
Temauppgift 3
Gör Pythonuppgifter 3 innan du börjar med Temauppgift 3.
Temauppgift 3 består av två delar:
- Del 1: Pythonskript och och rita diagram med matplotlib. Redovisas samt kodinlämning.
- Del 2: Bearbeta och visualisera data från en studie om mentala rotationer av. Ganis och Kievit (2015). Redovisas samt kodinlämning.
Redovisning, inlämning och kompletteringar (Tema 1-3)
- På sidan Redovisning hittar du information om den muntliga redovisningen, samt hur du kompletterar om du missar ett redovisningstillfälle.
- På sidan Inlämningar via Lisam hittar du information inlämning av kod m.m.
- Ni får antingen Godkänt eller Komplettering ges på inlämningar som hör ihop med temauppgift 1-3. Vid Komplettering får ni instruktioner för vad som ska kompletteras. På Temauppgift 3, kan ni även få Väl godkänt.
Att redovisa
Vid redovisningstillfället visar ni
- att ni gjort Del 1: dvs visa att ni kan köra er kod och att diagram skapas
- att ni gjort Del 2: dvs visa att ni kan köra er kod och att diagramen skapas
Redovisa sedan nedanstående punkter för Del 2. Tänk igenom och förbered innan redovisningstillfället upplägget för er redovisning.
- berätta översiktligt om hur flödet för Uppgift 2 ser ut; hur hänger funktionerna ihop?
- berätta översiktligt om hur flödet för Uppgift 3 ser ut; hur hänger funktionerna ihop?
- beskriv någon del av koden som bearbetar en nästlad struktur; se till du tydligt berättar vilken datatyp de olika variablerna har, samt vilken struktur de har
Översiktligt betyder att ni inte ska gå igenom koden rad för rad. Redovisningen ska inte heller vara en “innantilläsning” av koden, utan ni ska redogöra för flödet i programmet och t.ex. vilka delproblem som ni löser på vilka delar av koden.
Tänk på och se till att ni förberett så att ni hinner med redovisningen på 10 minuter!
Att skicka in
Efter redovisning skickas all kod ni skrivit in via Lisam. Ni inlämningen är en “spontan gruppinlämning” så se till att alla gruppmedlemmar läggs till inlämningen. Se även till att döpa er grupp till ert pargruppsnamn.
Uppgiftsnivåer och betyg
- För att få G på momentet LAB1 behöver alla uppgifter förrutom Uppgift 3b i Del 2 lösas; dvs gör 3a, men inte 3b.
- För att få VG på momentet LAB1 behöver alla uppgifter förrutom Uppgift 3a i Del 2 lösas; dvs gör 3b, men inte 3a.
Uppgradera temauppgiftsbedömning
- Temauppgift 3: Om ni redan fått Godkänt, men vill ha Väl godkänt, boka tid med en handledare för ett försök att redovisa det som behövs för Väl godkänt.
- Temauppgift 4-5: Om ni redan har fått 1 poäng, men vill ha 3 poäng boka tid med en handledare för ett försök att redovisa det som behövs för 3 poäng.
- Temauppgift 6: Om ni redan har fått 1 poäng, men vill sikta på 3 poäng på temauppgift 6. Skicka ett e-postmeddelande till Johan.
OBS! Deadlines finns för ovanstående.
Del 1: Diagram med matplotlib
Läsa in data och rita ut eget diagram.
Förberedelser och förkunskaper
Material att studera:
- Lektion inför Temauppgift 3 om matplotlib.
- Tipssida för Matplotlib
- Hur man skriver pythonskript som tar emot argument.
Förberedelser att göra (om du kör i LiUs Linux-miljö):
- Aktivera den virtuella miljön i katalogen
/courses/729G46/729G46-venv(se lektionsmaterialet). - Kopiera filerna från
/courses/729G46/kursmaterial/temauppg3/del1till en katalog som du använder för del 1.
Allmänna tips
Försök att dela upp uppgiften i delproblem och lös varje delproblem i en egen funktion. Exempel på delproblem:
- ladda in en fil
- räkna ut antalet koppar i snitt för ett klockslag
- plocka ut alla datapunkter för en dag
CSV-filer
I /courses/729G46/kursmaterial/temauppg3/del1 finns ett antal .csv-filer
med påhittad data om kaffevanor hos ett antal kända forskare. Nedan ser ni
innehållet i filen AdaLovelace.csv:
;Måndag;Tisdag;Onsdag;Torsdag;Fredag;Lördag;Söndag
8;1;1;0;1;1;0;0
9;0;0;1;0;0;1;0
10;0;0;1;0;0;1;0
11;0;0;0;0;0;0;0
12;0;0;0;0;0;0;0
13;0;0;0;0;0;0;0
14;0;0;0;0;0;0;0
15;0;0;0;0;0;0;0
16;0;0;0;1;0;2;3
17;1;1;2;0;1;1;0
18;1;0;0;2;1;1;2
Den första raden består av kolumnrubriker för efterföljande rader. Resterande rader innehåller först ett klockslag och sedan hur många koppar kaffe som (i det här fallet) Ada Lovelace dricker under den timmen en viss dag. T.ex. så ser vi att hon drack tre koppar kaffe mellan kl. 16:00 och 17:00 på söndagar.
OBS! ; används som skiljetecken mellan de olika värdena i dessa filer.
Till Temauppgift 3 ska ni inte använda modulen csv för att läsa in data. Vi kommer även läsa in CSV-filer i Temauppgift 4 och där får ni använda csv-modulen om ni vill.
Uppgift: Läs in data och rita ut linjer
Skriv ett skript som gör följande:
- tar emot sökvägen till en
.csv-fil som argument - läser in data från
.csv-filen - ritar ut ett diagram med data från
.csv-filen som sparas som enpng-fil
Exempelkörning
Nedan körs skriptet ni ska skapa i uppgift 1 från terminalen. När det kört klart
ska minst diagram för den anvisade CSV-filen ha skapats. Namnet på diagramfilen
kan med fördel bygga på filnamnet som data lästes in ifrån, t.ex.
AdaLovelace1.png för exemplet nedan.
$ ./skapa-kaffediagram1.py csv/AdaLovelace.csv
I ovanstående anrop antas alla .csv-filer ligga i en katalog som heter csv.
Inläsning av data
Ett sätt att representera datat i python är att låta varje rad i textfilen
motsvara en lista. Den första raden i textfilen
(";Måndag;Tisdag;Onsdag;Torsdag;Fredag;Lördag;Söndag") bör då således bli
följande lista: ["", "Måndag", "Tisdag", "Onsdag", "Torsdag" "Fredag", "Lördag", "Söndag"]. Textfilen som helhet blir då en lista av listor.
Tänk också på att vid inläsning av data från en textfil så läses raderna in som
just text, dvs som strängar. Om man vill räkna på datat bör värden som
egentligen är heltal, även konverteras till heltal. Nedan ser ni hur datat från
AdaLovelace.csv ser ut som en lista av listor med korrekt datatyp för alla
värden (radbryt tillagda för tydlighets skull).
[['', 'Måndag', 'Tisdag', 'Onsdag', 'Torsdag', 'Fredag', 'Lördag', 'Söndag'],
[8, 1, 1, 0, 1, 1, 0, 0],
[9, 0, 0, 1, 0, 0, 1, 0],
[10, 0, 0, 1, 0, 0, 1, 0],
[11, 0, 0, 0, 0, 0, 0, 0],
[12, 0, 0, 0, 0, 0, 0, 0],
[13, 0, 0, 0, 0, 0, 0, 0],
[14, 0, 0, 0, 0, 0, 0, 0],
[15, 0, 0, 0, 0, 0, 0, 0],
[16, 0, 0, 0, 1, 0, 2, 3],
[17, 1, 1, 2, 0, 1, 1, 0],
[18, 1, 0, 0, 2, 1, 1, 2]]
Tips för inläsning
Skriv en funktion (t.ex. load_csv(filename)) som tar in ett filnamn och
returnerar en lista med inläst data enligt ovan.
Diagram
Datat i den inlästa filen behöver bearbetas lite innan det kan visas med ett linjediagram. Nedan är två olika diagram som skulle kunna skapas.
Det räcker med att skapa en av nedanstående diagramtyp. Välj vilken ni vill skapa!
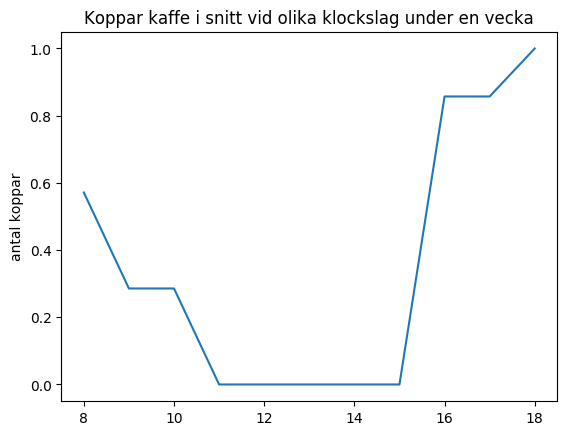
I det första diagrammet har de olika klockslagen samlats ihop i listan
x_values och snittet för de olika klockslagen under veckan har samlats ihop i
listan y_values. Diagrammet har sedan skapats med plt.plot(x_values, y_values).
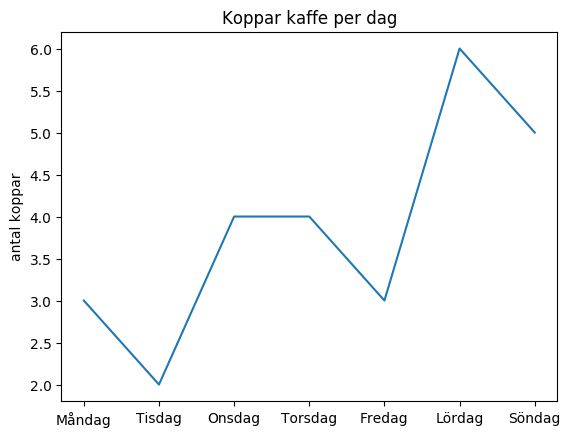
I det andra diagrammet har istället dagarna samlats ihop i listan x_values och
det totala antalet koppar under varje dag har samlats ihop i listan y_values.
Diagrammet har sedan skapats med plt.plot(x_values, y_values).
Det räcker med att skapa en diagramtyp. Välj vilken ni vill skapa!
Variation
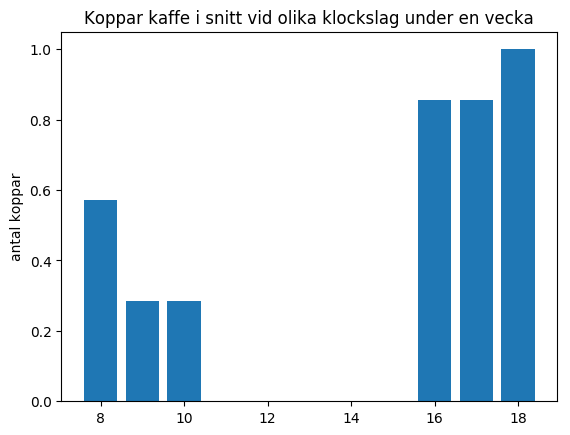
Om man hellre velat skapa ett stapeldiagram är det bara att använda
plt.bar(x_values, y_values) istället:
Del 2: Diagram från studie om mentala rotationer
Den uppgift som ska lösas i Del 2 är att visualisera data från en studie om mental rotation. Syftet med visualiseringen är att få en överblick över insamlad data. Att göra detta med hjälp av Python är mycket praktiskt eftersom processen är automatiserad vilket gör det mycket lättare att skapa den mängd diagram som behövs (jämför detta med att skapa varje diagram manuellt i t.ex. Excel).
Förberedelser och förkunskaper
- Gå igenom lektionsmaterialet.
- Hur man läser JSON-data med Python.
- Hur man skriver pythonskript som tar emot argument.
- Aktiverat den virtuella miljön i katalogen
/courses/729G46/729G46-venv(se lektionsmaterialet). - Kopiera filerna från
/courses/729G46/kursmaterial/temauppg3/del2till en katalog som du använder för del 2.
Data
Data som används i Temauppgift 3 är framtagen och släppt som öppen data av Ganis och Kievit (2015).
Ganis, G. and Kievit, R.A., 2015. A New Set of Three-Dimensional Shapes for Investigating Mental Rotation Processes: Validation Data and Stimulus Set. Journal of Open Psychology Data, 3(1), p.e3. DOI: http://doi.org/10.5334/jopd.ai
Kort om studien och experimentet
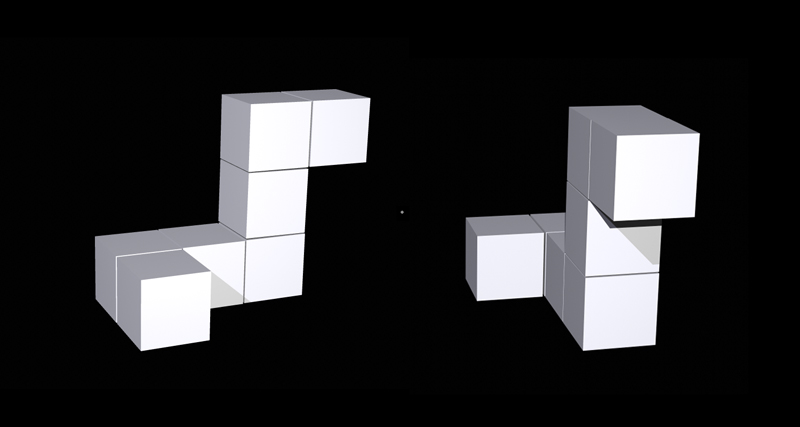
I studien visade Ganis och Kievit biler till ett antal försökspersoner (FP). Två figurer fanns med på bilderna, en till höger och en till vänster. FPs uppgift var att avgöra om den högra figuren hade samma form som den vänstra. Dock kunde den högra figuren vara roterad 0, 50, 100, eller 150 grader. Om FP tyckte att det var samma form skulle hen trycka på en knapp, om inte skulle FP trycka på en annan knapp.
Exempel på bild som visades (högra figuren roterad 100 grader):
Filer
I mappen /courses/729G46/kursmaterial/temauppg3/del2/json finns råfiler till
det dataset från en studie om mentala rotationer. Data för varje enskild
försöksperson finns sparad i en enskild fil, t.ex. sub1.json för försöksperson 1.
Innehåll i filerna
I det här fallet lagrar JSON-filerna datat som kolumner. Efter inläsning av
JSON-filen sub1.json till ett dictionery (se sidan om JSON)
får vi nedanstående. Innehållet har formatterats om för läsbarhet och endast de
5 första försöken visas här.
{
"trial": [ 1, 2, 3, 4, 5 ],
"image": [ "R2_3_3_2_0Y0.pct", "R3_4_3_2_90Y150.pct", "2_4_4_2_0Y150.pct",
"3_3_3_2_0Y100.pct", "3_3_3_3_90Y50.pct" ],
"response time": [ 1355, 2079, 1834, 4780, 1685 ],
"expected answer": [ "[n]", "[n]", "[b]", "[b]", "[b]"],
"subject answer": [ "[n]", "[n]", "[b]", "[b]", "[b]"],
"rotation": [ 0, 150, 150, 100, 50 ]
}
Det är alltså ett dictionary med sex nycklar. Värdet till varje nyckel är en lista. Varje värde på ett visst index hör ihop med alla andra värden på samma index. T.ex. så hör det första elementet i listan till nyckeln “response time”, ihop med första elementet i listan till nyckeln “trial”.
Här kommer en förklaring till vad värdena betyder:
- Listan under nyckeln
"trial"innehåller benämningarna på varje försök som försökspersonen gjort. - Listan under nyckeln
"image"innehåller namnen på bilderna som visades. - Listan under nyckeln
"response time"innehåller värden som berättar hur lång tid det tog för försökspersonen att svara varje omgång. - Listan under nyckeln
"expected answer"innehåller det förväntade svaren."[b]"betyder att figurerna var lika och"[n]"betyder att figurerna inte var lika. - Listan under nyckeln
"subject answer"innehåller försökspersonens svar. - Listan under nyckeln
"rotation"berätar med hur många grader som den högra figuren i den visade bilden var roterad.
OBS! Ibland blir det fel vid datainsamling. Var därför uppmärksamma på att värden i vissa filer kan saknas. Om ett värde saknas av någon anledning står det "N/A". Detta är något ni behöver hantera i er kod. Se informationen om matplotlib.
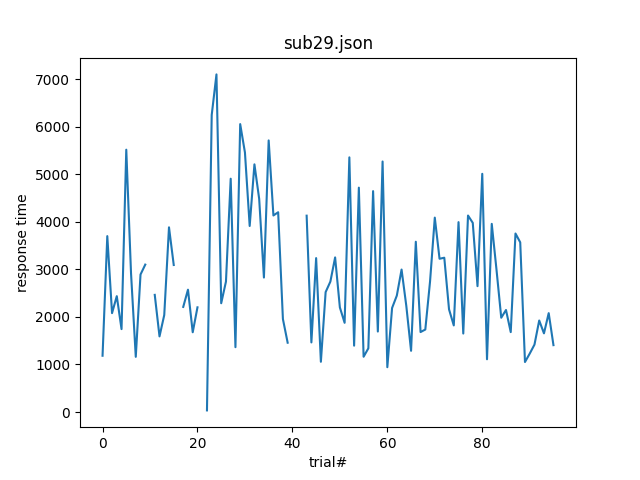
Uppgift 1: Diagram med resultat från enskild försöksperson
Skriv ett skript som producerar figurer som visar responstiden för en
försöksperson. Det ska anropas som ett skript från terminalen och få sökvägen
till den fil den ska skapa en figur för. Om det är filen sub29.json som
figuren hör ihop med ska bilden sparas med namnet sub29_time.png.
Exempel på anrop:
$ ./time_single.py data/sub29.json
och få upp något i stil med detta:
Viktigt
Dela upp er kod i minst två funktioner, dvs skriv inte all kod i en och samma funktion. En av funktionerna ska läsa in läsa in en fil och returnera inläst data.
Det är oftast alltid fördelaktigt att dela upp den kod man skriver i flera funktioner som löser var sitt delproblem, t.ex.
- en funktion som tar emot sökvägen till en fil och returnerar ett dictionary med informationen från den filen
- en funktion som tar emot en lista med responstider och skapar diagrammet för tiderna
Ni ska återanvända minst funktionen som läser in en fil från Uppgift 1 i både Uppgift 2 och Uppgift 3 genom att importera kodfilen som innehåller funktionen/funktionerna.
Om ni vill kan ni skapa en separat fil där ni lägger funktioner som är gemensamma för alla uppgifter.
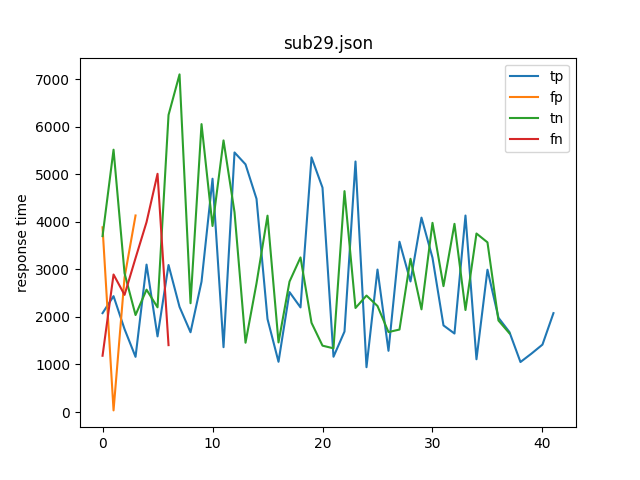
Uppgift 2: Diagram över responstider för olika feltyper/rotationer
Man kan klassificera ett försökspersonens svar som antingen en sann positiv (true positive, tp), falsk positiv (false positive, fp), sann negativ (true negative, tn), eller falsk negativ (false negative, fn)
- tp: sa “ja, de är lika” när det korrekta svaret var “ja”
- fp: sa “ja, de är lika” när det korrekta svaret var “nej”
- tn: sa “nej, de är inte lika” när det korrekta svaret var “nej”
- fn: sa “nej, de är inte lika” när det korrekta svaret var “ja”
I Uppgift 2 ska ni skriva ett skript som tar sökvägen till en fil som argument och producerar en bild som visar responstiderna för en försöksperson för varje klassificering. D.v.s. ett diagram med linje för alla responstider för alla tp, en för alla fp o.s.v.
Exempelanrop av skript:
$ ./time_errortype_single data/sub29.json
Ett exempel visas nedan (ni behöver inte lägga till en teckenförklaringsruta i er bild):
Viktigt
Dela upp er kod i flera funktioner, dvs skriv inte all kod i en och samma funktion. Uppdelningen ska motsvara en uppdelning av uppgiften i delproblem, t.ex.
- en funktion som tar emot användarens svar och det förväntade och returnerar en klassificering
- en funktion som tar emot data som ett dictionary och returnerar alla responstider med en viss klassificering
Tanken här är att ni ska öva på att bryta ner ett problem i konceptuella delproblem och implementera motsvarande lösningar som används tillsammans för att lösa det större problemet. Det är för övningens skull mindre viktigt att ert program är så effektivt som möjligt.
Återanvänd minst filinläsningsfunktionen från Uppgift 1 genom att läsa in koden från Uppgift 1 som en modul. Om ni vill kan ni skapa en fil som innehåller alla funktioner som är gemensamma för uppgift 1-3 (revidera tidigare uppgift(er) så att de(n) använder den i så fall).
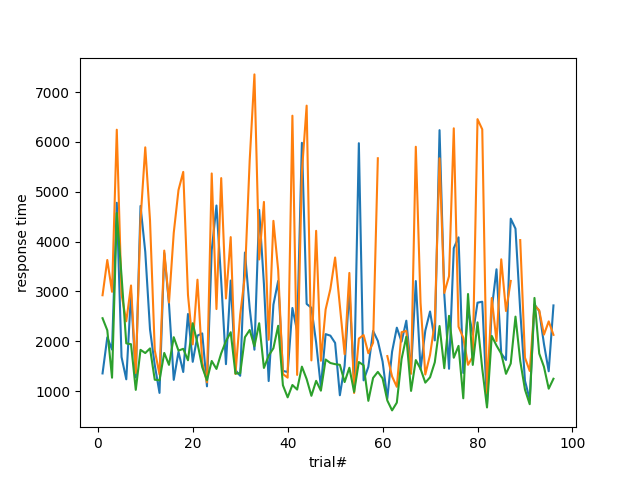
Uppgift 3a (G): Diagram med data från flera filer
Denna uppgift måste lösas för att få G i momentet LAB1. Uppgiften behöver inte lösas för att få VG i momentet LAB1.
Skriv ett skript som producerar ett diagram med responstiderna för flera försökspersoner samtidigt (alla i samma diagram). Uppgiften 2a ska alltså göra samma sak som Uppgift 1, fast för flera försökspersoner.
Exempel på anrop:
$ ./time_multi.py data/sub1.json data/sub11.json data/sub21.json
Viktigt
Dela upp er kod i flera funktioner, dvs skriv inte all kod i en och samma funktion. Uppdelningen ska motsvara en uppdelning av uppgiften i delproblem, t.ex.
- en funktion som tar en sökväg till en fil som argument och returnerar responstiderna från del filen
- en funktion som tar emot reponstider och lägger till dem till diagrammet
Tanken här är att ni ska öva på att bryta ner ett problem i konceptuella delproblem och implementera motsvarande lösningar som används tillsammans för att lösa det större problemet. Det är för övningens skull mindre viktigt att ert program är så effektivt som möjligt.
Återanvänd minst filinläsningsfunktionen från Uppgift 1 genom att läsa in koden från Uppgift 1 som en modul. Om ni vill kan ni skapa en fil som innehåller alla funktioner som är gemensamma för uppgift 1-3 (revidera tidigare uppgift(er) så att de(n) använder den i så fall).
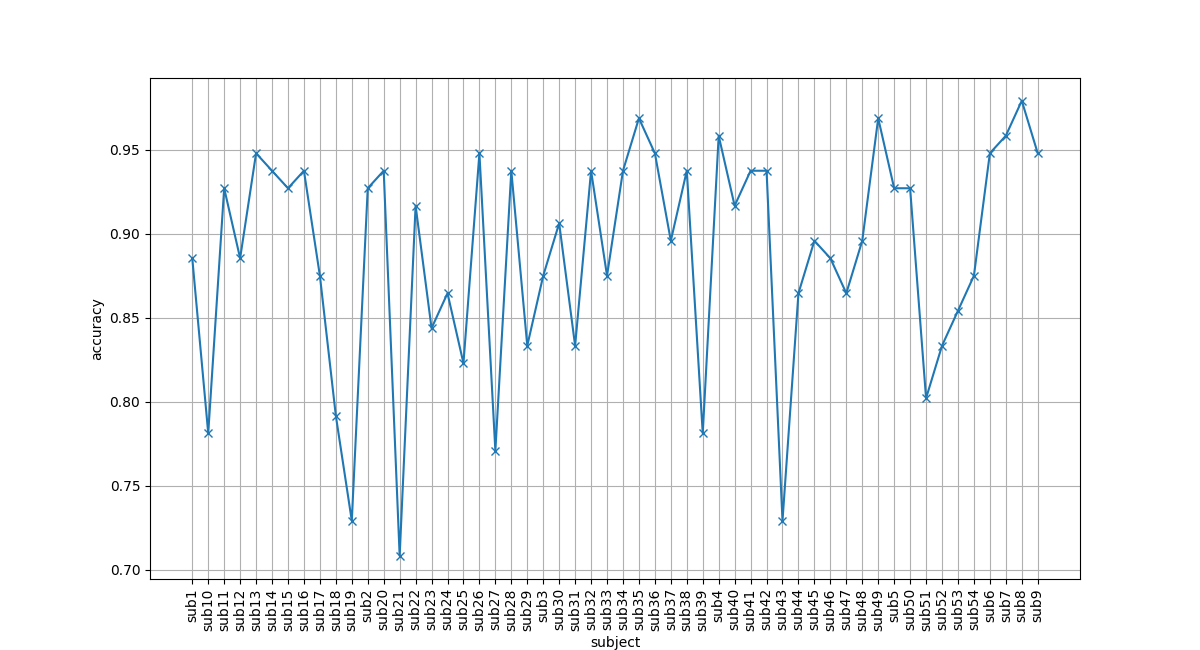
Uppgift 3b (VG): Diagram med data från flera filer
Denna uppgift måste lösas för att få VG i momentet LAB1. Uppgiften behöver inte lösas för att få G i momentet LAB1.
Skriv ett skript som producerar ett diagram som visar det som kallas för accuracy, dvs kvoten mellan antal rätt svar/antal svar.
Skriptet ska ta in en eller fler sökvägar till data-filer som argument.
Exempel på anrop:
$ ./plot_accuracy.py data/sub*.json
Exempel på figur:
Viktigt
Dela upp er kod i flera funktioner, dvs skriv inte all kod i en och samma funktion. Uppdelningen ska motsvara en uppdelning av uppgiften i delproblem.
Tanken här är att ni ska öva på att bryta ner ett problem i konceptuella delproblem och implementera motsvarande lösningar som används tillsammans för att lösa det större problemet. Det är för övningens skull mindre viktigt att ert program är så effektivt som möjligt.
Återanvänd minst filinläsningsfunktionen från Uppgift 1 genom att läsa in koden från Uppgift 1 som en modul. Om ni vill kan ni skapa en fil som innehåller alla funktioner som är gemensamma för uppgift 1-3 (revidera tidigare uppgift(er) så att de(n) använder den i så fall).
Sidansvarig: Johan Falkenjack
Senast uppdaterad: 2023-09-26