
| Overview | Publications | Download | License | Getting started | Ongoing Work | Contact | Acknowledgments |
Scheduling algorithms published in the scientific literature are often difficult to evaluate or compare due to differences between the experimental evaluations in any two papers on the topic. Very few researchers share the details about the scheduling problem instances they use in their evaluation section, the code that allows them to transform the numbers they collect into the results and graphs they show, nor the raw data produced in their experiments. Also, many scheduling algorithms published are not tested against a real processor architecture to evaluate their efficiency in a realistic setting. Also, running experiments is a tedious and repetitive process prone to errors if performed manually. Mimer proposes an automated process to test schedulers or energy models used to evaluate their efficiency. Mimer produces easy to share raw and structured data using data analyser designed by researchers. This makes possible the sharing of precise experimental results as well as the precise way it has been processed to produce figures published in research papers, thus enabling fair comparisons between techniques. When researchers choose to share the source code of schedulers or schedule evaluators they design, Mimer can help considerably at reproducing experiments.
This page provides information about the Mimer structure, data format and workflow, as well as instructions to install, run and extend Mimer with additional schedulers and evaluators. Section overview gives a brief overview of Mimer. Section publications gives publications details related to Mimer or our work using Mimer. Section download gives downloading links of every important piece of software to use Mimer. Section licence gives details about the publication licence of the Mimer toolchain. Section structure gives details about the structure of Mimer, the format of the data is handles as well as its global workflow. Section getting started gives detailed instructions to install and run Mimer. Section Mimer experiment gives details on how to design and run a scheduling experiment with Mimer. Section design Mimer scheduler gives the required instructions to build a scheduler that can be integrated in Mimer's workflow. Section design Mimer evaluator gives necessary details to create a schedule evaluator suitable for Mimer. Finally, section design Mimer analysis gives necessary details to create a schedule evaluator suitable for Mimer.
Main features:
Mimer has been designed based on the observation that many scheduling-related experiments share a similar process. Researchers design and implement a new scheduling technique and define problems to assess the efficiency of their technique in a benchmark. The next steps often consists in using the new scheduler with each of the problem defined in the benchmark, possibly several times in order to obtain more reliable numbers in a later statistical analysis, or using varying scheduler parameters to deepen the study. This is the first step Mimer automatises; we denote it as the schedule step. The second step consists in assessing the quality of each schedule generated by schedulers tested in the schedule step. Such evaluation solution typically runs either an energy evaluation model implemented in a analytical energy evaluator, or by running an application using the generated schedule on an actual processing platform and measure the energy consumed. We call this step assess in the workflow implemented in Mimer. Steps schedule and assess can produce various interesting data, such as the scheduler's optimization time, the success rate of schedulers within the set of problems the schedulers has to compute a solution for, if a scheduler's solution is valid, for instance regarding architectural constraints (shared memory, frequency or voltage islands for example). Mimer's analysis step consists in gathering all data produced in previous steps from raw outputs generated, as well as extracting features from each problem instance, for example the number of tasks scheduled of the number of cores it has been scheduled for. The final step consists in analysing all the data gather in the analyse step and transform it into a set of plots ready to be published in research papers.
Mimer is essentially built on Freja. Freja handles all the automation of schedule, assess and analyse steps, from experiment descriptions (see Section Mimer experiment). The core of Mimer has no other dependency, although the pelib helps considerably to design schedulers and evaluators able to read input problem data and produce suitable outputs. The reader can start with section getting started to install a working copy of Mimer as well as Crown scheduler implementations, simple analytical energy evaluators, the drake C streaming framework to run actual streaming application on actual platforms using user-defined static schedules, two streaming applications, mergesort and FFT (inspired from the FFT2 application of the Streamit Benchmark suite), as well as the data analyser used for our paper published in PARCO 2015.
Nicolas Melot, Johan Janzen, Christoph Kessler: Mimer and Schedeval: Comparison Tools for Static Schedulers and Streaming Applications on Concrete Manycore Architectures. Accepted for Eighth International Workshop on Parallel Programming Models and Systems Software for High-End Computing (P2S2) at ICPP, 2015. IEEE.
Nicolas Melot, Christoph Kessler and Joerg Keller: Improving Energy-Efficiency of Static Schedules by Core Consolidation and Switching Off Unused Cores. Accepted for publication at International Conference on Parallel Computing (ParCo), Edinburg, 2015.
[raw batch results 1] [raw batch results 2] [raw batch results 3]
Download Mimer input data package
Download crown schedulers sources
Download Drake pipelined merge application
Download Drake pipelined fft from streamit
Download Static-Dynamic-Busy evaluator
Download our analyser of PARCO2015 paper
All packages above are released under GPLv3 licence. Please contact Nicolas Melot (nicolas.melot@liu.se) to obtain another licence.
Figure 1 shows the overall workflow of Mimer. It includes 4 steps shown in green: schedule, assess, analyse and plot. Each step uses user-defined schedulers, evaluators or analysers, Mimer can be extended with the implementation of more schedulers, more accurate evaluators or more detailed analysers. Mimer runs scheduling experiments whose description is given in Section mimer experiment. It includes a list of streaming applications (otherwise called "taskgraph" as we use their task graph structure to compute schedules), a list of schedulers to test, a list of platform description for which a schedule must be computed, a list of evaluators able to give numerical evaluation of each schedule generated and an analyser able to extract, process and represent the data generated into publishable figures.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns
http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd">
<!-- Created by igraph -->
<key id="g_name" for="graph" attr.name="name" attr.type="string"/>
<key id="g_label" for="graph" attr.name="label" attr.type="string"/>
<key id="g_deadline" for="graph" attr.name="deadline" attr.type="string"/>
<key id="v_name" for="node" attr.name="name" attr.type="string"/>
<key id="v_module" for="node" attr.name="module" attr.type="string"/>
<key id="v_workload" for="node" attr.name="workload" attr.type="double"/>
<key id="v_max_width" for="node" attr.name="max_width" attr.type="string"/>
<key id="v_efficiency" for="node" attr.name="efficiency" attr.type="string"/>
<graph id="G" edgedefault="directed">
<data key="g_name">pingpong</data>
<data key="g_deadline">0</data>
<node id="n0">
<data key="v_name">ping</data>
<data key="v_module">ping</data>
<data key="v_workload">1</data>
<data key="v_max_width">1</data>
<data key="v_efficiency">exprtk: p == 1 ? 1 : 1e-6</data>
</node>
<node id="n1">
<data key="v_name">pong</data>
<data key="v_module">pong</data>
<data key="v_workload">1</data>
<data key="v_max_width">1</data>
<data key="v_efficiency">exprtk: p == 1 ? 1 : 1e-6</data>
</node>
<edge id="e0" source="n0" target="n1"/>
<edge id="e1" source="n1" target="n0"/>
</graph>
</graphml>
The file is divided in 3 main parts. The first part is the XML header of the GraphML file and should be the same for all taskgraph files. The second part declares properties of the graph, its vertices and edges that are specific to Mimer's use of GraphML to express taskgraphs. Among the graph properties:
A platform is described in AMPL input format (see chapter 4 of the AMPL book). Scalar p represents the number of identical sequential processor in the platform, and F is the set of frequency, in KHz, each core can run at. The snippet belows shows the description of an abstract platform that consits of 4 cores running at frequencies 1 2 3 4 or 5 (the frequency doesn't matter for an abstract platform; the reader can consider KHz for the sake of consistency with Drake). Finally, the scalar string "platform_label" gives a human-readable very short description label of the platform.
# Human-readable label param platform_label = "4"; # Number of cores param p := 4; # Frequency levels set F := 1 2 3 4 5;
A Schedule for Mimer is a XML document that gives. Each core in the schedule is represented by a top-level element and identified by its property "coreid". Each core holds a sequence of tasks to execute. If several cores run a common task, this means that the tasks runs in parallel using all these cores. Each task is identified by its name as given in the corresponding taskgraph. Further properties of a task include its starting time, relative to the beginning time of a pipeline stage, a frequency in KHz the task runs at, a width that express the number of cores that run this task and a workload. The workload of a task in a schedule is lower or equal to the workload of the corresponding task in the corresponding taskgraph. It represents the portion of the workload that the task must achieve when the corresponding task work function runs. If with is higher than one, the workload is shared among all cores that run the task. If workload is lower than the corresponding workload in taskgraph, then the task must appear at least one more time in the schedule, possibly run by another set of processors. This allows the scheduling of preemptive or malleable tasks.
<?xml version="1.0" encoding="UTF-8"?> <schedule name="Generated from Algebra" appname="Generated from Algebra"> <core coreid="1"> <task name="ping" start="0.000000" frequency="800000.000000" width="1.000000" workload="1.000000"/> </core> <core coreid="2"> <task name="pong" start="0.000000" frequency="800000.000000" width="1.000000" workload="1.000000"/> </core> </schedule>
Instructions get started with Mimer are enclosed in this extensively commented script. It includes downloading, compiling and running drake and its dependencies, target platform implementations, streaming applications as well as a simple scheduling experiment for Mimer. The procedure has been tested on a fresh install of Debian 8 "Jessie"; you can apply the instructions in this virtual machine or simply run the script and monitor the process.
curl http://www.ida.liu.se/labs/pelab/mimer/download/mimer-install.sh | bash
The virtual machine needs an access to internet in order to download all packages required. It also needs an internal virtual network so that the user can use a terminal to connect to the virtual machine and operate it through ssh. If all requirements are met, the virtual machine gives instructions on how to use ssh to open a session. Below are instructions to setup the internal virtual network required using virtual box v5.0.24_Ubuntu r108355 on Ubuntu 16.04.1 (Xenial).
After importing the virtual machine into virtual box and starting it, you may find the following error message:
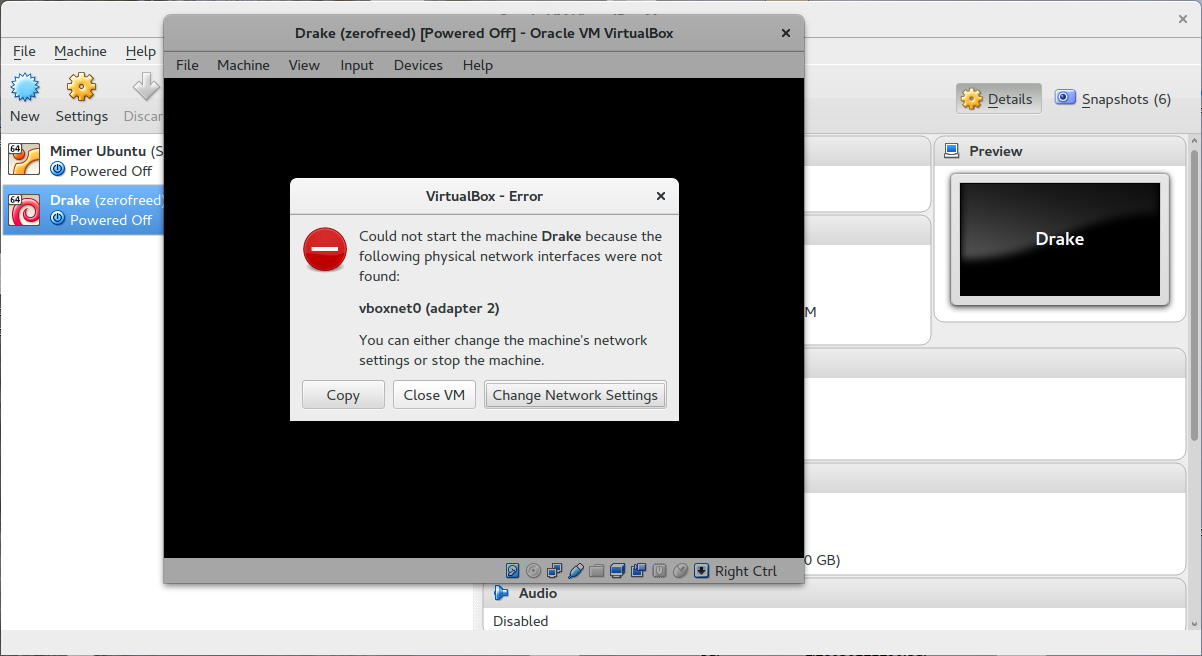
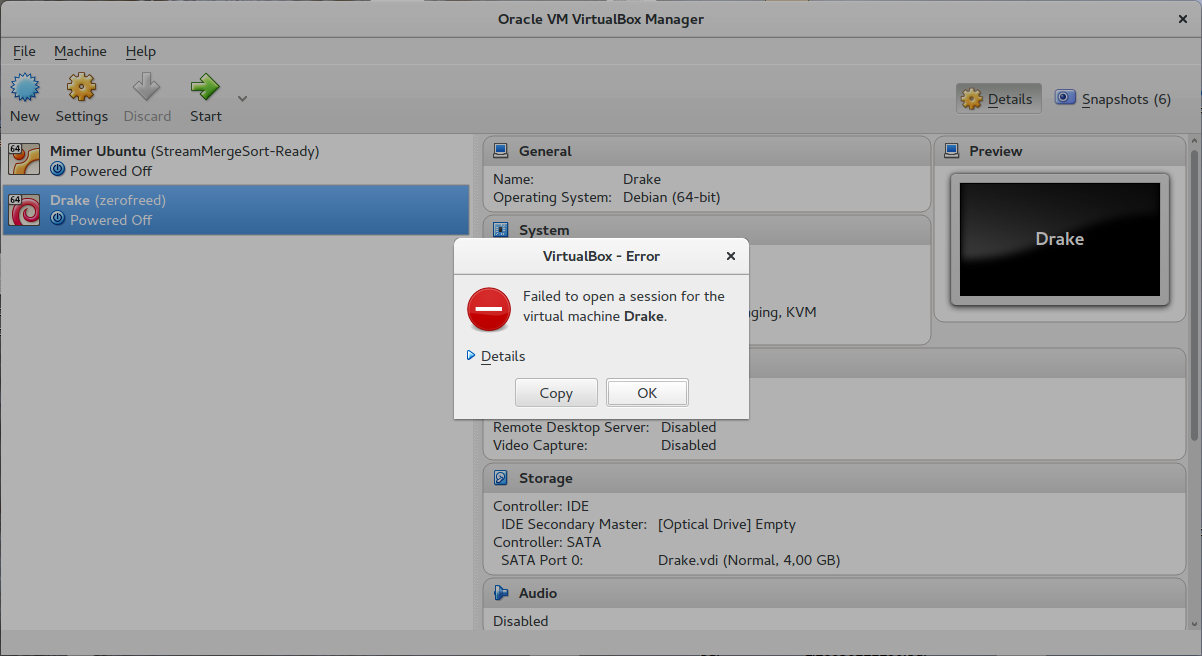
Click on "Close VM" then you might see this message; click "OK":
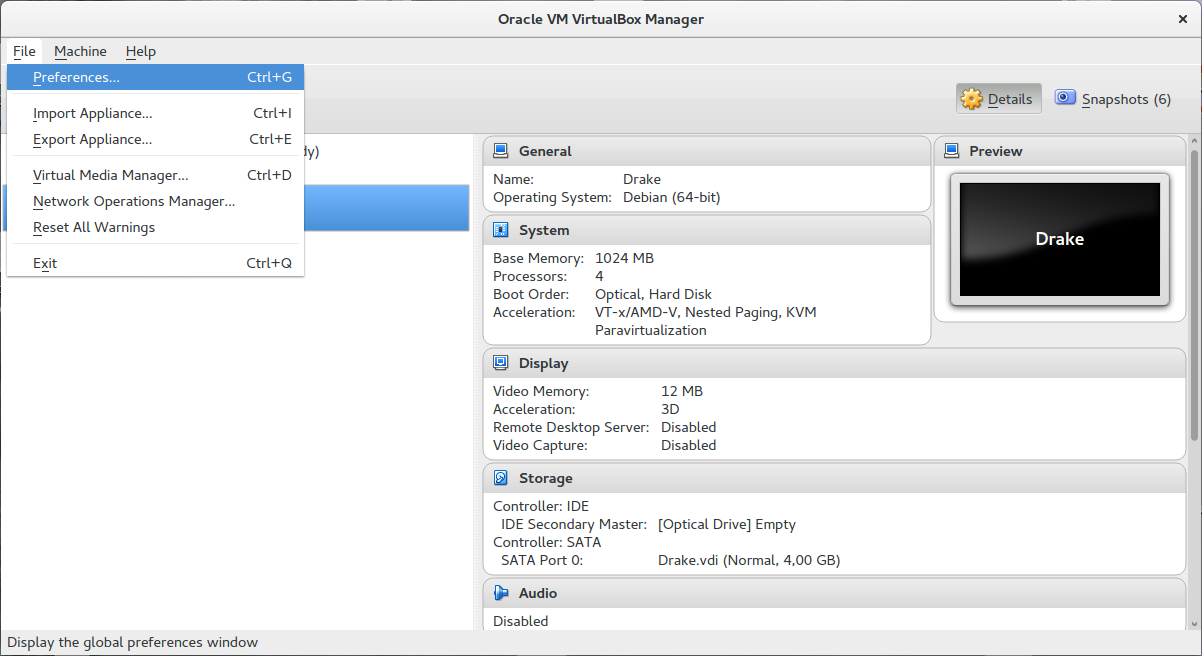
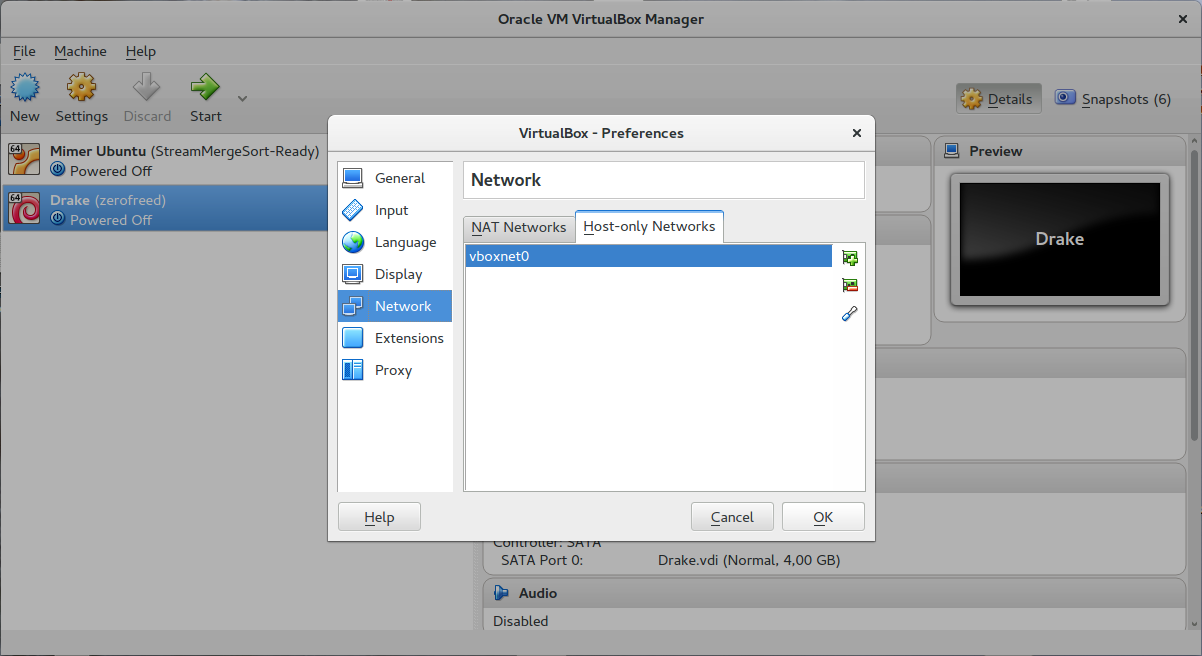
In order to add the virtual network, find "preference" in main menu "File":
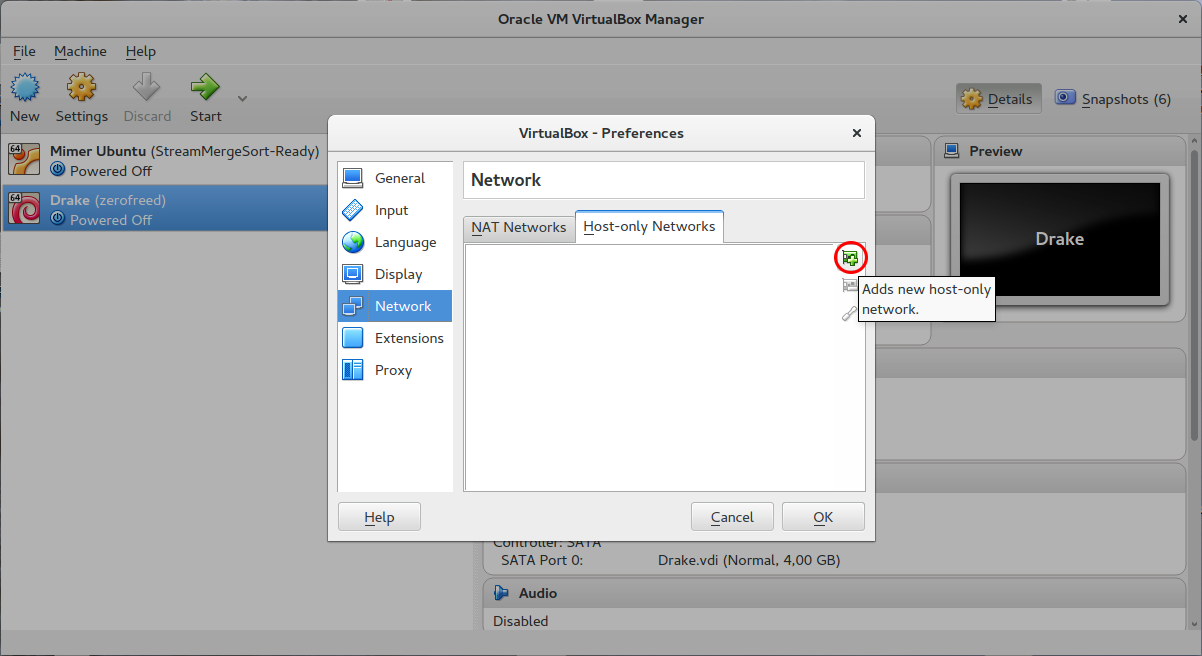
Then, in section "Network" and tab "Host-only Networks", see that there is no element named "vboxnet0" in the list. If it exists, then the problem shown above might have other causes we do not cover. Otherwise, click the button "Adds new host-only network.".
The new network should be named "vboxnet0"; click "OK":
The virtual machine should now run correctly.
Mimer experiments are described in an experiment file (otherwise denoted as batch file) as shown below. The lines are structured in variable="values" pattern. Note the absence of space between the variables and its values: this is because Freja uses bash to load batch files, therefore batch files should comply with bash syntax. Valid variables include platform, scheduler, evaluation, analysis as well as schedule_try and evaluation_try. Values defined for each variable are space-separated. Freja execute one run for each possible combinations of these 6 variables.
platform="scc_8.dat scc_32.dat" taskgraph="fft2_streamit_loose fft2_streamit_tight" scheduler="crown_ltlg_height crown_binary_ltlg_height" evaluation="static_dynamic_busy drake_eval_scc_emulator" analysis="parco2015-nmelot" ## Repeat each scheduling or energy experiment to smooth irregularities ## Repeat scheduler execution schedule_try="`seq 1 1`" ## Repeat energy measurement execution evaluation_try="`seq 1 1`" ## File naming restrictions; # * No colon ":": separator in scripts # * No comma ",": AMPL use as item separator in lists) ## Options for schedulers ## Options for evaluators drake_eval_scc_emulator="drake_eval_scc --emulator" static_dynamic_busy="static_dynamic_busy --alpha 3 --zeta 1 --epsilon 0.5 --kappa 1 --eta 0.1" ## Options for taskgraphs fft2_streamit_loose="fft2_streamit-1.0.0.tar.gz --work-unit 1 --rounds 0 --time 10000" fft2_streamit_tight="fft2_streamit-1.0.0.tar.gz --work-unit 1 --rounds 0 --time 10000"Below is a detailed description for each variable:
Mimer runs scheduler in the scheduling step of its process (schedule). A Mimer scheduler is a self-sufficient executable that takes a taskgraph and a platform description in input and produces a schedule as output. Taskgraphs are expressed as a text file in GraphML format with relevant application information, Platform descriptions are in AMPL input data format and schedules in XML (see Section format for more information). It may produce additional data to be processed in a scheduling study, such as its optimization time in key = value format. This is the imost simple command to run the scheduler "crown_ltlg_height":
crown_ltlg_height --taskgraph /path/to/taskgraph.graphml --platform /path/to/platform.dat
The command above generates the XML schedule file /tmp/crown_ltlg_height.schedule; note that the schedule file generated is named after the scheduler. If the scheduler alters the taskgraph given in input, the modified taskgraph is stored in /tmp under the same filename as the taskgraph given in input. If the scheduler doesn't alter the input taskgraph, then the corresponding output taskgraph is a copy of the input taskgraph. You can specify the filenames for output schedules and taskgraphs, using switches --schedule-output /path/to/output/schedule.schedule and --taskgraph-output /path/to/output/taskgraph.graphml. If any of the schedule or taskgraph output files is not produced, then mimer considers that the scheduler is unable to compute a correct schedule for the problem instance.
The command above produces the standard output below. Each line represents a value that can be interesting for a scheduling study. Note that the names associated to each value may be misleading. We give a short description of the data displayed here:
optimal = 0 feasible = 1 complexity = 104.476620 time_allocation = 0.000018 time_mapping = 0.000014 time_frequency = 0.000005 time_global = 0.000037 quality_mapping = 1.428571
Non-deterministic schedulers (for instance based on randomness to solve the problem) may produce different outputs or behave differently while running. In order to capture behavior variations, it is common that Mimer runs a scheduler with the same problem input several times. However, if the scheduler is deterministic, this can result in a substancial additional experimentation time for little interest. This can be avoided using the switches --taskgraph-solution /pat/to/solution/taskgraph.graphml, --schedule-solution /path/to/solution/schedule.schedule and --output-solution /path/to/solution/output, that provides the scheduler with the taskgraph, scheduler and standard output it produced in a previous run with the same input problem. The scheduler can copy these solution to the corresponding taskgraph, scheduler and standard output to accelerate the experiment, or it may compute again the solution.
A scheduler can be designed to accept more custom switches to alter its behavior. Such switches should be given in the experiment description file. However, it is important that every scheduler variation is clearly identified in the final figures Mimer generates. Mimer calls each scheduler with the switch --label as well as all other options given in the experiment files. The scheduler should write on standard output a unique human-friendly description of itself to appear in figures's legend without solving any problem instance. In particular, this description must take into account all addition options given to the scheduler and that may alter its behavior. For example, the command
crown_binary --taskgraph ~/mimer-data/taskgraph/fft_n3_1.graphml --platform ~/mimer-data/platform/p4.dat --labelproduces the output
Bin,LTLG,Height(a=3,z=0.1,e=0.5)and the command
crown_binary --taskgraph ~/mimer-data/taskgraph/fft_n3_1.graphml --platform ~/mimer-data/platform/p4.dat --label --alpha 2.6 --zeta 50 --epsilon 2produces the output
Bin,LTLG,Height(a=2.6,z=50,e=2)
This is the list of all switches a Mimer scheduler must accept:
Mimer uses schedule evaluators in the assessment step (assess). A mimer evaluator is a self-sufficient executable that takes a taskgraph description as input (in the form of a text file in GraphML format or as a Drake application source package), a platform description in AMPL input format and a schedule in XML format, and produces output in AMPL output format, denoting properties of the schedule such as its projected or measured energy consumption or its correctness regarding the platform constraint. This is a correct minimal command to run a Mimer evaluator (here "static_dynamic_busy"):
static_dynamic_busy --taskgraph /tmp/fft_n3_1.graphml --platform ~/mimer-data/platform/p4.dat --schedule /tmp/crown_ltlg_height.scheduleThis command produces the output
time__power [*,*] : 0 1 := 0 0.000000 92.084999 1 1.000000 92.084999 ; switching = 14 switching_energy = 0.02 valid_schedule = 1The matrix "time__power" denotes the projected power consumption of the streaming application with the given schedule over time. The integration of the curve gives the overall energy consumption. Note the the name of the power consumption matrix. It gives the name of the columns, separated by a double underscore character ("__"). Here, the first column is called "time" and represents the time in seconds while the second column named "power" denotes the power in Watts measured or estimated at the corresponding time. The three foloowing lines are show for illustration. "switching" counts the number of frequency switching necessary for each pipeline round. "switching energy" counts the energy part spent in switching frequency, due to delays is occurs. Finally, "valid_schedule" takes value 1 if the schedule is valid regarding the platform constraints and 0 otherwise.
Several custom switches can alter the behavior of a schedule evaluator. However, the final figures generated by Mimer must reflect the behavior differences. Mimer calls evaluator with the switch --label as well as all custom switches defined in the experiment description file. When the --label switch is employed, the evaluator must write a very short human-friendly description about itself, including any variation due to other custom switches and not evaluate any schedule that may (or may not) be given.
If the evaluator doesn't project the power consumption but measures it on a real architecture and if the taskgraph given as input is a drake source package, then the switch --args allows the definition of custom arguments to give the application. This inlude for instance input data to be processed. The arguments passed to the application begins with the immediate argument following --args and finishes either at the end of the command line or when an argument consisting of two dashes (--) is found.
This is the list of all switches a Mimer evaluator must accept
Mimer uses an analyser in the steps analyse and plot. A Mimer analyser is a self-sufficient bash script that both inspects output produced by schedulers and evaluators in scheduling and assessment steps (schedule and assess) and look for data identified by their key, or they analyse each problem instance run in the previous steps to extract properties about the problem. This can be the number of tasks scheduled or the average maximal width of the tasks in the application. In the following, we assume the analyser is "parco2015-nmelot".
In the analysis step (analyse), Mimer first sources the analyser with the command
. parco205-nmelot --settingsThis constraints an analyser, or at least a frontend of the analyser, to be written in bash. Mimer expects the analyser to define the environment variables scheduler_scalars and scheduler_scalars as a space-separated list of scalar values to be read from the schedulers and evaluators' standard outputs, repsectively (see sections design Mimer scheduler and design Mimer evaluator). Additionally, the variables evaluation_matrix defines a unique matrix to be read from evaluator's standard outputs.
parco205-nmelot --analyse --taskgraph /path/to/taskgraph/description.graphml --platform /path/to/platform.dat --schedule /path/to/schedule.scheduleto extract useful information about the problem instance, such as the number of tasks. Here is a typical output (standard output) of such a call:
n = 3 max_width_stddev = 0.471405 max_width_mean = 1.333333 work_stddev = 0.471405 application = fftHere, the analyse counts a problem instance of 3 tasks (n = 3), of mean maximal width 4/3 (max_width_mean = 1.333333) with standard deviation 0.47 (max_width_stddev = 0.471405) and the application solving the Fast Fourrier Transform (application = fft).
At the plot step of Mimer's workflow, Mimer also calls the analyser as
parco205-nmelot --plot --batch /path/to/mimer/experiment/descriptionwhich commands the analyser to generate plots from the data generated in previous steps and svae them in the current directory. The switch --batch gives the experiment description files the analyzer is required to generate figures for. The nalyzer can find a text file in Comma-Separated-Values (csv) in $HOME/.mimer/cache/analyse/parco2015-nmelot/table.csv. Also, the file "labels.r" generated in the analysis step contains the R function apply_labels(data.frame, labels.list = labels) that returns the dataframe given as input where all levels in columns that appear in labels.list (provided by default in the same file) are replaced by a human-readable label. This R script is generated by Mimer from the values obtained from schedulers and evaluators thanks to the --labels switches.
Future work includes the design of a streaming applications microbenchmark step in Mimer's process to obtain numbers describing tasks more accurately, depending on the target platform, so that schedulers can produce better quality schedules. We plan to replace the platform AMPL representation with a more complete description language such as XPDL.
If you would like to contribute, please let us know.
For reporting bugs, please email to "<firstname> DOT <lastname> AT liu DOT se".
This work was partly funded by the EU FP7 project EXCESS and by SeRC project OpCoReS.
 |
 |

|