level, while the latter model costs only a procedure call per level.
The x-kernel uses the process-per-message model. Tying this model back to the operations outlined above, this means that once a session (channel) is open at each level, a message can be sent down the protocol stack by a sequence of calls to xPush, and up the protocol stack by alternating calls to xDemux and xPop. This asymmetry--- xPush going down and xDemux/ xPop going up---is unappealing, but necessary. This is because when sending a message out, each layer knows which low-level session to invoke xPush on because there is only one choice, while in the incoming case, the xDemux routine at each level has to first demultiplex the message to decide which session's xPop to call.
Notice that the high-level protocol does not reach down and receive a message from the low-level protocol. Instead, the low-level protocol does an upcall---a procedure call up the stack---to deliver the message to the high-level protocol. This is because a receive-style operation would imply that the high-level protocol is executing in a process that is waiting for new messages to arrive, which would then result in a costly context switch between the low-level and high-level protocols. By having the low-level protocol deliver the message to the high-level protocol, incoming messages can be processed by a sequence of procedure calls, just as outgoing messages are.
We conclude this discussion of processes by introducing three operations that the x-kernel provides for process synchronization:
void semInit(Semaphore *s, int count)
void semSignal(Semaphore *s)
void semWait(Semaphore *s)
These operations implement conventional counting semaphores. Specifically, every invocation of semSignal increments semaphore s by one, and every invocation of semWait decrements s by one, with the calling process blocked (suspended) if decrementing s cause its value to become less than zero. A process that is blocked during its call to semWait will be allowed to resume as soon as enough semSignal operations have been performed to raise the value of s above zero. Operation semInit initializes the value of s to count.