Föreläsningsöversikt (4)¶
- Om Tema 4-6
- Datalogiskt tänkande (Computational Thinking)
Temaupplägg, Tema 4-6¶
- Temauppgift: Tillämpning av ny syntax och/eller begrepp. (LAB2)
- 1 eller 3 poäng per temauppgift.
- Lektion: Förberedelse inför temauppgift.
- Seminarium: Genomgång och diskussion av temauppgiften i grupp. (EXA2)
- Rapport: Skriftlig behandling av aspekter av temauppgiften. (EXA2)
- 1-3 poäng per rapport.
Examination: resultat på delmoment¶
- LAB2. 4,5hp: Kod för Temauppgift 4-6
- EXA2. 1,5hp: Seminarier och Rapporter
- Betyg LAB2
- För betyget Godkänd på LAB2 ska alla temauppgifter vara godkända (1 poäng).
- För betyget Väl godkänd på LAB2 krävs minst 7 poäng totalt från temauppgifterna.
- Betyg EXA2
- För betyget Godkänd på EXA2 ska alla algoritmseminarier och algoritmrapporter vara inlämnade och godkända (1 poäng).
- För betyget Väl godkänd på EXA2 behövs minst 7 poäng totalt från rapporterna.
- För VG på kursen: VG på LAB1, LAB2 och EXA2
Alla uppgifter i Tema 4-6 görs i par¶
- Ni skall byta labbpartner.
- Slå er ihop med någon på samma nivå och med samma betygsambition.
- Anmäl er till en pargrupp i LAB2
- Deadline för anmälan 28 oktober, i praktiken bör ni ha valt partner innan det.
Övergripande läromål för Tema 4-6¶
- Datalogiskt tänkande:
- Abstraktion och dekomposition.
- Algoritmer och mönsterigenkänning.
- Programmering:
- Objektorienterad modellering och design
- Syntax i Python
- Programmeringsmetod (implementation, testning, felsökning)
Tema 4-6¶
- Tema 4: Sorteringalgoritmer och objekt
- Introduktion till datalogiskt tänkande och objektorientering
- Sorteringsalgoritmer
- Tema 5: Grafiska gränssnitt och layout
- Introduktion till GUI-programmering
- Algoritm för layout
- Tema 6: Eget att-göra-program
- Introduktion till objektorienterad design
- Objektorienterat program jämfört med icke-objektorienterat program
Datalogiskt tänkande¶

Vad är ett program?¶
"We are about to study the idea of a computational process. Computational processes are abstract beings that inhabit computers. As they evolve, processes manipulate other abstract things called data. The evolution of a process is directed by a pattern of rules called a program. People create programs to direct processes. In effect, we conjure the spirits of the computer with our spells."
--- Harold Abelson, Gerald Sussman, and Julie Sussman (1996) Structure and Interpretation of Computer Programs (2nd. ed.) McGraw-Hill, Inc., USA. (aka The Wizard Book)
Computational Thinking¶
"Computational thinking is the thought processes involved in formulating problems and their solutions so that the solutions are represented in a form that can be effectively carried out by an information-processing agent."
--- Wing, Jeannette M. (2011) Research Notebook: Computational Thinking—What and Why? The LINK. The Magazine of Carnegie Mellon University's School of Computer Science. Carnegie Mellon University, School of Computer Science.
Sammanfattningsvis¶
Datalogiskt tänkande är…
Ett sätt att tänka ut hur den ”beräkningsmässiga process” som Abelson och Sussman pratade om ska se ut, och…
Ett sätt att tänka ut hur program som beskriver den processen bör organiseras.
Är inte det samma sak som programmering?¶
- Programmering är det praktiska hantverket kring att realisera datalogiskt tänkande som faktiska program.
- Datalogiskt tänkande kan existera utan programmering.
- Programmering kan existera utan datalogiskt tänkande... men kanske inte med någon större framgång i det långa loppet.
Datalogiskt tänkande är inte…¶
- Att tänka i ettor och nollor.
- Vi måste dock ibland ta hänsyn till att datorn gör det
- Att tänka exakt som en dator.
- Vi måste dock förstå hur datorn ”tänker”.
- Att manuellt utföra en given algoritm med papper och penna.
- Vi måste dock förstå hur sådana algoritmer konstrueras och används för att lösa problem.
- Datorer som "tänker", dvs. artificiell intelligens.
- Men när man utvecklar AI-mjukvaror är datalogiskt tänkande självklart en del av processen.
- Datalogiskt tänkande är även tillämpbart för ”prompt engineering” när man använder generativ AI.
Ett exempelproblem¶
- Många språkteknologiska system, inklusive LLM:er som ChatGPT, bygger i någon utsträckning på frekvensinformation, dvs. hur många gånger olika ord förekommer i ett givet referensmaterial, eller textkorpus som vi säger inom lingvistiken.
- Som en liten försmak på språkteknologi ska vi, givet ett korpus av text lagrat i en textfil, skapa sådan frekvensdata.
- Texten vi ska utgå ifrån är Moby Dick av Herman Melville.
- Ord med olika kapitaliseringar skall räknas som lika, dvs "Hej" ska vara lika med "hej".
- Textfilen vi har fått är redan tokeniserad med följande egenskaper:
- Tokeniseringen har delat upp texten så att varje stycke står på en egen rad, och varje token (ord eller skiljetecken) är omringat av mellanslag. Tokeniseringen gör att vissa grammatiska strukturer står för sig. Till exempel blir strängen "it's" efter tokenisering "it ' s", och både "it" och "s" kan tolkas som ord.
- I det här fallet har vi beslutat att det är okej för dessa att tolkas som ord.
Första stycket från Moby Dick¶
Call me Ishmael . Some years ago - never mind how long precisely - having little or no money in my purse , and nothing particular to interest me on shore , I thought I would sail about a little and see the watery part of the world . It is a way I have of driving off the spleen and regulating the circulation . Whenever I find myself growing grim about the mouth ; whenever it is a damp , drizzly November in my soul ; whenever I find myself involuntarily pausing before coffin warehouses , and bringing up the rear of every funeral I meet ; and especially whenever my hypos get such an upper hand of me , that it requires a strong moral principle to prevent me from deliberately stepping into the street , and methodically knocking people ' s hats off - then , I account it high time to get to sea as soon as I can . This is my substitute for pistol and ball . With a philosophical flourish Cato throws himself upon his sword ; I quietly take to the ship . There is nothing surprising in this . If they but knew it , almost all men in their degree , some time or other , cherish very nearly the same feelings towards the ocean with me .
Vad behöver vi för att kunna lösa den här uppgiften?¶
Ett utkast¶
def calculate_word_frequencies_in_file(textfile):
tokenized_text = get_text_from_file(textfile)
token_list = get_tokens_from_string(tokenized_text)
for token in token_list:
count(token)
return frequencies
Dekomposition¶
Vi har precis delat upp ett svårt problem i mindre, mer hanterbara delproblem.
Delproblem kan i sin tur behöva delas upp i ännu mindre delproblem.
Sådan nedbrytning av problem kallas för dekomposition.
Dekomposition på flera nivåer¶
- Dela upp sin lösning i komponenter med ansvar för olika saker.
- T.ex. gränssnitt, datalagring, nätverk, databearbetning
- Dela upp en sådan komponent i funktioner som gör olika saker.
- T.ex. en funktion som skickar data över ett nätverk, en annan funktion som hämtar data från en nätverkskälla, etc.
- Dela upp en funktion i en serie diskreta operationer.
- T.ex. summera alla element och sedan dividera den summan med antalet element, för att räkna ut ett medelvärde.
- Göra en fallanalys för en villkorssats.
- T.ex. basfall och rekursionssteg i en rekursiv funktion.
- Dekomposition kan alltså ses som en rekursiv process.
Hur små delar behöver man bryta ner problem i?¶
- Beror på vilka byggstenar vi har när vi ska lösa ett visst problem.
Vilka byggstenar har vi då?
Komponenter vi kan importera från något annat paket, eventuellt skrivet av någon annan.
De som redan är implementerade av oss eller någon annan i det projekt vi arbetar.
Primitiver.
Primitiver¶
- Inbyggda komponenter i det programmeringsspråk vi använder.
- Vilka primitiver finns i Python?
Tillbaka till vårt utkast¶
def calculate_word_frequencies_in_file(textfile):
tokenized_text = get_text_from_file(textfile)
token_list = get_token_list(tokenized_text)
for token in token_list:
count(token)
return frequencies
- Är detta bästa möjliga uppdelningen?
- Kommer vi alltid bara vilja räkna ordfrekvenser i filer? Tänk om texten hämtas från webben istället?
En annan uppdelning¶
def calculate_word_frequencies(tokenized_text):
token_list = get_token_list(tokenized_text)
for token in token_list:
count(token)
return frequencies
def calculate_word_frequencies_in_file(textfile):
tokenized_text = get_text_from_file(textfile)
return calculate_word_frequencies(tokenized_text)
Abstraktion¶
- Här har vi abstraherat själva beräkningen av ordfrekvenser från att beräkna ordfrekvenser för en textfil.
- Oavsett varifrån vi får texten kommer vi kunna beräkna ordfrekvenser med
calculate_word_frequencies. - Även
get_text_from_filekan betraktas som en abstraktion, av själva filinläsningen. calculate_word_frequencies_in_fileknyter ihop de båda abstraktionerna och bildar en ny abstraktionsnivå.
Abstraktionsnivå¶
- Vi pratar ofta om att vi rör oss uppåt eller neråt i abstraktionsnivå.
- Genom att skapa en ny abstraktion går vi upp i abstraktionsnivå.
- Genom att titta på hur en abstraktion är implementerad går vi ner i abstraktionsnivå.
- Alla abstraktioner är sammansatta av primitiver och andra lägre abstraktioner.
- Även abstraktioner kan alltså i någon mening betraktas som rekursiva.
- Abstraktioner består av abstraktioner som består av abstraktioner... hela vägen ner till primitiverna.
Disclaimer¶
- Det finns i princip bara en kategori av människor som hävdar att abstraktioner gör saker lättare: Programmerare.
- Till och med matematiker erkänner att abstraktion är svårt.
- Varför hävdar vi programmerare något annat?
Abstraktioner hjälper oss att tänka¶
- Behöver inte tänka på alla detaljer utan vi kan arbeta med abstraktionen i sin helhet.
- Vi vet att
get_text_from_file("moby_dick_tokenized.txt")kommer returnera texten imoby_dick_tokenized.txt, hurget_text_from_fileåstadkommer det behöver vi inte fundera på.
- Vi vet att
- Låter oss lyfta blicken och fokusera på större problem som vi vill lösa utan att behöva slösa kognitiva resurser på detaljer.
- Absolut nödvändigt för alla moderna datortillämpningar.
- Orsaken till att laddningar i integrerade kretsar kan uttrycka bilden ni just nu ser och texten ni läser är en lång kedja av abstraktioner.
Dekomposition eller abstraktion?¶

Växelverkan mellan dekomposition och abstraktion¶
Vi går ner en abstraktionsnivå och implementerar get_text_from_file¶
def calculate_word_frequencies_in_file(textfile):
tokenized_text = get_text_from_file(textfile)
return calculate_word_frequencies(tokenized_text)
def get_text_from_file(filename):
with open(filename) as f:
return f.read()
if __name__ == "__main__":
# test code:
print(get_text_from_file("moby_dick_tokenized.txt")[:500])
MOBY - DICK ; or , THE WHALE . By Herman Melville CHAPTER 1 . Loomings . Call me Ishmael . Some years ago - never mind how long precisely - having little or no money in my purse , and nothing particular to interest me on shore , I thought I would sail about a little and see the watery part of the world . It is a way I have of driving off the spleen and regulating the circulation . Whenever I find myself growing grim about the mouth ; whenever it is a damp , drizzly November in my soul ; wheneve
Vi skiftar tillbaka till calculate_word_frequencies¶
- Först måste vi implementera
get_token_list.
def calculate_word_frequencies(tokenized_text):
token_list = get_token_list(tokenized_text)
for token in token_list:
count(token)
return frequencies
def get_token_list(tokenized_text):
return tokenized_text.split()
if __name__ == "__main__":
# test code:
test_text = "Hej hej !\nHej då . "
print(test_text)
print(get_token_list(test_text))
Hej hej ! Hej då . ['Hej', 'hej', '!', 'Hej', 'då', '.']
Hur ska vi göra med count?¶
def count(token):
pass
Repetition: Abstrakta datatyper (ADT)¶

Exempel på abstrakt datatyp¶
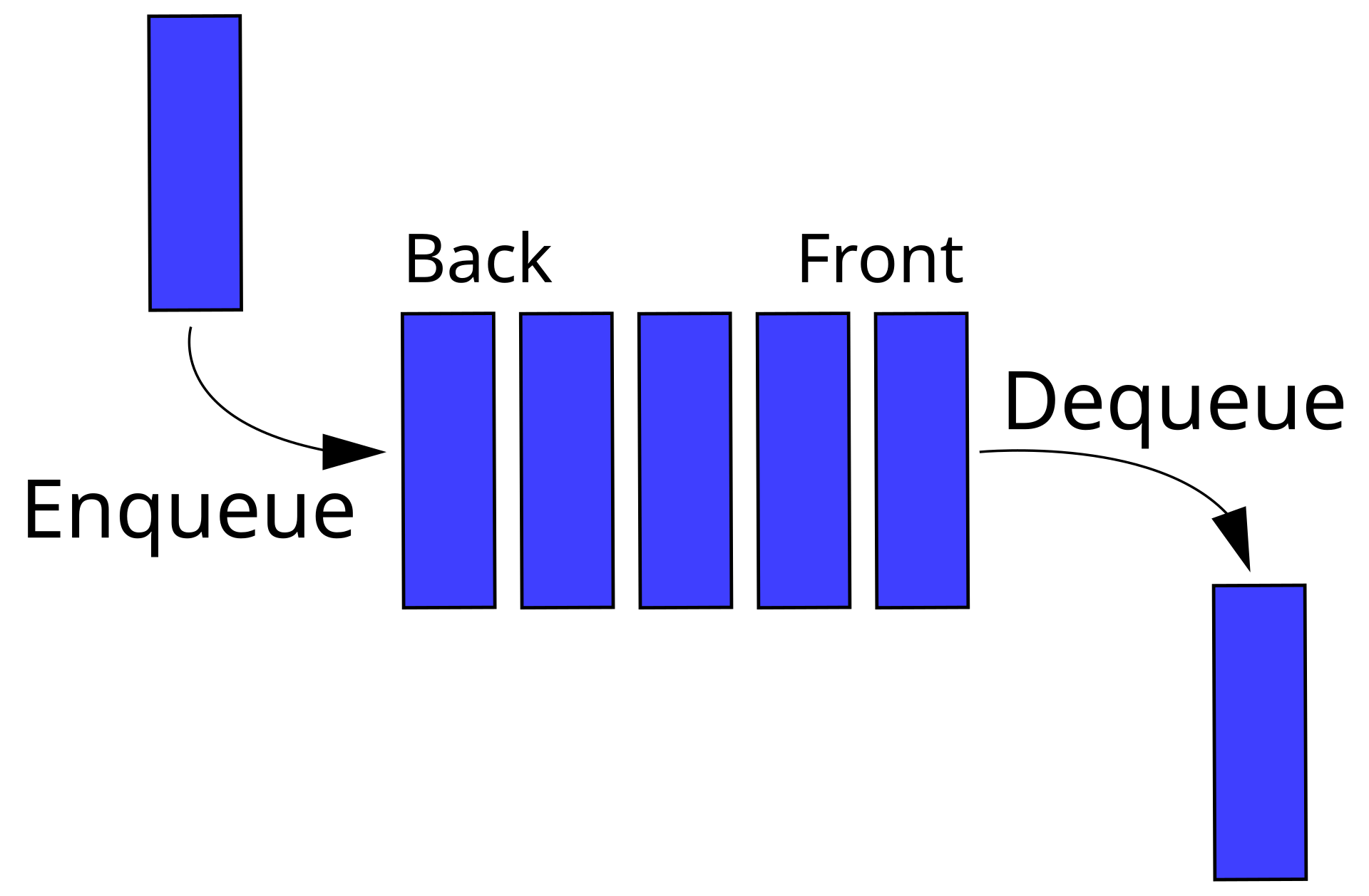
- Kö (eng. queue)
- lista med element är kön, index
0är nästa på tur - funktionen
create_empty_queue()som returnerar en tom kö - funktionen
enqueue(value, queue)som lägger till värdetvaluetill slutet på könqueue - funktionen
dequeue(queue)som returnerar värdet som är först i kön och plockar även bort det från kön
- lista med element är kön, index
Implementation av kö-ADT:n¶
def create_empty_queue():
return ('queue', [])
def enqueue(value, queue):
if queue[0] == 'queue':
queue[1].append(value)
else:
raise TypeError("Not a queue")
def dequeue(queue):
if queue[0] == 'queue':
if queue[1]:
return queue[1].pop(0)
else:
return None
else:
raise TypeError("Not a queue")
Implementation av kö-ADT:n¶
q = create_empty_queue()
print(1, q)
enqueue('a', q)
print(2, q)
enqueue('b', q)
print(3, q)
print(4, f"{dequeue(q)=}")
print(5, q)
enqueue('c', q)
print(6, q)
1 ('queue', [])
2 ('queue', ['a'])
3 ('queue', ['a', 'b'])
4 dequeue(q)='a'
5 ('queue', ['b'])
6 ('queue', ['b', 'c'])
print(7, f"{dequeue(q)=}")
print(8, f"{dequeue(q)=}")
print(9, f"{dequeue(q)=}")
7 dequeue(q)='b' 8 dequeue(q)='c' 9 dequeue(q)=None
En abstrakt datatyp för att räkna förekomster¶
def make_counter():
return ('counter', dict())
def add_occurrence(value, counter):
if counter[0] == 'counter':
if value in counter[1].keys():
counter[1][value] += 1
else:
counter[1][value] = 1
else:
raise TypeError('Not a counter')
def lookup_occurrences(value, counter):
if counter[0] == 'counter':
if value in counter[1].keys():
return counter[1][value]
else:
return 0
else:
raise TypeError('Not a counter')
def get_all_counts(counter):
if counter[0] == 'counter':
return counter[1]
else:
raise TypeError('Not a counter')
Vår räkne-ADT i calculate_word_frequencies¶
def calculate_word_frequencies(tokenized_text):
token_list = get_token_list(tokenized_text)
frequencies = make_counter()
for token in token_list:
add_occurrence(token.lower(), frequencies)
return get_counts(frequencies)
if __name__ == "__main__":
# test code:
test_text = "Hej hej !\nHej då . "
print(test_text)
print(calculate_word_frequencies(test_text))
Hej hej !
Hej då .
{'hej': 3, '!': 1, 'då': 1, '.': 1}
Hur kom jag på det så snabbt?¶
Jag har sett liknande problem förut.
Vi människor är experter på mönsterigenkänning, vi kan träna oss att applicera det på problemlösning.
Mönsterigenkänning¶
Har vi sett liknande problem förut?
Vad har de problemen gemensamt med vårt aktuella problem och vad har de för skillnader?
Vet vi något om hur problemet kan angripas baserat på mönstret vi känner igen?
Typer av beräkningsproblem, formellt sett¶
Beslutsproblem (eng. Decision problem)
- Finns det någon lösning?
Räkningsproblem (eng. Counting problem)
- Hur många lösningar finns det?
Sökningsproblem (eng. Search problem)
- Hitta en lösning.
Optimeringsproblem (eng. Optimization problem)
- Välj bästa möjliga lösning.
Funktionsproblem (eng. Function problem)
- Om det finns en eller flera lösningar, ge en av dem, annars svara att ingen lösning existerar.
Är alla problem någon av de 5 typerna?¶
På rätt abstraktionsnivå är väldigt många problem det, men...
I praktiken kan man hitta många andra typer av mindre abstrakta mönster som man med tiden lär sig känna igen.
- Som t.ex. en ADT för att räkna förekomster.
De faktiska mönstren lär man sig med tiden bara man lär sig att hålla utkik efter dem.
- Erfarenhet inom många områden handlar om mängden mönster man lärt sig känna igen och hur man bäst drar nytta av dem.
Hur drar vi nytta av mönsterigenkänning?¶
Om vi känner igen en typ av problem kanske vi känner till, eller åtminstone vet att det finns/inte finns, en eller flera möjliga lösningar på den typen av problem.
Sådana lösningar kallas för algoritmer.
Algoritmer, generaliseringar av processer¶
En algoritm är en metod som, givet ett väldefinierat utgångsläge, löser ett problem genom att ett ändligt antal elementära och väldefinierade operationer tillämpas i en förskriven ordning.
--- Lunell. 2011. Datorn i världen, världen i datorn
Exempel på algoritmer¶
- Informella:
- Knyta skorna
- Morgonrutin
- Recept för maträtter
- Formella:
- Addition/subtraktion/multiplikation med uppställning
- Långdivison (liggande stolen eller trappan)
- Matrismultiplikation
- Binärsökning
När är en lösning en algoritm?¶
- Input: Vad är indata? Vad vet vi? Vad behöver vi veta? Hur representerar vi data?
- Formulera problemet: Gör problemet väldefinierat: För vilka input vill vi kunna komma fram till en lösning? Vilka är normalfallen? Finns extremfall?
- Output: Hur ser en lösning ut? Vad är en korrekt lösning? Finns flera korrekta lösningar? Finns det en bästa lösning?
- Formulera lösningen: Gör lösningen väldefinierad. Hur vet vi att något är en lösning?
Hela vår lösning¶
def make_counter():
return ('counter', dict())
def add_occurrence(value, counter):
if counter[0] == 'counter':
if value in counter[1].keys():
counter[1][value] += 1
else:
counter[1][value] = 1
else:
raise TypeError('Not a counter')
def lookup_occurrences(value, counter):
if counter[0] == 'counter':
if value in counter[1].keys():
return counter[1][value]
else:
return 0
else:
raise TypeError('Not a counter')
def get_all_counts(counter):
if counter[0] == 'counter':
return counter[1]
else:
raise TypeError('Not a counter')
def calculate_word_frequencies(tokenized_text):
token_list = get_token_list(tokenized_text)
frequencies = make_counter()
for token in token_list:
add_occurrence(token.lower(), frequencies)
return frequencies
def get_token_list(tokenized_text):
return tokenized_text.split()
def calculate_word_frequencies_in_file(textfile):
tokenized_text = get_text_from_file(textfile)
return calculate_word_frequencies(tokenized_text)
def get_text_from_file(textfile):
with open(textfile) as f:
return f.read()
if __name__ == "__main__":
# test code:
freq = calculate_word_frequencies_in_file("moby_dick_tokenized.txt")
print(f"{lookup_occurrences('the', freq)=}")
print(f"{lookup_occurrences('whale', freq)=}")
print(f"{lookup_occurrences('captain', freq)=}")
print(f"{lookup_occurrences('queequeg', freq)=}")
lookup_occurrences('the', freq)=14175
lookup_occurrences('whale', freq)=1152
lookup_occurrences('captain', freq)=327
lookup_occurrences('queequeg', freq)=252
