The PEPPHER composition tool was developed at Linköping University, Sweden,
in the EU FP7 project
PEPPHER (2010-2012) which
addressed programmability and portability for modern heterogeneous
multi- and manycore systems.
The composition tool provides high level abstraction to
the PEPPHER runtime system,
including support for static composition.
This manual describes the current prototype of the PEPPHER composition tool,
its main features and how to use it,
including do's and don't's as well as limitations of the current prototype.
Further information and experimental results can be found in the
publications.
The composition tool uses the meta-data and associated source code files
to generate the composition glue code and build the complete application
from the annotated components.
The meta-data is specified using separate XML files.
NB! The composition tool does not process annotations
within the source files.
Normally (excluding utility mode) the composition tool is invoked using a command such as compose <main.xml> where <main.xml> is the name of the XML descriptor file corresponding to the main function. This <main.xml> XML file can link to other components/interfaces which are invoked by the main function. By following these component dependence references, the composition tool can recursively explore all the interfaces used in the application to be built.
Currently, the depth of this recursive exploration is limited to 1 (i.e. only the main function contains different component calls), because of the following technical reason:
Currently, the prototype mainly targets generating code that is executable on the PEPPHER runtime system which does not support recursion (i.e. a task cannot be created/executed inside the body of another task). Hence, nesting a component call inside another component body where each component is a runtime task is not possible without code modifications. However, one may call a concrete implementation inside a component implementation (i.e., hardcoded composition, e.g., directly calling a CUDA implementation of the "partition" component within a CUDA quicksort implementation of a sorting component).
The current composition tool prototype is ported to GNU AutoTools. This means that it can be configured/built as follows:
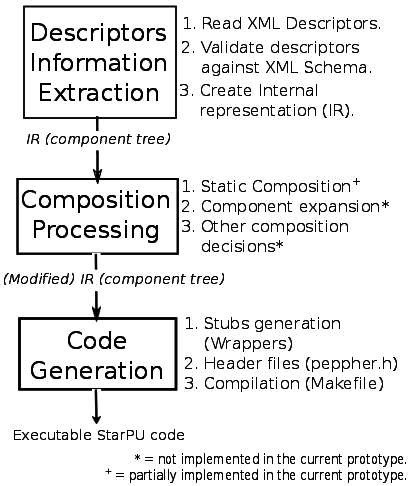
The PEPPHER composition tool is written in C++. It uses the Xerces C++ XML parser to parse and validate XML descriptors of PEPPHER component interfaces and implementations with respect to PEPPHER XML schema. Internally it stores the component metainformation in an abstract syntax tree (AST). Any static composition and other processing is carried out on this AST and later the (modified) AST is used to generate the code for the dynamic composition (selection code and creation of one or several tasks for dynamic scheduling and selection by the runtime system, i.e., StarPU). The figure to the right explains the internal architecture of the composition tool.
When PDL support is enabled, the composition tool uses CodeSynthesis XSD for the data binding from the PDL schema to C++ classes/functions.
For details about PEPPHER containers and their usage with PEPPHER components, see the publications for more information.
Smart containers are STL-like generic containers that implement a
distributed shared memory on a heterogeneous system and thus
keep track of where its element data is currently residing on
the different memory units, which allows to eliminate some unnecessary
data transfers between memory units at runtime.
In contrast to the SkePU
smart containers, in PEPPHER-generated code the actual coherence mechanism
and memory management is delegated to the corresponding
container data structures in the
PEPPHER runtime system.
In this case, the containers act as smart wrappers, abstracting interaction
with the memory management API of the runtime system.
They transparently manage the interaction with the PEPPHER runtime system
and support asynchronous execution and task partitioning when used to pass
operand data to the PEPPHER components.
peppher::Vector<float> v0(25, 3.5f); // create a float vector "v0" with 25 elements, each initialized to value 3.5 peppher::Vector<int> v1(10); // create an integer vector "v1" with 10 elements v1.randomize(10,50); // initialize v1 elements with random values between 10 and 50. v1[5]= 55; // set 6th element of v1 to value 55 std::cout << "v1: " << v1; // print contents of vector v1The Vector implementation is based on C++ so it can be used only in CPU-side code. For CUDA and OpenCL code, one can pass the underlying raw pointer using getRawType() method. .
peppher::Matrix<float> m0(5, 10, 3.5f); // create a float matrix "m0" of size 5 X 10, each element initialized to value 3.5 peppher::Matrix<int> m1(10, 10); // create an integer matrix "m1" of size 10 X 10 m1.randomize(10,50); // initialize m1 elements with random values between 10 and 50. m1(5,2)= 55; // set 3rd element in 6th row of m1 to value 55 std::cout << "m1: " << m1; // print contents of matrix m1The Matrix implementation is based on C++ so it can be used only in CPU-side code. For CUDA and OpenCL code, one can pass the underlying raw pointer by using the getRawType() method.
int idNo=30; peppher::Scalar<int> pIdNo(&idNo, true); // don't deallocate memory when destructor called as the memory pointed-to is on stack. peppher::Scalar<int> pTemp(new int(10)); // will deallocate memory when destructor called as the memory pointed-to is on heap. std::cout << "value: " << *pTemp; // value: 10The Scalar implementation is based on C++ so it can be used only in CPU-side code. For CUDA and OpenCL code, one can pass the underlying raw pointer using the getRawType() method.
To allow asynchronous execution for a component call, all operand(s) of that component must be either in:
Reason: The composition tool does not imply any kind of static source-code analysis to find data-dependencies and data-usage across different instructions. Rather, it relies on information specified in the XML files to generate the code. This makes it difficult for the composition tool to optimally decide for arbitrary data when to register or unregister it. Hence, for parameters not modeled using PEPPHER containers and not being native scalar typed (e.g. int, float) read-only values, it conservatively registers and un-register them for each component invocation, which makes the component invocation sychronous (blocking) and may yield significant overhead for non-trivial applications.
A PEPPHER component has one interface containing one method and multiple implementations of that interface, possibly for different backends (CPU, CUDA, OpenCL). For each component interface, there is one XML file that specifies meta-information for that interface, including name, signature, directory containing implementation files etc. (see the XML files in the example folder in the prototype directory).
For a component that uses PEPPHER containers to receive operand data, the XML file needs to specify this information.
For example, consider an interface with the method signature:
void vector_scale( float *arr, unsigned size, float factor);The XML file to specify that interface is:
<peppher:component ...>
<peppher:interface name="vector_scale">
<peppher:parameters>
<peppher:parameter name="arr" type="float *" accessMode="readwrite" numElements="size" />
<peppher:parameter name="size" type="unsigned" accessMode="read" />
<peppher:parameter name="factor" type="float" accessMode="read" />
</peppher:parameters>
</peppher:interface>
</peppher:component>
The above component definition can be executed only synchronously. To allow asynchronous execution,
we need to wrap "float *" as a PEPPHER Vector container:
void vector_scale(peppher::Vector<float> &v, float factor);And the XML file describing above interface is as follows:
<peppher:component ...>
<peppher:interface name="vector_scale">
<peppher:parameters>
<peppher:parameter name="arr" type="peppher::Vector" elemType="float" accessMode="readwrite" />
<peppher:parameter name="factor" type="float" accessMode="read" />
</peppher:parameters>
</peppher:interface>
</peppher:component>
As can be seen above, by wrapping "float *" in a Vector, we dont need any more pass the size of the vector as it can be obtained from the Vector object using the "v.size()" method.
The only addition for PEPPHER containers in interface XML descriptor file is the elemType attribute which specifies the element type, as containers are generic for the element type. The elemType can be any non-pointer type that can be instantiated with zero-argument constructor. Furthermore, the parameters using PEPPHER containers (Vector, Matrix, Scalar) are always passed by reference; however in an interface file, the type attribute does not specify that. In a way, the actual type of a parameter passed using PEPPHER containers is something like type<elemType> & where type and elemType are attributes specified in the interface XML descriptor file.
<peppher:component ...>
<peppher:interface name="vector_scale">
<peppher:parameters>
<peppher:parameter name="arr" type="peppher::Vector" elemType="float" accessMode="readwrite" partition="arr.size()/10" />
<peppher:parameter name="factor" type="float" accessMode="read" />
</peppher:parameters>
</peppher:interface>
</peppher:component>
In essence, partition specifies the size of each chunk. As can be seen in the above example, we can use an expression instead of a contant value, which allows us to specify a partition size in terms of the actual vector size. The partition="arr.size()/10" means that vector will be divided in 10 partitions of equal size. Each partition will correspond to one task in the runtime system, producing 10 tasks in this example that can be processed concurrently.
See the examples folder to know more about the partitioning for 2D matrix objects.
For the CPU backend, the composition tool supports both sequential CPU components and parallel components written using OpenMP.
<peppher:implementation name="..." validIf='pdl::getIntProperty("numCudaSM") .GE. 16'>
Details can be found in our MULTIPROG-2014 paper on Conditional Composition.
template <typename T> void matrixmul(peppher::Matrix<T> &A, peppher::Matrix<T> &B, peppher::Matrix<T> &C);The XML descriptor file to specify that interface is:
<peppher:component ...>
<peppher:interface name="matrixmul" impPath="./matrixmul_/" templateTypes="T">
<peppher:parameters>
<peppher:parameter name="A" type="peppher::Matrix" elemType="T" accessMode="read" />
<peppher:parameter name="B" type="peppher::Matrix" elemType="T" accessMode="read" />
<peppher:parameter name="C" type="peppher::Matrix" elemType="T" accessMode="readwrite" />
</peppher:parameters>
</peppher:interface>
</peppher:component>
The templateTypes attribute is used to specify template/generic types used in an interface declaration. In the above example, there is only one generic type, named "T" so templateTypes attribute contains "T". In case of more than one template types, they are specified in a comma-separated manner, e.g. templateTypes="T,U" in case there are two generic template types "T" and "U".
Limitation: While using generic components, there are certain limitations with usage of both CUDA and OpenCL at the same time. For example, having a generic CUDA implementation, the main source file (i.e. source file containing the main function e.g. main.cpp) must be renamed to extension ".cu" (e.g. main.cu). This is because the template code needs to be included rather than compiled separately, which ultimately means that the CUDA implementation will be included in the main source file. That being said, any source file containing CUDA code needs to be compiled with the NVIDIA compiler (nvcc), which requires a ".cu" file extension. As this file is compiled by the NVIDIA compiler (nvcc) it cannot contain any OpenCL code as OpenCL is compiled with a regular C compiler such as gcc.
In the current prototype, the default implementation variant selection is done using the dynamic scheduling and selection capabilities of the PEPPHER runtime system (StarPU). Internally, the StarPU runtime system can use performance-aware scheduling policies to do the scheduling. However, usage of such performance-aware scheduling and selection policies requires certain modifications in the code, e.g., definition of struct starpu_perf_model_t.
To enable support for using this scheduling policy, the user may specify a flag (useHistoryModels). The flag can be specified for an individual component in the interface XML descriptor file, which will enable performance-aware scheduling for only that component, e.g.
<peppher:interface name="vector_scale" useHistoryModels="true">or it could be specified as a command-line argument to the composition tool which will apply it for all components in that application, e.g.
compose main.xml -useHistoryModels
<peppher:implementation name="scale_cpu_func" disable="true">To enable/disable a certain type of implementations (CPU, CUDA, OpenCL), you can either specify it for a single component by specifying it in the interface XML descriptor file, e.g.
<peppher:interface name="vector_scale" disableCPU="true" ...>or it could be specified as a command-line argument to the composition tool which will apply it for all components in that application, e.g.
compose main.xml -disableCPUIf you want even more control on static implementation selection, you can use -disableImpls, -disableXmlFiles command-line arguments of the composition tool.
Lu Li, Usman Dastgeer, Christoph Kessler:
Adaptive off-line tuning for optimized composition of components for heterogeneous many-core systems.
Seventh International Workshop on Automatic Performance Tuning (iWAPT-2012), 17 July 2012, Kobe, Japan.
In: Proc. VECPAR-2012 Conference, Kobe, Japan, July 2012. Springer LNCS 7851, pp. 329-345, 2013.
Author version (PDF)
Lu Li, Usman Dastgeer, Christoph Kessler:
Pruning strategies in adaptive off-line tuning for optimized composition of components on heterogeneous systems.
Accepted for Proc. Seventh International Workshop on Parallel Programming Models and Systems Software for High-End Computing (P2S2) at ICPP, 2014.
#ifndef VECTOR_SCALE_H #define VECTOR_SCALE_H void vector_scale (float *arr, int size, float factor); ... #endifBy running the composition tool with the -generateCompFiles option:
compose --generateCompFiles="vector_scale.h"the composition tool will generate an XML and a C-source file for each backend (CPU, CUDA, OpenCL), six files in total, containing simple skeletons which can be further filled-in with more information. This utility mode can help component writers in writing PEPPHER components from legacy code in a time-efficient manner. Please note that when specified --generateCompFiles option, we don't need to specify any other command-line arguments to the composition tool. This is beacuse that composition tool does not do the code generation for StarPU backend in this mode.
The utility is still far from perfect but can already work with simple C/C++ method declarations ending with semicolon (;). As a PEPPHER component can have one method, so this utility just look for first method declaration and neglect remaining text in the file.
For matrix multiplication:
For vector scale:
| -v=xxx | Verbose mode [1 | 2 | 3 | 0*]. In default (0), no information is displayed while more information is displayed in increasing verbose number order. |
| -wrapperFilesExt="xxx" | Specify generated wrapper files extension (Default: ".h"). |
| -useHistoryModels | To enable usage of StarPU history performance models for all components. See! |
| -usePdl="xxx" | A PDL XML file to be used during composition decisions. |
| -enableLibraryMode | Enable library mode (no link statement generated). |
| -disableXMLFiles="xxx" | List of implementation XML file-names(comma-separated if multiple) that should not be processed. The file-names should have .xml extension. |
| -disableImpls="xxx" | Name of implementations(comma-separated if multiple) that should not be used for generating code. It is different from -disableXMLFiles option as in this case, composition tool still processes XML files but don't select these implementations when generating the code. |
| -disableCPU | To disable CPU implementations for all components. |
| -disableCUDA | To disable CUDA implementations for all components. |
| -disableOpenCL | To disable OpenCL implementations for all components. |
| -enableMultiImpl | To enable usage of multiple implementations for each backend. |
| -disableXMLValidation | To disable XML validation done by the Xerces XML parser. |
| * = Default if not provided explicitly. | |
| ** = Options names are case-insensitive. However, the actual values e.g. for -disableXMLFiles="abc.xml", The xml file name "abc.xml" is case-sensitive in this case. | |
The process of porting legacy code using the Composition tool is described in the following figure ((c) C. Kessler 2011):

