Föreläsningsöversikt¶
- Om fusk, igen
- Info om duggan
- Viktigast från Tema 2
- Pythonskript som program
- Moduler, importera fil som modul
- Oföränderliga och föränderliga värden
- Nya klasser:
tupleochdict - Mer om dataabstraktion
- Nästlade datastrukturer
- Bearbetning av nästlade datastrukturer
- Rekursion
Om fusk, igen¶
- Det är några studenter som lämnat in kod på Pythonuppgifterna som de inte verkar ha skrivit själva.
- Det är kanske inte uppenbart för er, men vi ser ganska tydligt när en uppgift inte passar in.
- Jag vill upprepa att jag och assistenterna formellt sett är skyldiga att anmäla misstänkt fusk till disciplinnämnden.
- Det är en skyldighet vi ofta väljer att tumma på när studenter visar sig villiga att rätta till saken
- ...men det finns gränser.
- Disciplinärenden kan leda till avstängning från studierna, det är svårt att komma tillbaka från, speciellt med de konsekvenser detta ofta har för t.ex. studiemedel, rätt till studentlägenhet, etc.
Vad händer nu?¶
- Några av er har blivit kontaktade av assistenter för att redogöra för hur ni kommit fram till vissa lösningar när lösningen "sticker ut".
- I andra fall har vi valt att avvakta för att göra en helhetsbedömning av inlämnade pythonuppgifter efter Tema 3.
- Ni som vet att ni lämnat in kod ni fått av en klasskamrat eller av t.ex. ChatGPT och inte blivit kontaktade av en assistent, ta en funderare på hur ni vill göra med Pythonuppgift 3 och hur ni vill att vår helhetsbedömning ska falla ut.
- En missad deadline innebär att man hamnar några daga efter och blir tvungen att jobba ifatt.
- En avstängning innebär att man hamnar några månader efter och löper stor risk att helt behöva avbryta studierna, möjligtvis för alltid.
Inte fusk, men olyckligt¶
- Några av er har skickat in era pythonuppgifter i Sendlab-kön för kursen TDDE44.
- Också min kurs och gör samma pythonuppgifter, men går för andra program och på vårterminen.
- Detta är dock helt olika Sendlab-köer och det var ren tur att en assistent i TDDE44 upptäckte detta då den kursen är avslutad sedan i juni.
- Oklart hur detta ens gått till då det inte finns någon länk till Sendlab för TDDE44 på vår kurshemsida, men kolla noggrant när ni lämnar in i Sendlab att det verkligen är rätt Sendlab-sida som ni använder.
- Det ska stå 729G46_HT24 som rubrik.
Dugga 28/10, kl. 14.00-16.00¶
- Anmälan via LiU-appen eller studentportalen.
- Utan anmälan, ingen dugga. Sista anmälningsdatum 10 dagar innan duggan.
- Tillåtet stödmaterial:
- Kurslitteratur (bok/utskrift) utan anteckningar
- Pythondokumentationen som PDF eller websida (se kurshemsidan)
- 1 A4-sida egna anteckningar (enkelsidigt)
- Kod/Föreläsningsbilder/övriga anteckningar ej tillåtet
Dugga 28/10, kl. 14.00-16.00¶
- Kom i tid. Duggan börjar 14.00, prick!
- Innan måste ni ha legitimerat er, hängt av er, loggat in, fått ev. böcker kontrollerade.
Dugga 28/10, kl. 14.00-16.00¶
- I SU-sal, ni använder Thonny eller Visual Studio Code + terminal
- Personliga inställningar och hemkatalog kommer inte vara tillgängliga
- Se till att ni vet hur ni testkör era program (gör inte misstaget att lämna in kod ni inte testat)
- Uppgifter liknar Pythonuppgifter 2-3, se exempeldugga på kurshemsidan
- Kommunikation (chat) med Johan samt inlämning sker via tenta-klient
- Assistent för hjälp med tekniska problem kommer finnas på plats
Dugga 28/10, kl. 14.00-16.00¶
- Live-rättning, dvs duggan rättas direkt och ni får resultatet i tentaklienten.
- 2-30 minuters väntetid beroende på hur många som lämnar in samtidigt.
- Möjlighet att komplettera i mån av tid.
- Räkna inte med tid att komplettera, satsa på att göra rätt direkt.
Prova-på dugga 15/10, kl. 8.15-9.00 och 9.15-10.00¶
- Till för att prova tentasystemet, inte för att visa representativa uppgifter.
- En person i varje labbpar kommer kl 8, den andra kommer kl 9, kom överens sinsemellan vem som ska komma vilken tid.
Viktigast från Tema 2¶
- När bör
while- resp.for-loop användas? - Namngivning av variabler, funktioner och parametrar
- mönster, t.ex.
for word in words - undvik allt för generella namn
- mönster, t.ex.
Repetition: for- loop eller while-loop?¶
- Mindre logistik om vi itererar över en sekvens med
for:
values = list(range(100))
i = 0
while i < len(values):
value = values[i]
if value == 42:
print("I found the answer!")
i += 1
for value in values:
if value == 42:
print("I found the answer!")
I found the answer! I found the answer!
Repetition: Varför finns ens while-loopen?¶
while-loopar är nödvändiga om man vill fortsätta loopa under vissa förutsättningar - villkor - snarare än över en viss sekvens.
import random
secret_word = random.choice(["apelsin", "banan", "citron"])
guess = None
tries = 0
while guess != secret_word:
if guess != None:
print("Fel!")
guess = input("Gissa vilket ord jag tänker på: ")
tries += 1
print("Rätt! Det tog " + str(tries) + " försök.")
Gissa vilket ord jag tänker på: apelsin Fel! Gissa vilket ord jag tänker på: banan Rätt! Det tog 2 försök.
Repetition: Namngivning av funktioner och variabler¶
- Försök att använda beskrivande funktions- och variabelnamn.
- Koden blir lättare att läsa.
- Använd verbliknande namn för funktioner
add_numbers(),calculate_volume(),load_file(),find_most_common_word()
- Använd substantiv till variabelnamn.
- Bra att döpa listor till substantiv i plural:
words,values,names - Vanligt mönster vid användning av
for-loop:
for word in words:
Värden och referenser¶
Oföränderliga värden¶
- I Python är strängar, heltal, flyttal, sanningsvärden,
Noneoch tupler oföränderliga (eng. immutable). - Detta betyder att man inte kan ändra på dessa värden.
- t.ex. så kan inte ändra värdet
5till värdet1, värdet5är alltid5. - Python behandlar strängar på samma sätt; i Python kan vi inte ändra strängen
"hej"till strängen"nej"
- t.ex. så kan inte ändra värdet
Vänta lite, vi har ju ändrat på både heltal och strängar!¶


Hur många försökte följande lösning?¶
def replace_periods_with_newlines(string_value):
for character in string_value:
if character == '.':
character = '\n'
return string_value
print(replace_periods_with_newlines("hej.hur mår du.jag mår bra!"))
hej.hur mår du.jag mår bra!
Den här då?¶
def replace_periods_with_newlines(string_value):
i = 0
while i < len(string_value):
if string_value[i] == '.':
string_value[i] = '\n'
i += 1
return string_value
print(replace_periods_with_newlines("hej.hur mår du.jag mår bra!"))
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[104], line 9 6 i += 1 7 return string_value ----> 9 print(replace_periods_with_newlines("hej.hur mår du.jag mår bra!")) Cell In[104], line 5, in replace_periods_with_newlines(string_value) 3 while i < len(string_value): 4 if string_value[i] == '.': ----> 5 string_value[i] = '\n' 6 i += 1 7 return string_value TypeError: 'str' object does not support item assignment
Vi var tvugna att använda en ackumulator¶
def replace_periods_with_newlines(string_value):
result = ""
for character in string_value:
if character == '.':
result += '\n'
else:
result += character
return result
print(replace_periods_with_newlines("hej.hur mår du.jag mår bra!"))
hej hur mår du jag mår bra!
App, app, app! Vänta lite! Vi ändrar ju på result där! Har vi inte bara bytt vilket värde vi ändrar?¶

Vad är en variabel över huvud taget?¶
Variabler som referenser till värden¶
- I de flesta fall är det enklast att se variabler som "etiketter" som refererar till värden.
- En tilldelningssats, t.ex.
result = "", kan ses som att vi säger "låt etiketten result referera till värdet ..."
Vad gör vi egentligen med result?¶
def replace_periods_with_newlines(string_value):
result = ""
for character in string_value:
if character == '.':
result += '\n'
else:
result += character
return result
print(replace_periods_with_newlines("hej.hur mår du.jag mår bra!"))
Föränderliga värden¶
- Av de datatyper som vi stött på så tillhör listor kategorin förändringsbara (eng. mutable) värden.
- Detta betyder att vi kan ändra på dessa värden.
- Vi kan t.ex. byta ut första elementet i listan
[1, 2, 3]till5
numbers = [1, 2, 3]
print(numbers)
numbers[0] = 5
print(numbers)
[1, 2, 3] [5, 2, 3]
Jämförelse¶
numbers_list = [1, 2, 3]
print(numbers_list)
numbers_list[0] = 5
print(numbers_list)
[1, 2, 3] [5, 2, 3]
numbers_string = "123"
print(numbers_string)
numbers_string[0] = "5"
print(numbers_string)
123
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[108], line 3 1 numbers_string = "123" 2 print(numbers_string) ----> 3 numbers_string[0] = "5" 4 print(numbers_string) TypeError: 'str' object does not support item assignment

Tillbaka till referenser¶
- Vi kan låta olika variabler referera till samma värde:
my_list = [1, 2, 3]
other_list = my_list
print(other_list)
[1, 2, 3]
Konsekvenser¶
my_list = [1, 2, 3]
other_list = my_list
my_string = "123"
other_string = my_string
print(f"{my_list=}")
print(f"{other_list=}")
print(f"{my_string=}")
print(f"{other_string=}")
my_list=[1, 2, 3] other_list=[1, 2, 3] my_string='123' other_string='123'
my_list += [4]
my_string += "4"
print(f"{my_list=}")
print(f"{other_list=}")
print(f"{my_string=}")
print(f"{other_string=}")
my_list=[1, 2, 3, 4] other_list=[1, 2, 3, 4] my_string='1234' other_string='123'
Blir det alltid så?¶
my_list = [1, 2, 3]
other_list = my_list
my_string = "123"
other_string = my_string
print(f"{my_list=}")
print(f"{other_list=}")
print(f"{my_string=}")
print(f"{other_string=}")
my_list=[1, 2, 3] other_list=[1, 2, 3] my_string='123' other_string='123'
my_list = my_list + [4]
my_string = my_string + "4"
print(f"{my_list=}")
print(f"{other_list=}")
print(f"{my_string=}")
print(f"{other_string=}")
my_list=[1, 2, 3, 4] other_list=[1, 2, 3] my_string='1234' other_string='123'
- Nu blev det ju likadant!
- Det kluriga är augmented assignment för muterbara datatyper.
Kan vi göra det här lite mindre otydligt?¶
my_list = [1, 2, 3]
other_list = my_list
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3] other_list=[1, 2, 3]
my_list.extend([4, 5])
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3, 4, 5] other_list=[1, 2, 3, 4, 5]
- Om vi använder
extendså ändrar vi i objektet. - Detsamma gäller för
append.
Men om...¶
my_list = [1, 2, 3]
other_list = my_list
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3] other_list=[1, 2, 3]
my_list = my_list + [4]
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3, 4] other_list=[1, 2, 3]
- Använder vi
=-operatorn så får vi ett nytt objekt.
Så vad gör += för listor?Syntaktiskt socker för list.extend()¶
my_list = [1, 2, 3]
other_list = my_list
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3] other_list=[1, 2, 3]
my_list += [4]
print(f"{my_list=}")
print(f"{other_list=}")
my_list=[1, 2, 3, 4] other_list=[1, 2, 3, 4]
Vad händer när vi skickar föränderliga värden till funktioner?¶
def change_and_return_list(a_list):
a_list.append("list was changed")
return a_list
my_list = [1, 2, 3]
other_list = my_list
third_list = change_and_return_list(my_list)
print(my_list)
print(other_list)
print(third_list)
[1, 2, 3, 'list was changed'] [1, 2, 3, 'list was changed'] [1, 2, 3, 'list was changed']
Beror på vad funktionen gör!¶
def change_and_return_list(a_list):
a_list = a_list + ["list was changed"]
return a_list
my_list = [1, 2, 3]
other_list = my_list
third_list = change_and_return_list(my_list)
print(my_list)
print(other_list)
print(third_list)
[1, 2, 3] [1, 2, 3] [1, 2, 3, 'list was changed']
Tupel (eng. Tuple)¶
- Delar namn med de tupler vi diskuterade i föreläsningen om grafteori, men är formellt sett n-tupler, dvs. de kan ha vilket antal element som helst.
- Skrivs på samma sätt som listor, fast med vanliga parenteser.
- Vi kan referera till element och delsekvenser med samma notation som för listor
my_tuple = (1, 3, 'a')
print(my_tuple[0])
print(my_tuple[1:])
1 (3, 'a')
Tupel-lista-konvertering¶
- Vi kan enkelt skapa en lista med alla element från en tupel och vice versa.
- Notera att varje gång vi gör en sådan "konvertering" så skapas en ny lista/tupel.
print(list(my_tuple))
my_list = (7, 9, 'e')
print(tuple(my_list))
[1, 3, 'a'] (7, 9, 'e')
Tupel vs. Lista - Muterbarhet är skillnaden¶
numbers_list = [1, 2, 3]
print(numbers_list)
numbers_list[0] = 5
print(numbers_list)
[1, 2, 3] [5, 2, 3]
numbers_tuple = (1, 2, 3)
print(numbers_tuple)
numbers_tuple[0] = 5
print(numbers_tuple)
(1, 2, 3)
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[9], line 3 1 numbers_tuple = (1, 2, 3) 2 print(numbers_tuple) ----> 3 numbers_tuple[0] = 5 4 print(numbers_tuple) TypeError: 'tuple' object does not support item assignment
- Men varför? Listor verkar så mycket mer flexibelt.
- Säkerhet. Ibland vill vi vara säkra på att ett objekt inte kan förändras.
Dictionary¶

- Dictionary eller
dicti Python.- Mer generellt: associationslista (eng. associative array, symbol table, map)
- Kärt barn har många namn.
- Nyckel-värde-par
- Värden hämtas med hjälp av nyckel istället för index som i fallet med listor och tupler.
- Alla datatyper som är oföränderliga (immutable) kan användas som nycklar, t.ex. flyttal, heltal, strängar, tupler
- Alla datatyper kan vara värden
Syntax¶
dict_example = {"key1": "value 1", 345: "value 2", 3: 54 }
print(dict_example["key1"])
value 1
Iterera över en dict¶
- Punktnotation för att komma åt alla
- nycklar:
dict.keys() - värden:
dict.values() - nyckel-värdepar:
dict.items() - ("
dict" refererar här till ett godtyckligt värde av typen dictionary, denna notation används även i pythondokumentationen)
- nycklar:
- Metoderna
dict.keys(),dict.values()ochdict.items()returnerar olika "vyer".- Vyer kan liknas vid listor.
Iterera över nycklar¶
dict_example = {"key1": "value 1", 345: "value 2", 3: 54 }
for key in dict_example.keys():
print(key)
key1 345 3
Iterera över värden¶
dict_example = {"key1": "value 1", 345: "value 2", 3: 54 }
for key in dict_example.values():
print(key)
value 1 value 2 54
Om vi vill ha både nycklar och värden då?¶
- Dåligt sätt:
dict_example = {"key1": "value 1", 345: "value 2", 3: 54 }
for key in dict_example.keys():
print(key, ":", dict_example[key])
key1 : value 1 345 : value 2 3 : 54
Om vi vill ha både nycklar och värden då?¶
- Bättre sätt:
dict_example = {"key1": "value 1", 345: "value 2", 3: 54 }
for key, value in dict_example.items():
print(key, ":", value)
key1 : value 1 345 : value 2 3 : 54
Dataabstraktion¶

Abstraktion¶
- programabstraktion: dela upp problem i delproblem, dela upp en funktion i flera funktioner
- dataabstraktion: koppla ihop och strukturera information
Dataabstraktion¶
# en variabel per värde
pokemon_name = "pidgey"
ability1 = "big-pecks"
ability2 = "tangled-feet"
ability3 = "keen-eye"
- Hur gör vi om vi vill ha information om fler eller färre "abilities" på ett smidigt sätt?
Dataabstraktion¶
pokemon_name = "pidgey"
# listor kan användas för att lagra 0 eller fler värden
abilities = ["big-pecks", "tangled-feet", "keen-eye"]
- Listor kan användas för information som kan innehålla fler än ett värde.
- Hur gör vi om vi vill ha information om flera pokemons? Ska vi ha
pokemon_name1,pokemon_name2,abilities1,abilities2?
Dataabstraktion¶
pokemon1 = ["pidgey", ["big-pecks", "tangled-feet", "keen-eye"]]
pokemon2 = ["ditto", ["imposter", "limber"]]
- Vi kan samla ihop informationen om varje pokemon till en lista samt bestämma den ordning som informationen ska komma i.
Dataabstraktion¶
pokemon = [ ["pidgey", ["big-pecks", "tangled-feet", "keen-eye"]],
["ditto", ["imposter", "limber"]] ]
- Vi kan också samla ihop alla pokemon-listor i en lista.
Dataabstraktion¶
pokemon = [ { "name": "pidgey",
"abilities": ["big-pecks", "tangled-feet", "keen-eye"] },
{ "name": "ditto",
"abilities": ["imposter", "limber"] } ]
- Vi hade även kunnat använda ett dictionary för att representera en Pokémon.
Dataabstraktion¶
pokemon = {"pidgey": { "name": "pidgey",
"abilities": ["big-pecks", "tangled-feet", "keen-eye"] },
"ditto": { "name": "ditto",
"abilities": ["imposter", "limber"] }}
- Här har vi istället för en lista använt ett dictionary som har namnen på pokemons som nyckel och dictionaryt med all pokemon-information som värde.
Dataabstraktion¶
pokemon = {"johsj47": { "name": "johan falkenjack",
"abilities": ["insomnia", "oblivious", "gluttony"] } }
- Här har vi istället för en lista använt ett dictionary som har namnen på pokemons som nyckel och dictionaryt med all pokemon-information som värde.
Abstrakta datatyper (ADT)¶
- "Programming with abstract data types" (1974). Barbara Liskov & Stephen Zilles.
- Abstrakt datatyp
- datastruktur baserad på någon mer primitiv datatyp, t.ex. en lista
- funktioner som används på dessa datastrukturer
- poängen är att abstrahera bort onödig komplexitet
- Föregångare till en objektorienterad approach.
- Vi har redan pratat om en ADT: Stack.
Exempel på abstrakt datatyp¶
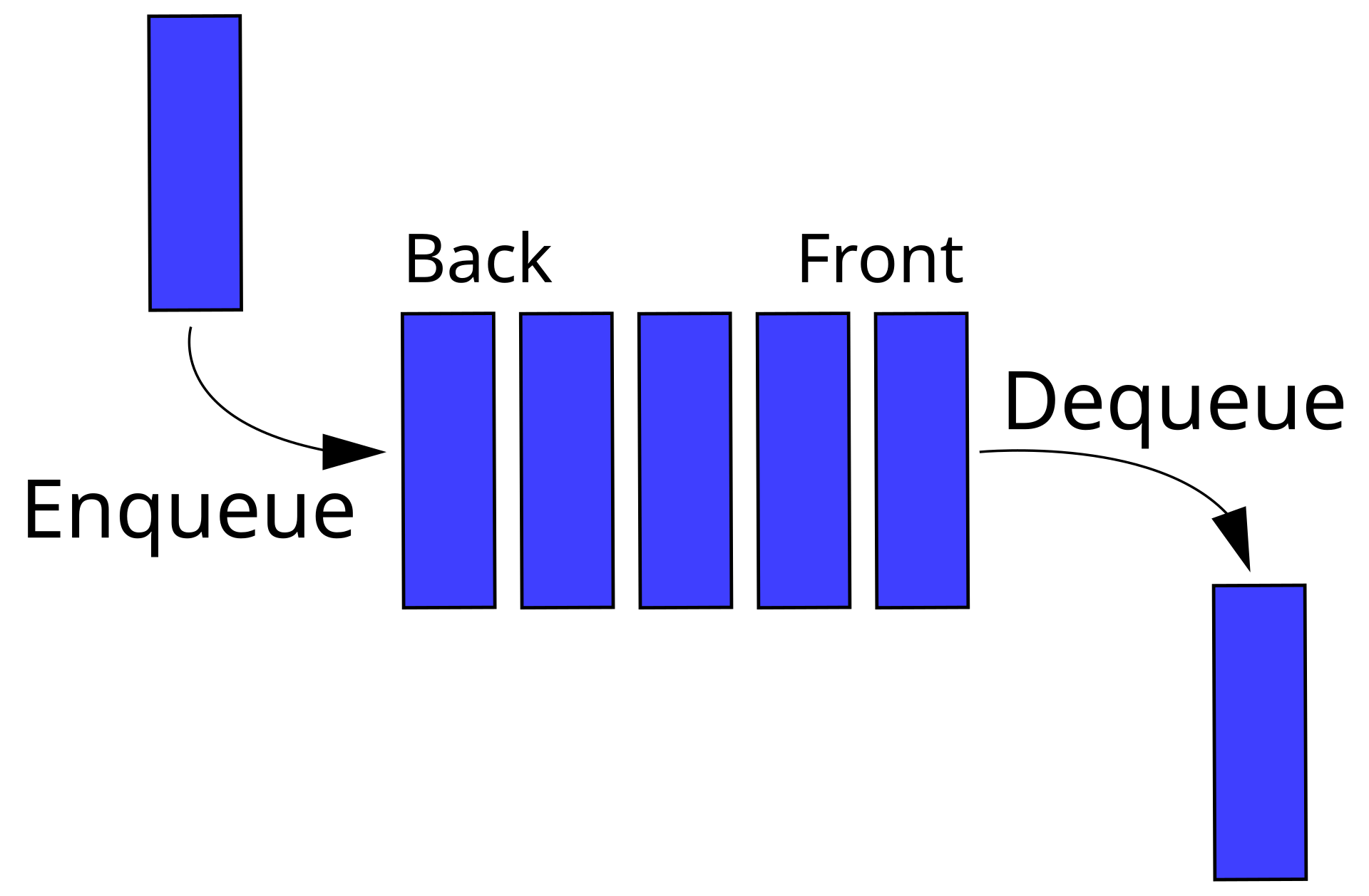
- Kö (eng. queue)
- lista med element är kön, index
0är nästa på tur - funktionen
create_empty_queue()som returnerar en tom kö - funktionen
enqueue(value, queue)som lägger till värdetvaluetill slutet på könqueue - funktionen
dequeue(queue)som returnerar värdet som är först i kön och plockar även bort det från kön
- lista med element är kön, index
(Jätte)enkel kö i Python¶
def create_empty_queue():
return []
def enqueue(value, queue):
queue.append(value)
def dequeue(queue):
return queue.pop(0)
q = create_empty_queue()
print(1, q)
enqueue('a', q)
print(2, q)
enqueue('b', q)
print(3, q)
print(4, f"{dequeue(q)=}")
print(5, q)
enqueue('c', q)
print(6, q)
1 [] 2 ['a'] 3 ['a', 'b'] 4 dequeue(q)='a' 5 ['b'] 6 ['b', 'c']
print(7, f"{dequeue(q)=}")
print(8, f"{dequeue(q)=}")
print(9, f"{dequeue(q)=}")
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) Cell In[138], line 1 ----> 1 print(7, f"{dequeue(q)=}") 2 print(8, f"{dequeue(q)=}") 3 print(9, f"{dequeue(q)=}") Cell In[136], line 8, in dequeue(queue) 7 def dequeue(queue): ----> 8 return queue.pop(0) IndexError: pop from empty list
- Väldigt enkel, helt upp till oss att hålla reda på att
qfaktiskt är en kö. - Det är bara en kö för att vi använder det som en kö, egentligen bara en vanlig lista.
- Ingen felhantering.
(Pytte)lite mer avancerad kö i Python¶
def create_empty_queue():
return ('queue', [])
def enqueue(value, queue):
if queue[0] == 'queue':
queue[1].append(value)
else:
raise TypeError("Not a queue")
def dequeue(queue):
if queue[0] == 'queue':
if queue[1]:
return queue[1].pop(0)
else:
return None
else:
raise TypeError("Not a queue")
(Pytte)lite mer avancerad kö i Python¶
q = create_empty_queue()
print(1, q)
enqueue('a', q)
print(2, q)
enqueue('b', q)
print(3, q)
print(4, f"{dequeue(q)=}")
print(5, q)
enqueue('c', q)
print(6, q)
1 ('queue', [])
2 ('queue', ['a'])
3 ('queue', ['a', 'b'])
4 dequeue(q)='a'
5 ('queue', ['b'])
6 ('queue', ['b', 'c'])
print(7, f"{dequeue(q)=}")
print(8, f"{dequeue(q)=}")
print(9, f"{dequeue(q)=}")
7 dequeue(q)='b' 8 dequeue(q)='c' 9 dequeue(q)=None
Stop! Tupler var ju inte muterbara!¶

Hur ser vår datastruktur ut?¶

q = create_empty_queue()
Hur ser vår datastruktur ut?¶

q = create_empty_queue()
Hur ser vår datastruktur ut?¶

q = create_empty_queue()
enqueue('a', q)
Hur ser vår datastruktur ut?¶

q = create_empty_queue()
enqueue('a', q)
enqueue('b', q)
Hur ser vår datastruktur ut?¶

q = create_empty_queue()
enqueue('a', q)
enqueue('b', q)
print(f"{dequeue(q)=}")
dequeue(q)='a'
Hur ser vår datastruktur ut?¶

q = create_empty_queue()
enqueue('a', q)
enqueue('b', q)
dequeue(q)
enqueue('c', q)
Men om elementet i sig är muterbart, så kan vi ändra på det.¶
Bearbetning av nästlade datastrukturer¶
Nästlade datastrukturer¶
- $A$ är en nästlad datastruktur om
- $A$ innehåller flera värden
- Ett av värdena i $A$ i sin tur innehåller flera värden
list_of_lists = [["Ada Lovelace", 1815], ["Joan Clarke", 1917]]
list_of_dicts = [ { "name": "Ada Lovelace", "birthyear": 1815 }, { "name": "Joan Clarke", "birthyear": 1815 } ]
dict_with_some_list_value = { "name": "ditto", "abilities": ["imposter", "limber"] }
Hur kommer vi åt nästlade värden?¶
lista1 = [["a", "b", "c"], ["d", "e", "f"]]
# första elementet i lista1
print(f"{lista1[0]=}")
# första elementet i första elementet i lista1
print(f"{lista1[0][0]=}")
# andra elementet i första elementet i lista1
print(f"{lista1[1][1]=}")
lista1[0]=['a', 'b', 'c'] lista1[0][0]='a' lista1[1][1]='e'
Hur kommer vi åt nästlade värden?¶
dict1 = { "frukter": ["a", "b", "c"],
"bilar": ["d", "e", "f"] }
# värdet associerat med nyckeln "frukter"
print(f"{dict1['frukter']=}")
# första elementet i listan associerad med nyckeln "frukter"
print(f"{dict1['frukter'][0]=}")
# andra elementet i listan associerad med nyckeln "frukter"
print(f"{dict1['frukter'][1]=}")
dict1['frukter']=['a', 'b', 'c'] dict1['frukter'][0]='a' dict1['frukter'][1]='b'
En nästlad loop för att bearbeta en nästlad datastruktur¶
outer_list = [ ["a", "b", "c"], ["d", "e", "f", "g"] ]
# om vi för varje inre lista i outer_list vill skriva ut den inre listans element?
outer_index = 0
while outer_index < len(outer_list):
inner_list = outer_list[outer_index]
# kod som skriver ut varje element i inner_list
inner_index = 0
while inner_index < len(inner_list):
print(inner_list[inner_index])
inner_index += 1
outer_index += 1

Vi har faktiskt någon typ av sekvenser... for!¶
outer_list = [ ["a", "b", "c"], ["d", "e", "f", "g"] ]
# om vi för varje inre lista i outer_list vill skriva ut den inre listans element?
for inner_list in outer_list:
# kod som skriver ut varje element i inner_list
for inner_element in inner_list:
print(inner_element)
a b c d e f g
Nästlade strukturer med dictionaries¶
Bearbeta lista av dictionaries 1¶
pokemons = [ { "name": "bulbasaur", "abilities": ["chlorophyll", "overgrow"] },
{ "name": "squirtle", "abilities": ["rain-dish", "torrent"] } ]
def print_dictionaries(list_of_dictionaries):
# gå igenom listan med dictionaries
for dictionary in list_of_dictionaries:
# gå igenom alla nycklar i aktuellt dictionary
for key in dictionary.keys():
print(f"The key {key} has the value: {dictionary[key]}")
print("pokemons:")
print_dictionaries(pokemons)
pokemons: The key name has the value: bulbasaur The key abilities has the value: ['chlorophyll', 'overgrow'] The key name has the value: squirtle The key abilities has the value: ['rain-dish', 'torrent']
Bearbeta lista av dictionaries 1¶
books = [ { "title": "Introduction to Python", "pages": 314 },
{ "title": "Another introduction to Python", "pages": 413 } ]
print("books:")
print_dictionaries(books)
books: The key title has the value: Introduction to Python The key pages has the value: 314 The key title has the value: Another introduction to Python The key pages has the value: 413
Bearbeta lista av dictionaries 2¶
def print_dictionaries(list_of_dictionaries):
# gå igenom listan med dictionaries
for dictionary in list_of_dictionaries:
# gå igenom alla nycklar i varje dictionary
for key, value in dictionary.items():
# i de fall som värdet för en nyckel är en lista
if type(value) == list:
print(f"Value of key '{key}' is a list:")
# skriv ut varje värde i listan dictionary[key]
for element in value:
print(f"- {element}")
# när värdet i dictionaryt inte är en lista
else:
print(f"The key '{key}' has the value: {value}")
Bearbeta lista av dictionaries 2¶
print("pokemons:")
print_dictionaries(pokemons)
print("\nbooks:")
print_dictionaries(books)
pokemons: The key 'name' has the value: bulbasaur Value of key 'abilities' is a list: - chlorophyll - overgrow The key 'name' has the value: squirtle Value of key 'abilities' is a list: - rain-dish - torrent books: The key 'title' has the value: Introduction to Python The key 'pages' has the value: 314 The key 'title' has the value: Another introduction to Python The key 'pages' has the value: 413
Leta efter värde i nästlad lista¶
blandad_lista = [ "a", ["b", "c"], "d", "e", ["f", "g"] ]
def look_for_value(needle, haystack):
# bearbeta yttre listan
for value in haystack:
# bearbetning av yttre värden som är listor
if type(value) == list:
for inner_value in value:
if inner_value == needle:
return True
# om yttre värde inte är en lista, kolla om det är det vi letar efter
elif value == needle:
return True
return False
look_for_value("c", blandad_lista)
Operatorn in¶
Operatorer: repetition¶
- Exempel på operatorer:
- +, *, -, /, and, or, not
- Operatorer kan ses som funktioner
plus(x, y)minus(x, y)funktionen_or(True, False)funktionen_not(True)
- Argument till operatorer kallas för operander
- Operatorer är oftast binära (tar exakt två argument), eller unära (tar exakt ett argument)
Operatorerna in och not in¶
- Operatorn in är en binär operator som undersöker medlemsskap.
- Operanderna är ett värde och en behållare, t.ex. sekvenser eller dictionary-vyer.
- Exempel på sekvenser är: strängar, listor, tupler, dictionaries (implicit dess nycklar)
- Operatorn
inreturnerarTrueom värdet är en medlem i behållaren. - Operatorn
not inreturnerarTrueom värdet inte är en medlem i behållaren.
Exempel¶
l = [10, "tre", 3.14]
print("tre" in l)
print("fyra" not in l)
True True
wordlist = { "bil" : "car", "fisk": "fish" }
print("fisk" in wordlist)
print("fish" in wordlist)
True False
Rekursion¶

Rekursion¶
- Självlikhet eller självreferens.
- Fenomen som i sin struktur innehåller en mindre variant av sig själva.
- Träd, med grenar, som har grenar, som har grenar...
- Världskarta, som består av kartor över länder, som innehåller kartor över städer, som innehåller kartor över kvarter...
- En mening kan innehålla en bisats, som kan innehålla en bisats, som kan innehålla en bisats...
- Processer som innehåller sig själva som ett delsteg.
- Surdeg, där den viktigaste ingrediensen är? Surdeg.
- Att gå upp för en trappa med $n$ steg, som består av att först gå upp för en trappa med $1$ trappsteg...
Droste-effekten¶

"Memeception" - ett vanligt missförstånd¶

- Filmen Inception handlade till stor del om rekursion (drömmar i drömmar), och memes som innehöll exempel på rekursion använde ofta suffixet "-ception" som en referens till filmen. Ordet "inception" har i sig inget med rekursion att göra.
- Codeception och Listception
Side note, när vi ändå pratar om vanliga missförstånd ;)¶
radkommentar $\neq$ hashtag¶
- Tecknet
#kallas, bland annat, för hash (också number sign, pound sign, brädhög, brädgård, gärdsgård, stege, staket, spjälstaket, fyrkant, vedstapel, haga, stockhög, grind, fyrtagg, etc.). - En hashtag är en metadatatag som indikerats med ett hashtecken.
- Vanligt i sociala medier för att ange etiketter, nyckelord, teman, etc.
- Andra tag-system förekommer med olika formalismer i olika sammanhang, t.ex. @-tags för att tagga en viss användare är också vanligt i sociala medier.
- En radkommentar (i Python och många andra programmeringsspråk) är en text som följer efter ett
#-tecken och som innebär att resten av raden ignoreras av Pythontolken.- Många språk använder
#för radkommentarer, t.ex. Bash och andra Unix-skal, PHP (ibland), R, PowerShell, Perl, Ruby, Make, Julia, m.fl. - Andra programmeringsspråk använder andra tecken/teckensekvenser för att indikera radkommenterer, t.ex.
//(JavaScript, PHP, C/C++, Java, C#, Go, Objective-C, Swift, m.fl.),;(Assembly, Lisp, AHK, m.fl.),--(SQL, Ada, Haskell, m.fl.),'(Visual Basic, m.fl.),%(LaTeX, Prolog, Erlang, MATLAB, m.fl.)
- Många språk använder
En sista rekursiv bild¶
Okej, en till...¶
Vad har detta med programmering att göra?¶
- Rekursiva datastrukturer.
- T.ex. listor som kan innehålla listor, som kan innehålla listor, som kan...
- Grafer, där varje möjlig delgraf i sig är en graf.
- T.ex. använder vi ofta grafer för att representera kartor.
- Rekursiva processer.
- Funktioner som direkt anropar sig själva.
- Funktioner som i en ändlig kedja av funktionsanrop anropar sig själva, t.ex. funktion $A$ anropar funktion $B$ och funktion $B$ i sin tur anropar $A$.
Komponenter i en enkel rekursiv funktion¶
def rec_fun(input):
if *stoppvillkor*:
return *trivialt basfall*
else:
return do_something(input) *kombinerat med* rec_fun(*ett värde härlett från input*)
Summera en lista av heltal med for-loop¶
- Vi vill summera listan
[1, 2, 75, 6, 7]
def sum_list_for(values):
result = 0
for value in values:
result += value
return result
print(f"{sum_list_for([1, 2, 75, 6, 7])=}")
sum_list_for([1, 2, 75, 6, 7])=91
Summera en lista av heltal med rekursion¶
- Vi vill summera listan
[1, 2, 75, 6, 7]
def sum_list_rec(values):
if values == []:
return 0
else:
return values[0] + sum_list_rec(values[1:])
print(f"{sum_list_rec([1, 2, 75, 6, 7])=}")
sum_list_rec([1, 2, 75, 6, 7])=91
Jaha, men hur kom vi på det då?¶

Rekursiv problemlösning¶
- För att lösa ett problem rekursivt, behöver vi formulera eller dela upp det på ett sådant sätt så att delarna är enklare varianter av det större problemet.
- Om vi har problemet summera talen
1,2,75,6och7. Att uttrycka det som1 + 2 + 75 + 6 + 7är att försöka lösa allt på en gång. - Ett alternativt sätt är uttrycka det som
1+ summan av de resterande talen;2, 75, 6, 7 - Summan av de resterande talen i sin tur kan vi uttrycka på samma sätt,
2+ summan av de resterande talen;75, 6, 7 - Vi har hittat ett sätt att formulera problemet så att vi kan tillämpa samma lösning på mindre och mindre varianter av samma problem.
Ett första försök¶
def sum_list_rec(values):
return values[0] + sum_list_rec(values[1:])
print(f"{sum_list_rec([1, 2, 75, 6, 7])=}")
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) Cell In[13], line 4 1 def sum_list_rec(values): 2 return values[0] + sum_list_rec(values[1:]) ----> 4 print(f"{sum_list_rec([1, 2, 75, 6, 7])=}") Cell In[13], line 2, in sum_list_rec(values) 1 def sum_list_rec(values): ----> 2 return values[0] + sum_list_rec(values[1:]) Cell In[13], line 2, in sum_list_rec(values) 1 def sum_list_rec(values): ----> 2 return values[0] + sum_list_rec(values[1:]) [... skipping similar frames: sum_list_rec at line 2 (3 times)] Cell In[13], line 2, in sum_list_rec(values) 1 def sum_list_rec(values): ----> 2 return values[0] + sum_list_rec(values[1:]) IndexError: list index out of range
Ett första försök - fel när values == []¶
- Vad bör anropet
sum_list_rec([])bli?
Summera en lista av heltal med rekursion¶
- Vi vill summera listan
[1, 2, 75, 6, 7]
def sum_list_rec(values):
if values == []:
return 0
else:
print(f"return {values[0]} + sum_list_rec({values[1:]})")
return values[0] + sum_list_rec(values[1:])
print(f"{sum_list_rec([1, 2, 75, 6, 7])=}")
return 1 + sum_list_rec([2, 75, 6, 7]) return 2 + sum_list_rec([75, 6, 7]) return 75 + sum_list_rec([6, 7]) return 6 + sum_list_rec([7]) return 7 + sum_list_rec([]) sum_list_rec([1, 2, 75, 6, 7])=91
Mönster för att skriva en rekursiv funktion¶
- Vi letar efter det "enklaste" fallet av problemet som ska lösas, basfallet.
- Basfallet är det problemfall som är så enkelt att svaret är givet.
- Basfallet följs sedan av ett eller flera rekursiva anrop på en "enklare" variant av ursprungsproblemet.
- Se till att alla
return-satser returnerar värde av samma datatyp.
Nytt problem: summan av alla tal från $0$ till $n$?¶
- Vad är summan av alla tal från $0$ till $n$?
- Summan av alla tal från $n$ till $0$?
- Vad är summan av alla tal från $n$ till $0$?
- $n$ $+$ summan av alla tal från $(n-1)$ till $0$
- Vad är summan av alla tal från $(n-1)$ till $0$?
- $(n-1)$ $+$ summan av alla tal från $(n-2)$ till $0$
- osv ...
Iterativ summa från $0$ till $n$¶
def sum_0_to(n):
result = 0
for i in range(n+1):
result += i
return result
print(f"{sum_0_to(100)=}")
sum_0_to(100)=5050
Rekursiv summa från $0$ till $n$¶
def sum_0_to(n):
if n == 0:
return 0
else:
return n + sum_0_to(n-1)
print(f"{sum_0_to(100)=}")
sum_0_to(100)=5050
Är rekursion verkligen nödvändigt?¶
- Formellt sett... nej.
- Church-Turing-satsen, som bevisade att den Universella Turing-maskinen är ekvivalent med $\lambda$-kalkylen, innebär också att alla rekursiva funktioner kan skrivas om till iterativa funktioner, och vice versa.
- En kurs i programmeringsteori kan vara lämplig för den nyfikne.
Är rekursion alltid "krångligare" än iteration?¶
- Smaksak och vanesak.
- Vissa problem är till sin natur rekursiva och väldigt krångliga att lösa med iteration.
- Problem som kan brytas ner i mindre likadana delar löses ofta enklare och mer lättläst med rekursion än med iteration.
- Rekursion har stor betydelse inom språkbehandling, artificiell intelligens, databehandling, visualisering, etc.
- Varför började vi ens prata om rekursion?
- Rekursion lämpar sig särskilt bra för att hantera nästlade datastrukturer när vi inte vet hur många nivåer av nästling som kan förekomma.
Varning för globala variabler och rekursion¶
Den andra funktionen ger 0 poäng på duggan...¶
def keep_strings_good(values):
if not values:
return []
elif type(values[0]) == str:
return [values[0]] + keep_strings_good(values[1:])
else:
return keep_strings_good(values[1:])
answer = []
def keep_strings_bad(values):
if len(values) > 0:
if type(values[0]) == str:
answer.append(values[0])
keep_strings_bad(values[1:])
return answer
# men det funkar ju eller?
print(keep_strings_good(["ett", 2, "sjuttiofem", 6, 7]))
print(keep_strings_bad(["ett", 2, "sjuttiofem", 6, 7]))
['ett', 'sjuttiofem'] ['ett', 'sjuttiofem']
Den andra funktionen ger 0 poäng på duggan...¶
- kan vi använda funktionerna flera gånger?
print("Två anrop till keep_strings_good()")
print(keep_strings_good(["ett", 2, "sjuttiofem", 6, 7]))
print(keep_strings_good(["ett", 2, "sjuttiofem", 6, 7]))
print("\nTvå anrop till keep_strings_bad()")
print(keep_strings_bad(["ett", 2, "sjuttiofem", 6, 7]))
print(keep_strings_bad(["ett", 2, "sjuttiofem", 6, 7]))
Två anrop till keep_strings_good() ['ett', 'sjuttiofem'] ['ett', 'sjuttiofem'] Två anrop till keep_strings_bad() ['ett', 'sjuttiofem', 'ett', 'sjuttiofem', 'ett', 'sjuttiofem', 'ett', 'sjuttiofem'] ['ett', 'sjuttiofem', 'ett', 'sjuttiofem', 'ett', 'sjuttiofem', 'ett', 'sjuttiofem', 'ett', 'sjuttiofem']
Räcker det att flytta in answer i funktionen?¶
def keep_strings_bad(values):
answer = []
if len(values) > 0:
if type(values[0]) == str:
answer.append(values[0])
keep_strings_bad(values[1:])
return answer
print(keep_strings_bad(["ett", 2, "sjuttiofem", 6, 7]))
['ett']
Platt lista som trädstruktur¶

[ 1, 2, 3]- Problem: Vad är summan av alla löv?
- Alla noder är löv, dvs alla noder har värden.
- Vi anropar
sum_rec([ 1, 2, 3])
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 1, 2, 3]- Problem: Vad är summan av alla löv?
- Noden är ett löv.
- Beräkna 1 + summan av övriga värden.
sum_recanropas med resten av listan som argument:sum_rec([ 2, 3])
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 2, 3]- Problem: Vad är summan av alla löv?
- Alla noder är löv, dvs alla noder har värden.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 2, 3]- Problem: Vad är summan av alla löv?
- Noden är ett löv.
- Beräkna 2 + summan av övriga värden.
sum_recanropas med resten av listan som argument:sum_rec([ 3])
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 3]- Problem: Vad är summan av alla löv?
- Alla noder är löv, dvs alla noder har värden.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 3]- Problem: Vad är summan av alla löv?
- Noden är ett löv.
- Beräkna 3 + summan av övriga värden.
sum_recanropas med resten av listan som argument:sum_rec([ ])
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ ]- Problem: Vad är summan av alla löv?
- Inga noder finns.
- Summan av inga värden är 0 så vi returnerar 0.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 3]- Problem: Vad är summan av alla löv?
- Summan är värdet på detta löv, 3, + summan av övriga värden, vilket nu har beräknats till 0.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 3]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 3.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 2, 3]- Problem: Vad är summan av alla löv?
- Summan är värdet på detta löv, 2, + summan av övriga värden, vilket nu har beräknats till 3.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 2, 3]- Problem: Vad är summan av alla löv?
- Summan är värdet på detta löv, 2, + summan av övriga värden, vilket nu har beräknats till 3.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 2, 3]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 5.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 1, 2, 3]- Problem: Vad är summan av alla löv?
- Summan är värdet på detta löv, 1 + summan av övriga värden, vilket nu har beräknats till 5.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 1, 2, 3]- Problem: Vad är summan av alla löv?
- Summan är värdet på detta löv, 1 + summan av övriga värden, vilket nu har beräknats till 5.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Platt lista som trädstruktur¶

[ 1, 2, 3]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 6.
def sum_rec(values):
if not values:
return 0
else:
return values[0] + sum_rec(values[1:])
Jorå, såatte... varför göra det på det här knöliga sättet när vi har loopar?¶

Nästlade strukturer kan ses som trädstrukturer¶

[1, [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Om nod inte är ett löv:
- Noden är ett delträd, beräkna summan av delträdet.
- (Summan av ett delträd är beräknas på samma sätt som summan av ett träd.)
Nästlade strukturer kan ses som trädstrukturer¶
def sum_rec_nest(values):
# om vi inte har några värden är summan 0
if not values:
return 0
# om noden inte är ett värde, räkna ut delträdets värde och addera det till
# resten av värdena
elif type(values[0]) == list:
return sum_rec_nest(values[0]) + sum_rec_nest(values[1:])
# noden är ett löv, addera dess värde till resten av värdena i trädet
else:
return values[0] + sum_rec_nest(values[1:])
sum_rec_nest([1, 2, 3])
6
sum_rec_nest([1, [2, 3], [[4, 5], 6]])
21
sum_rec_nest([1, [2, 3], [[4, 5, [6, 7, [8]]], 9]])
45
Nästlade strukturer kan ses som trädstrukturer¶

[1, [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Noden är ett löv: Beräkna 1 + summan av resten
sum_rec_nestanropas på resten av listan:sum_rec_nest([ [2, 3], [ [4, 5], 6 ] ])
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Noden är ett delträd: Beräkna summan av delträdet + summan av resten
sum_rec_nestanropas på första noden:sum_rec_nest([2, 3])

Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3] ]- Problem: Vad är summan av alla löv?
- Beräkna summan av delträdet.
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3] ]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 5.
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Summan av första noden är 5: Beräkna 5 + summan av resten
sum_rec_nestanropas på resten av listan:sum_rec_nest([ [ [4, 5], 6 ] ])
Nästlade strukturer kan ses som trädstrukturer¶

[ [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
Nästlade strukturer kan ses som trädstrukturer¶

[ [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Noden är ett delträd: Beräkna summan av delträdet + summan av resten
sum_rec_nestanropas på första noden:sum_rec_nest([ [4, 5], 6 ])

Nästlade strukturer kan ses som trädstrukturer¶

[ [4, 5], 6 ]Problem: Vad är summan av alla löv?
Noden är ett delträd: Beräkna summan av delträdet + summan av resten
sum_rec_nestanropas på första noden:sum_rec_nest([4, 5])

Nästlade strukturer kan ses som trädstrukturer¶

[4, 5]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 9
Nästlade strukturer kan ses som trädstrukturer¶

[ [4, 5], 6 ]Problem: Vad är summan av alla löv?
Summan av första noden är 9: Beräkna 9 + summan av resten
sum_rec_nestanropas på resten av listan:sum_rec_nest([ 6 ])→ 6
Nästlade strukturer kan ses som trädstrukturer¶

[ [4, 5], 6 ]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 15
Nästlade strukturer kan ses som trädstrukturer¶

[ [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Summan har beräknats till 15
- Returnera summan, dvs 15
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Summan av första noden är beräknad till 5
- Summan av resten är beräknad till 15
Nästlade strukturer kan ses som trädstrukturer¶

[ [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 5 + 15
Nästlade strukturer kan ses som trädstrukturer¶

[1, [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Summan av resten har beräknats till 20
Nästlade strukturer kan ses som trädstrukturer¶

[1, [2, 3], [ [4, 5], 6 ] ]- Problem: Vad är summan av alla löv?
- Returnera summan, dvs 21
Leta efter ett värde i en nästlad lista¶
def look_for_value_rec_all(value, values):
print(values)
# Inget värde kan finnas i en tom lista
if not values:
return False
# om första värdet inte är en lista, kolla om det är det värde
# vi letar efter, returnera i så fall True
elif values[0] == value:
return True
# om första värdet är en lista, returnera resultatet av att
# leta i både den listan och resten av values
elif type(values[0]) == list:
return (look_for_value_rec_all(value, values[0]) or
look_for_value_rec_all(value, values[1:]))
# om inte första värdet varken var en lista eller det vi letade efter
# returnera resultatet av att leta efter värdet i resten av listan
else:
return look_for_value_rec_all(value, values[1:])
look_for_value_rec_all('a', ['b', ['c', [['d'], 'a']]])
['b', ['c', [['d'], 'a']]] [['c', [['d'], 'a']]] ['c', [['d'], 'a']] [[['d'], 'a']] [['d'], 'a'] ['d'] [] ['a']
True
Spara enbart strängar i en nästlad lista, men bevara strukturen på listan¶
def keep_strings_rec_all(values):
# om listan är tom så resultatet en tom lista
if not values:
return []
# om första värdet i listan är en sträng så är resultatet
# en lista med den strängen + alla strängar i resten av values
elif type(values[0]) == str:
return [values[0]] + keep_strings_rec_all(values[1:])
# om första värdet är en lista är resultatet en lista med listan
# utan några andra datatyper än strängar + bearbetningen av resten
# av listan
elif type(values[0]) == list:
return [keep_strings_rec_all(values[0])] + \
keep_strings_rec_all(values[1:])
# om första värdet i listan inte var en sträng så är resultatet
# alla strängar i resten av listan
else:
return keep_strings_rec_all(values[1:])
print(keep_strings_rec_all(["ett", [2, "sjuttiofem", 6], 7, [[75], [6, ["sju"]]]]))
Rekursiva funktioner kan "utforska" flera olika lösningsvägar med trädrekursion¶

- Exempel: En karta med enkelriktade vägar representeras som en graf.
- Problem: Givet en startpunkt A kan vi ta oss till platsen B? Returnera vägen.
- Representation: Vi representerar grafen som ett dictionary där nycklarna är noder vars värde är en lista med de noder vi kan nå från nyckel-noden.
map1 = {"a": ["b", "c"],
"b": [],
"c": ["d"],
"d": ["a"],
"e": ["b"]}
Hitta vägen¶
def get_path(s_node, e_node, a_map, visited):
"""Returnera en lista med vägen från s_node till e_node om sådan finns."""
# är e_node direkt tillgänglig?
if e_node in a_map[s_node]:
return visited + [s_node, e_node]
# kolla om vi kan ta oss till e_node från någon av grannarna till s_node
return get_path_hlp(a_map[s_node], e_node, a_map, visited + [s_node])
def get_path_hlp(s_nodes, e_node, a_map, visited):
"""Returnera den första vägen från en nod i s_nodes till e_node om sådan finns."""
# om s_nodes är tom så kan vi inte ta oss till e_node
if not s_nodes:
return []
# om vi inte redan besökt s_nodes[0]
elif s_nodes[0] not in visited:
# kolla om vi kan ta oss till e_node därifrån eller någon av de övriga
# nodern i s_nodes
path = get_path(s_nodes[0], e_node, a_map, visited)
if path:
return path
else:
return get_path_hlp(s_nodes[1:], e_node, a_map, visited)
# om vi redan besökt s_nodes[0]
else:
# kolla om vi kan ta oss till e_node från någon av de övriga noderna
# i s_nodes
return get_path_hlp(s_nodes[2:], e_node, a_map, visited)
Rekursiva funktioner kan "utforska" flera olika lösningsvägar med trädrekursion¶
- Exempel: En karta med enkelriktade vägar representeras som en graf.
- Problem: Givet en startpunkt A kan vi ta oss till platsen B? Returnera vägen.
- Representation: Vi representerar grafen som ett dictionary där nycklarna är noder vars värde är en lista med de noder vi kan nå från nyckel-noden.
map1 = {"a": ["b", "c"],
"b": [],
"c": ["d"],
"d": ["a"],
"e": ["b"]}
print(get_path('c', 'b', map1, []))
['c', 'd', 'a', 'b']
Hitta vägen (med for-loop)¶
Ibland är den bästa lösningen att kombinera rekursion med vanliga loop-konstruktioner.
def get_path_with_for(s_node, e_node, a_map, visited):
"""Returnera en lista med vägen från s_node till e_node om sådan finns."""
# är e_node direkt tillgänglig?
if e_node in a_map[s_node]:
return visited + [s_node, e_node]
# kolla om vi kan ta oss till e_node från någon av grannarna till s_node
for next_node in a_map[s_node]:
if next_node not in visited:
path = get_path_with_for(next_node, e_node, a_map, visited + [s_node])
if path:
return path
# om vi kommer hit kunde vi inte hitta någon väg
return []
print(get_path_with_for('c', 'b', map1, []))
['c', 'd', 'a', 'b']
Större karta¶

map2 = {"a": ["d"],
"b": ["e", "g"],
"c": ["e", "h"],
"d": ["g"],
"e": ["d"],
"f": ["g", "h"],
"g": [],
"h": ["e", "i"],
"i": ["f"]}
print(get_path_with_for('h', 'g', map2, []))
['h', 'e', 'd', 'g']
Python som verktyg för kognitionsvetare?¶
- Artificiell intelligens: maskininlärning, kunskapsrepresentation, programmera robotar
- Lingvistik: språkteknologiska tillämpningar, korpuslingvistik
- Psykologi: utforska data, räkna statistik, visualisera data
- Människa-Maskin-interaktion: UX, interaktionsprogrammering
- Neurovetenskap: simulering, modellering, processa t.ex. fMRI-bilder
- Allmänt: automatisering, databearbetning, kognitionsvetenskapliga experiment, webbtjänster, IoT m.m.
Pythonpaket¶
- Pythonpaket tillhandahåller moduler som innehåller funktionalitet som inte finns med i Python "från början"
- Importeras på samma sätt som inbyggda moduler som
math,randomochos
Pythonpaket, exempel¶
pycodestyleochpyflakes: kontrollera pythonkod för fel och stilbrottrequests: enklare (att använda) HTTP-requests (kommunikation med webbservrar)beautifulsoup: paket för hantering av HTML och XML (t.ex. extrahera information från webben)matplotlib: datavisualiseringNumPy,SciPyochpandas: databeararbetning och -analys (statistik, linjär algebra, m.m.)NLTK: naturligt språkbehandlingDjangoochFlask: två ramverk för webbutveckling
Kort om att installera paket¶
- Kommandot
pip - I LiUs Linuxmiljö får användare inte installera paket på systemnivå.
- För att installera paket på kan vi använda modulen venv för att skapa en virtuell miljö som vi kan aktivera och sedan installera paket i.
Filosofin bakom Unix¶
- Summerat av Peter H. Salus (1994)
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
- Det vill säga
- Genom att skriva program som kan ta in text som input och ger text som output, kan man använda olika program med varandra genom att använda ett programs output som input till ett annat program.
- Genom att skriva program som endast gör en sak, så får vi byggstenar som vi kan använda efter våra behov.
Standard input, standard output, standard error¶
- Skalet hanterar input och output som strömmar (tänk kanaler/slangar/rör).
- Skalet kan omdirigera information som ett program skickar till stdout (standard output) så att det används som input till ett annat program.


Omdirigeringstecken¶
- Exempel på verktyg för detta, omdirigeringstecken
>skicka utdata från program (via stdout) till fil>>skicka utdata från program (via stdout) till slutet på en fil<skicka innehåll i fil till program via standard input|skicka utdata från ett program som indata till annat program ("att pipe:a")
Några exempel¶
sort- sorterar de rader den fåruniq- tar bort dublettercut- plocka fram text från t.ex. en viss kolumngrep- leta efter rader som innehåller specificerad textseq- skriv ut en sekvens av siffrorFler exempel: https://developer.ibm.com/articles/au-unixtext/
Mönster i sökvägar i Unix¶
*betyder 0 eller fler godtyckliga tecken?betyder exakt ett godyckligt tecken- Exempel
ls *.pyvisa alla filer som slutar på.pycp data/*.csv csvfiler/kopiera alla filer vars namn slutar på .csv från katalogen data till katalogencsvfiler(givet attcsvfilerär en katalog)cat sub1?.jsonskriv ut innehållet i alla filer med namn som börjar påsub1följt av ett godtyckligt tecken följt av.json
Exekverbara filer i Unix¶
Exekverbara textfiler i Unix¶
- Filen måste ha körrättighet
chmod u+x filnamn
- Första raden i filen ska peka ut den tolk som ska användas för att tolka resten av textfilen.
- För Python 3 (pythonkod), t.ex.:
#!/usr/bin/env python3
- För bash (skalkommandon), t.ex.:
#!/bin/bash
Pythonprogram som tar emot argument¶
- importera modulen
sys - variabeln
sys.argvär en lista som innehåller allt som skrevs på kommandoraden (mellanslag som skiljetecken) - Exempel
$ ./greetings.py Ada Bertil Caesarsys.argv→['./greetings.py', 'Ada', 'Bertil', 'Caesar']
Enklare formattering av strängar¶
- f-strängar, en sträng med f som prefix
f"Jag är en f-sträng"
- Kan innhålla uttryck innanför måsvingar,
{}, som beräknas när strängen skapas. - Exempel:
namn = "Guido"
print(f"Hej {namn}!")
'Hej Guido!'
print(f"Jag vet att svaret är {21*2}")
'Jag vet att svaret är 42'
Smidig utskrift av variabler¶
Lägg till
=efter ett uttryck inom{}i en f-sträng, så följer även själva uttrycket med när strängen skapas.Exempel:
my_value = 123
print(f"{my_value=}")
my_value=123
print(f"{40+2=}")
40+2=42
print(f"{my_value/2=}")
my_value/2=61.5
Exempel, argv_demo.py¶
#!/usr/bin/env python3
import sys
print(f"{sys.argv=}")
index = 0
while index < len(sys.argv):
print(f"Argument {index}: {sys.argv[index]}")
index += 1
$ python3 argv_demo.py apelsin banan citron sys.argv=['argv_demo.py', 'apelsin', 'banan', 'citron'] Argument 0: argv_demo.py Argument 1: apelsin Argument 2: banan Argument 3: citron
Pythonprogram som läser från stdin¶
- importera modulen
sys - läs rad för rad från
stdin:
for line in sys.stdin:
print(line)
linekommer vara en sträng
Exempel, find.py¶
"""
Exempelanvändning som visar alla rader som innehåller ordet glass
# med pipe från ett annat program:
$ cat alice.txt | python3 find.py glass
# direkt från fil:
$ python3 find.py glass < alice.txt
"""
import sys
# för varje rad som fås via standard input (t.ex. från en pipe)
for line in sys.stdin:
# om raden innehåller första argumentet som pythonprogrammet får
if sys.argv[1].lower() in line.lower():
# skriv ut raden
print(line.strip())
$ cat alice.txt | python3 find.py glass solid glass; there was nothing on it except a tiny golden key, quite plainly through the glass, and she tried her best to climb Soon her eye fell on a little glass box that was lying under again, and the little golden key was lying on the glass table as swim in the pool, and the great hall, with the glass table and glass. There was no label this time with the words `DRINK ME,' and a crash of broken glass, from which she concluded that it was Come and help me out of THIS!' (Sounds of more broken glass.) sounds of broken glass. `What a number of cucumber-frames there little glass table. `Now, I'll manage better this time,'
Moduler i Python¶
Moduler¶
- Moduler tillhandahåller ytterligare funktioner m.m.
- Exempel:
random,sys,json,pickle - Vi kan använda de filer vi skriver som egna moduler
Importera en modul¶
import <modulnamn><modulnamn>används som prefix för att komma åt funktionalitet i modul
import <modulnamn> as <alias><alias>används som prefix för att komma åt funktionalitet i modul
from modulnamn import <namn_på_något_i_modulen>- importera
<namn_på_något_i_modulen>direkt till den egna namnrymden (inget prefix behövs)
- importera
from <modulnamn> import *- importera allt från
<modulnamn>till den egna namnrymden
- importera allt från
OBS! En import-sats per modul räcker. Samla alla importer högst upp i er fil.
Exempel - olika sätt att referera till funktion i en modul beroende på hur den importerats¶
# funktioner.py
print("Nu laddas funktionerna in.")
def print_twice(message):
message = message.rstrip()
print("1:", message)
print("2:", message)
print("Funktionerna har laddats.")
if __name__ == "__main__":
print("funktioner.py är \"huvudprogram\". __name__:", repr(__name__))
else:
print("funktioner.py laddas in som en modul. __name__:", repr(__name__))
Nu laddas funktionerna in. Funktionerna har laddats. funktioner.py är "huvudprogram". __name__: '__main__'
Importera modulen med sin vanliga namnrymd¶
# program1.py ##################################
# importera innehållet från filen funktioner.py
# lägger sig under modulnamnet funktioner
import funktioner
funktioner.print_twice("hejsan!")
1: hejsan! 2: hejsan!
Importera modulen till en lokal namnrymd som vi döper själva¶
from IPython.core.display import HTML
HTML("<script>Jupyter.notebook.kernel.restart()</script>")
# program2.py ##################################
# importera innehållet från filen funktioner.py
# lägger sig under modulnamnet f
import funktioner as f
f.print_twice("hejsan!")
Nu laddas funktionerna in. Funktionerna har laddats. funktioner.py laddas in som en modul. __name__: 'funktioner' 1: hejsan! 2: hejsan!
Importera allt i modulen till den lokala namnrymden¶
from IPython.core.display import HTML
HTML("<script>Jupyter.notebook.kernel.restart()</script>")
# program3.py ##################################
# importera innehållet från filen funktioner.py
# lägger sig i den nuvarande namnrymnden
from funktioner import *
print_twice("hejsan!")
Nu laddas funktionerna in. Funktionerna har laddats. funktioner.py laddas in som en modul. __name__: 'funktioner' 1: hejsan! 2: hejsan!
Kod som körs när något läses in som modul¶
- Vid import körs koden som står i modulen
- Vi kan ta reda på om koden körs som "huvudprogram" eller om den importeras.
- Systemvariabeln
__name__innehåller en sträng med den namnrymd (namespace) som gäller. - Om programmet körs som huvudprogram gäller
__name__ == "__main__" - Dvs, vi kan skriva kod som endast kör när filen körs som huvudprogram, t.ex. tester
# funktioner.py
print("Nu laddas funktionerna in.")
def print_twice(message):
message = message.rstrip()
print("1:", message)
print("2:", message)
print("Funktionerna har laddats.")
if __name__ == "__main__":
print("funktioner.py är \"huvudprogram\". __name__:", repr(__name__))
else:
print("funktioner.py laddas in som en modul. __name__:", repr(__name__))
Några varningar¶
- Att importera kan överskugga variabler och funktioner
- Speciellt riskabelt är det att importera allt i en modul till den lokala namnrymden, dvs att köra
from min_modul import *
- Om
min_modulinnehåller t.ex. en funktion som heterprintså kommer vi inte längre åt den vanligaprint-funktionen
- En modul kan bara importeras EN gång
- Om vi kör
import min_modul, och sedan gör ändringar imin_modul, så kan vi inte få tillgång till dessa ändringar i en pågående Python-session (t.ex. när vi kör i interactive mode) genom att köraimport min_moduligen. - Lösning 1: Starta om Python.
- Lösning 2: Använd funktionen
reloadfrån den inbyggda modulenimportlib
- Om vi kör