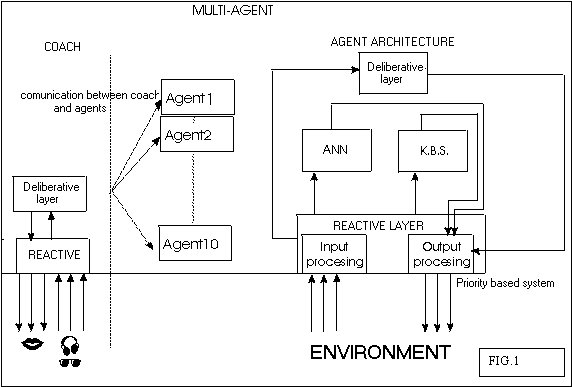
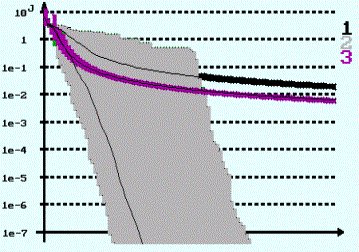
The proposed way of modifying the learning rate r is:
À
Compute
an initial r and set i =1. J0 available
from previous iteration.
À
Compute
the weights' variation Dw using the conjugate
gradients with restart formula
compute the weights w = wk + rÎDw
using w determine J1
À
Ifá J1<J0á
Repeat
i = i + 1
compute the weights w = wk + (rÎui)ÎDw
using w determine Ji
Until Ji>Ji-1
wk+1:=wk+(rÎui-1) ÎDw
Elseáááááá Repeat
i = i + 1
compute the weights w = wk + (r/ui)ÎDw
using w determine Ji
Until Ji<J0
wk+1 = wk +
(r/ui)Îw
À
proceed
to the next iteration.
The ui array may be the 2's powers array
(ui=2i), but we prefer the Fibonacci array (1,1,2,3,5,8,
.. i.e. ui=ui-1+ui-2) for its good results
proved on the optimization theory.
The initial choosing ofr at each iteration is very
important: 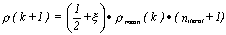
which r should be large enough to
exit local minimums, but not too large to avoid repeating, at each iteration,
the same step decreasing procedure. On simulations, we used the formula given
in the equation. r is an uniform random number
within (0,1), niterat counts for how many iterations does the
criterion J decrease with less than 1ë and rmean is the arithmetic mean of r's values for the last 10
iterations (too large or too small values being eliminated). At the beginning
of the learning process, rmean is 0.1.